Pendahuluan
Saat ini, kami memiliki banyak solusi gratis untuk pemrosesan data besar. Banyak perusahaan juga menawarkan fitur perusahaan khusus untuk melengkapi platform sumber terbuka.
Tren dimulai pada tahun 1999 dengan pengembangan Apache Lucene. Kerangka kerja segera menjadi open-source dan mengarah pada penciptaan Hadoop. Dua dari kerangka kerja pemrosesan data besar paling populer yang digunakan saat ini adalah open source – Apache Hadoop dan Apache Spark.
Selalu ada pertanyaan tentang kerangka kerja mana yang akan digunakan, Hadoop, atau Spark.
Dalam artikel ini, pelajari perbedaan utama antara Hadoop dan Spark dan kapan Anda harus memilih satu atau yang lain, atau menggunakannya bersama-sama.

Catatan :Sebelum membahas perbandingan langsung Hadoop vs. Spark, kita akan melihat sekilas kedua kerangka kerja ini.
Apa itu Hadoop?
Apache Hadoop adalah platform yang menangani kumpulan data besar secara terdistribusi. Kerangka kerja menggunakan MapReduce untuk membagi data menjadi blok dan menetapkan potongan ke node di seluruh cluster. MapReduce kemudian memproses data secara paralel pada setiap node untuk menghasilkan output yang unik.
Setiap mesin dalam cluster menyimpan dan memproses data. Hadoop menyimpan data ke disk menggunakan HDFS . Perangkat lunak ini menawarkan opsi skalabilitas tanpa batas. Anda dapat memulai dengan serendah satu mesin dan kemudian berkembang menjadi ribuan, menambahkan semua jenis perangkat keras perusahaan atau komoditas.
Ekosistem Hadoop sangat toleran terhadap kesalahan. Hadoop tidak bergantung pada perangkat keras untuk mencapai ketersediaan tinggi. Pada intinya, Hadoop dibangun untuk mencari kegagalan pada lapisan aplikasi. Dengan mereplikasi data di seluruh kluster, ketika suatu perangkat keras gagal, kerangka kerja dapat membangun bagian-bagian yang hilang dari lokasi lain.
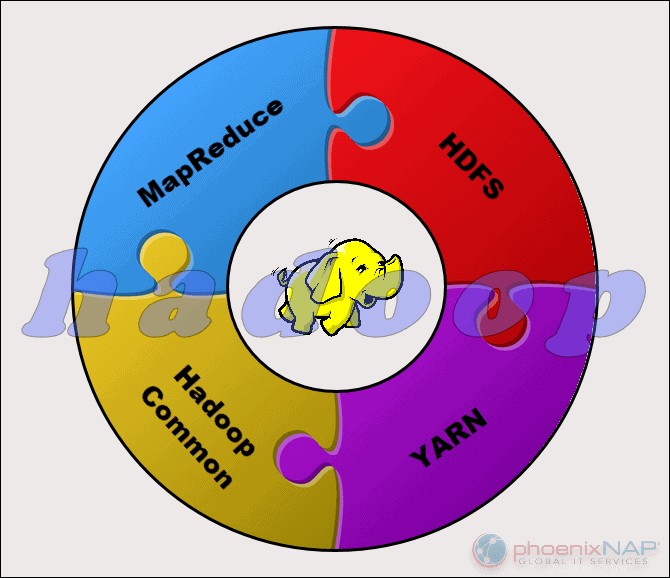
Proyek Apache Hadoop terdiri dari empat modul utama:
- HDFS – Sistem File Terdistribusi Hadoop. Ini adalah sistem file yang mengelola penyimpanan kumpulan data besar di seluruh cluster Hadoop. HDFS dapat menangani data terstruktur dan tidak terstruktur. Perangkat keras penyimpanan dapat berkisar dari HDD kelas konsumen apa pun hingga drive perusahaan.
- MapReduce. Komponen pemrosesan ekosistem Hadoop. Ini menetapkan fragmen data dari HDFS untuk memisahkan tugas peta di cluster. MapReduce memproses potongan secara paralel untuk menggabungkan potongan menjadi hasil yang diinginkan.
- BENANG. Namun Negosiator Sumber Daya Lain. Bertanggung jawab untuk mengelola sumber daya komputasi dan penjadwalan pekerjaan.
- Hadoop Umum. Kumpulan pustaka dan utilitas umum yang bergantung pada modul lain. Nama lain untuk modul ini adalah inti Hadoop, karena menyediakan dukungan untuk semua komponen Hadoop lainnya.
Sifat Hadoop membuatnya dapat diakses oleh semua orang yang membutuhkannya. Komunitas sumber terbuka besar dan membuka jalan menuju pemrosesan data besar yang dapat diakses.
Apa itu Spark?
