Pendahuluan
Apache Storm dan Spark adalah platform untuk pemrosesan data besar yang bekerja dengan aliran data waktu nyata. Perbedaan inti antara kedua teknologi adalah cara mereka menangani pemrosesan data. Storm memparalelkan komputasi tugas sementara Spark memparalelkan komputasi data. Namun, ada perbedaan mendasar lainnya antara API.
Artikel ini memberikan perbandingan mendalam antara Apache Storm vs. Spark Streaming.

Storm vs. Spark:Definisi
Apache Badai adalah kerangka pemrosesan aliran waktu nyata. Trisula lapisan abstraksi menyediakan Storm dengan antarmuka alternatif, menambahkan operasi analitik real-time.
Di sisi lain, Apache Spark adalah kerangka kerja analitik tujuan umum untuk data skala besar. Spark Streaming API tersedia untuk streaming data hampir secara real-time, bersama dengan alat analitik lainnya dalam framework.
Storm vs. Spark:Perbandingan
Baik Storm dan Spark adalah proyek Apache yang bebas digunakan dan open-source dengan maksud yang sama. Tabel di bawah ini menjelaskan perbedaan utama antara kedua teknologi tersebut:
| Badai | Spark | |
|---|---|---|
| Bahasa Pemrograman | Integrasi multi-bahasa | Dukungan untuk Python, R, Java, Scala |
| Model Pemrosesan | Pemrosesan streaming dengan micro-batching tersedia melalui Trident | Pemrosesan batch dengan micro-batching tersedia melalui Streaming |
| Primitif | Aliran Tuple Kumpulan tupel Partisi | DStream |
| Keandalan | Tepat sekali (Trident) Setidaknya sekali Paling banyak sekali | Tepat sekali |
| Toleransi Kesalahan | Mulai ulang otomatis oleh proses supervisor | Pekerja memulai ulang melalui pengelola sumber daya |
| Pengelolaan Negara | Didukung melalui Trident | Didukung melalui Streaming |
| Kemudahan Penggunaan | Lebih sulit dioperasikan dan disebarkan | Lebih mudah dikelola dan diterapkan |
Bahasa Pemrograman
Ketersediaan integrasi dengan bahasa pemrograman lain adalah salah satu faktor utama saat memilih antara Storm dan Spark dan salah satu perbedaan utama antara kedua teknologi.
Badai
Storm memiliki multibahasa fitur, membuatnya tersedia untuk hampir semua bahasa pemrograman. API Trident untuk streaming dan pemrosesan kompatibel dengan:
- Jawa
- Clojure
- Skala
Percikan
Spark menyediakan API Streaming tingkat tinggi untuk bahasa berikut:
- Jawa
- Skala
- Python
Beberapa fitur lanjutan, seperti streaming dari sumber khusus, tidak tersedia untuk Python. Namun, streaming dari sumber eksternal lanjutan seperti Kafka atau Kinesis tersedia untuk ketiga bahasa tersebut.
Model Pemrosesan
Model pemrosesan mendefinisikan bagaimana streaming data diaktualisasikan. Informasi diproses dengan salah satu cara berikut:
- Satu rekaman pada satu waktu.
- Dalam kelompok terpisah.
Badai
Model pemrosesan inti Storm beroperasi pada aliran tuple secara langsung, satu catatan pada satu waktu , menjadikannya teknologi streaming real-time yang tepat. API Trident menambahkan opsi untuk menggunakan mikro-batch .
Percikan
Model pemrosesan Spark membagi data menjadi batch , mengelompokkan record sebelum diproses lebih lanjut. Spark Streaming API menyediakan opsi untuk membagi data menjadi mikro-batch .
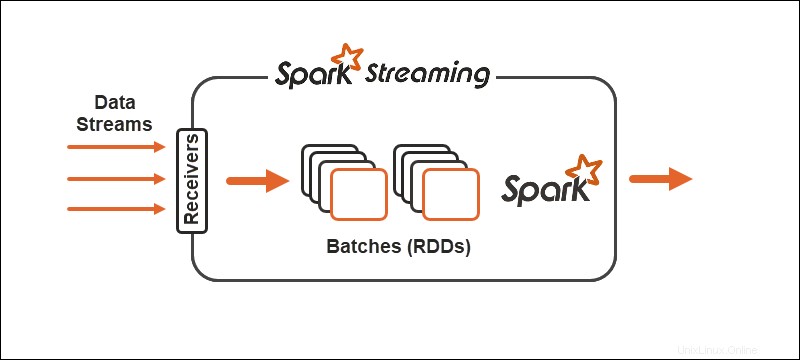
Primitif
Primitif mewakili blok bangunan dasar dari kedua teknologi dan cara operasi transformasi dijalankan pada data.
Badai
Core Storm beroperasi pada aliran tuple , sementara Trident beroperasi pada batch tuple dan partisi . API Trident bekerja pada koleksi dengan cara yang mirip dengan abstraksi tingkat tinggi untuk Hadoop. Primitif utama Storm adalah:
- Semprot yang menghasilkan aliran waktu nyata dari sumber.