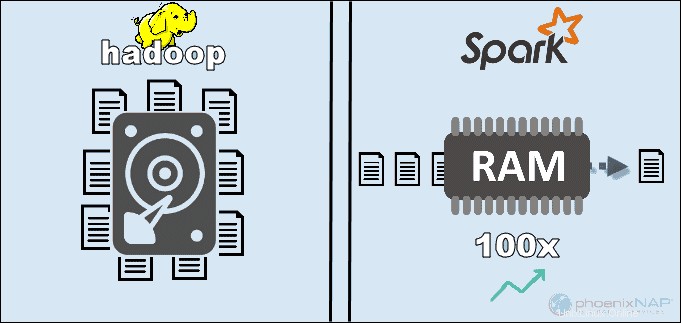
Apache Spark adalah alat sumber terbuka. Framework ini dapat berjalan dalam mode standalone atau di cloud atau cluster manager seperti Apache Mesos, dan platform lainnya. Ini dirancang untuk kinerja cepat dan menggunakan RAM untuk menyimpan dan memproses data.
Spark melakukan berbagai jenis beban kerja data besar. Ini termasuk pemrosesan batch seperti MapReduce, serta pemrosesan aliran waktu nyata, pembelajaran mesin, perhitungan grafik, dan kueri interaktif. Dengan API tingkat tinggi yang mudah digunakan, Spark dapat berintegrasi dengan banyak pustaka yang berbeda, termasuk PyTorch dan TensorFlow. Untuk mempelajari perbedaan antara kedua library ini, lihat artikel kami tentang PyTorch vs. TensorFlow.
Mesin Spark diciptakan untuk meningkatkan efisiensi MapReduce dan mempertahankan manfaatnya. Meskipun Spark tidak memiliki sistem filenya, ia dapat mengakses data pada banyak solusi penyimpanan yang berbeda. Struktur data yang digunakan Spark disebut Dataset Terdistribusi Tangguh , atau RDD.
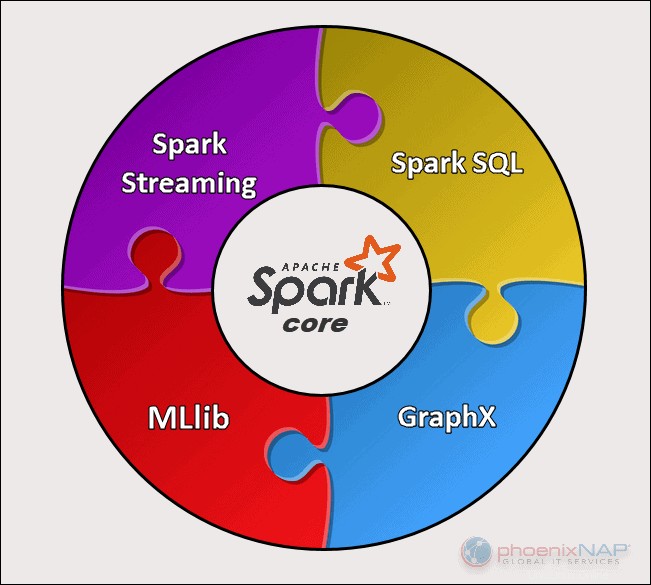
Ada lima komponen utama Apache Spark:
- Apache Spark Core . Dasar dari keseluruhan proyek. Spark Core bertanggung jawab atas fungsi yang diperlukan seperti penjadwalan, pengiriman tugas, operasi input dan output, pemulihan kesalahan, dll. Fungsi lain dibangun di atasnya.
- Percikan Streaming. Komponen ini memungkinkan pemrosesan aliran data langsung. Data dapat berasal dari berbagai sumber, termasuk Kafka, Kinesis, Flume, dll.
- Spark SQL . Spark menggunakan komponen ini untuk mengumpulkan informasi tentang data terstruktur dan bagaimana data diproses.
- Perpustakaan Pembelajaran Mesin (MLlib) . Perpustakaan ini terdiri dari banyak algoritma pembelajaran mesin. Tujuan MLlib adalah skalabilitas dan membuat pembelajaran mesin lebih mudah diakses.
- GraphX . Kumpulan API yang digunakan untuk memfasilitasi tugas analisis grafik.
Perbedaan Kunci Antara Hadoop dan Spark
Bagian berikut menguraikan perbedaan dan persamaan utama antara kedua kerangka kerja tersebut. Kita akan melihat Hadoop vs. Spark dari berbagai sudut.
Beberapa di antaranya adalah biaya , kinerja , keamanan , dan kemudahan penggunaan .
Tabel di bawah ini memberikan gambaran umum tentang kesimpulan yang dibuat di bagian berikut.