- Baut yang melakukan pemrosesan data dan menahan persistensi.
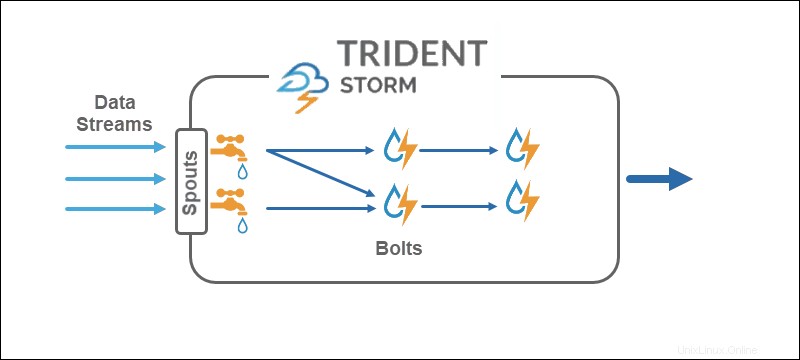
Dalam topologi Trident, operasi dikelompokkan menjadi baut. Kelompokkan, gabung, agregasi, jalankan fungsi, dan filter tersedia pada kumpulan yang terisolasi dan di seluruh koleksi yang berbeda. Agregasi menyimpan secara terus-menerus dalam memori yang didukung oleh HDFS atau di beberapa toko lain seperti Cassandra.
Percikan
Dengan Spark Streaming, aliran data yang berkelanjutan terbagi menjadi aliran yang didiskritkan (DStreams), urutan Database Terdistribusi Tangguh (RDD).
Spark memungkinkan dua jenis operator umum pada primitif:
1. Operator transformasi aliran di mana satu DStream berubah menjadi DStream lain.
2. Operator keluaran membantu menulis informasi ke sistem eksternal.
Keandalan
Keandalan mengacu pada jaminan pengiriman data. Ada tiga kemungkinan jaminan saat menangani keandalan streaming data:
- Setidaknya sekali . Pengiriman data satu kali, dengan kemungkinan pengiriman beberapa kali juga.
- Paling banyak sekali . Pengiriman data hanya sekali, dan duplikat apa pun akan hilang. Ada kemungkinan data tidak sampai.
- Tepat sekali . Data dikirimkan sekali, tanpa kehilangan atau duplikat. Opsi jaminan optimal untuk streaming data, meskipun sulit dicapai.
Badai
Storm fleksibel dalam hal keandalan streaming data. Pada intinya, setidaknya sekali dan paling banyak sekali pilihan adalah mungkin. Bersama dengan Trident API, ketiga konfigurasi tersedia .
Percikan
Spark mencoba mengambil rute optimal dengan berfokus pada tepat sekali konfigurasi aliran data. Jika seorang pekerja atau pengemudi gagal, setidaknya sekali semantik berlaku.
Toleransi Kesalahan
Toleransi kesalahan mendefinisikan perilaku teknologi streaming jika terjadi kegagalan. Baik Spark dan Storm toleran terhadap kesalahan pada tingkat yang sama.
Percikan
Jika terjadi kegagalan pekerja, Spark memulai ulang pekerja melalui manajer sumber daya, seperti BENANG. Kegagalan driver menggunakan pos pemeriksaan data untuk pemulihan.
Badai
Jika proses gagal di Storm atau Trident, proses pengawasan menangani restart secara otomatis. ZooKeeper memainkan peran penting dalam pemulihan dan pengelolaan negara.
Pengelolaan Negara
Baik Spark Streaming dan Storm Trident memiliki teknologi manajemen status bawaan. Pelacakan status membantu mencapai toleransi kesalahan serta jaminan pengiriman tepat satu kali.
Kemudahan Penggunaan dan Pengembangan
Kemudahan penggunaan dan pengembangan bergantung pada seberapa baik teknologi tersebut didokumentasikan dan seberapa mudah mengoperasikan streaming.
Percikan
Spark lebih mudah digunakan dan dikembangkan dari kedua teknologi tersebut. Streaming didokumentasikan dengan baik dan disebarkan di kluster Spark. Tugas aliran dapat dipertukarkan dengan tugas batch.
Badai
Storm sedikit lebih sulit untuk dikonfigurasi dan dikembangkan karena mengandung ketergantungan pada cluster ZooKeeper. Keuntungan saat menggunakan Storm adalah karena fitur multi-bahasa.
Storm vs. Spark:Bagaimana Memilih?
Pilihan antara Storm dan Spark tergantung pada proyek serta teknologi yang tersedia. Salah satu faktor utamanya adalah bahasa pemrograman dan jaminan keandalan pengiriman data.
Meskipun ada perbedaan antara kedua streaming dan pemrosesan data, jalur terbaik yang harus diambil adalah menguji kedua teknologi untuk melihat mana yang paling cocok untuk Anda dan aliran data yang ada.