Perbandingan Hadoop dan Spark
| Kategori untuk Perbandingan | Hadoop | Percikan |
| Kinerja | Kinerja lebih lambat, menggunakan disk untuk penyimpanan dan bergantung pada kecepatan baca dan tulis disk. | Kinerja dalam memori yang cepat dengan pengurangan operasi pembacaan dan penulisan disk. |
| Biaya | Platform sumber terbuka, lebih murah untuk dijalankan. Menggunakan perangkat keras konsumen yang terjangkau. Lebih mudah untuk menemukan profesional Hadoop terlatih. | Platform sumber terbuka, tetapi bergantung pada memori untuk komputasi, yang secara signifikan meningkatkan biaya operasional. |
| Pemrosesan Data | Terbaik untuk pemrosesan batch. Menggunakan MapReduce untuk membagi kumpulan data besar di seluruh cluster untuk analisis paralel. | Cocok untuk analisis data berulang dan streaming langsung. Bekerja dengan RDD dan DAG untuk menjalankan operasi. |
| Toleransi Kesalahan | Sistem yang sangat toleran terhadap kesalahan. Mereplikasi data di seluruh node dan menggunakannya jika terjadi masalah. | Melacak proses pembuatan blok RDD, dan kemudian dapat membangun kembali kumpulan data saat partisi gagal. Spark juga dapat menggunakan DAG untuk membangun kembali data di seluruh node. |
| Skalabilitas | Mudah diskalakan dengan menambahkan node dan disk untuk penyimpanan. Mendukung puluhan ribu node tanpa batas yang diketahui. | Sedikit lebih menantang untuk diskalakan karena mengandalkan RAM untuk komputasi. Mendukung ribuan node dalam sebuah cluster. |
| Keamanan | Sangat aman. Mendukung LDAP, ACL, Kerberos, SLA, dll. | Tidak aman. Secara default, keamanan dimatikan. Mengandalkan integrasi dengan Hadoop untuk mencapai tingkat keamanan yang diperlukan. |
| Kemudahan Penggunaan dan Dukungan Bahasa | Lebih sulit digunakan dengan bahasa yang kurang didukung. Menggunakan Java atau Python untuk aplikasi MapReduce. | Lebih ramah pengguna. Memungkinkan mode shell interaktif. API dapat ditulis dalam Java, Scala, R, Python, Spark SQL. |
| Pembelajaran Mesin | Lebih lambat dari Spark. Fragmen data bisa terlalu besar dan membuat kemacetan. Mahout adalah perpustakaan utama. | Jauh lebih cepat dengan pemrosesan dalam memori. Menggunakan MLlib untuk perhitungan. |
| Penjadwalan dan Manajemen Sumber Daya | Menggunakan solusi eksternal. BENANG adalah opsi paling umum untuk manajemen sumber daya. Oozie tersedia untuk penjadwalan alur kerja. | Memiliki alat bawaan untuk alokasi sumber daya, penjadwalan, dan pemantauan. |
Kinerja
Saat kita melihat Hadoop vs. Spark dalam hal cara mereka memproses data , mungkin tidak wajar untuk membandingkan kinerja kedua kerangka kerja. Namun, kita dapat menarik garis dan mendapatkan gambaran yang jelas tentang alat mana yang lebih cepat.
Dengan mengakses data yang disimpan secara lokal di HDFS, Hadoop meningkatkan kinerja secara keseluruhan. Namun, ini tidak cocok untuk pemrosesan dalam memori Spark. Menurut klaim Apache, Spark tampaknya 100x lebih cepat saat menggunakan RAM untuk komputasi daripada Hadoop dengan MapReduce.
Dominasi tetap dengan menyortir data pada disk. Spark 3x lebih cepat dan membutuhkan 10x lebih sedikit node untuk memproses 100TB data di HDFS. Tolok ukur ini cukup untuk memecahkan rekor dunia pada tahun 2014.
Alasan utama untuk supremasi Spark ini adalah karena ia tidak membaca dan menulis data perantara ke disk tetapi menggunakan RAM. Hadoop menyimpan data pada banyak sumber yang berbeda dan kemudian memproses data dalam batch menggunakan MapReduce.
Semua hal di atas dapat memposisikan Spark sebagai pemenang mutlak. Namun, jika ukuran data lebih besar dari RAM yang tersedia, Hadoop adalah pilihan yang lebih logis. Hal lain yang perlu dipertimbangkan adalah biaya menjalankan sistem ini.
Biaya
Membandingkan Hadoop vs. Spark dengan mempertimbangkan biaya, kita perlu menggali lebih dalam dari harga perangkat lunak. Kedua platform tersebut open-source dan sepenuhnya gratis. Namun demikian, biaya infrastruktur, pemeliharaan, dan pengembangan perlu dipertimbangkan untuk mendapatkan Total Cost of Ownership (TCO) kasar.
Faktor paling signifikan dalam kategori biaya adalah perangkat keras dasar yang Anda perlukan untuk menjalankan alat ini. Karena Hadoop bergantung pada semua jenis penyimpanan disk untuk pemrosesan data, biaya menjalankannya relatif rendah.
Di sisi lain, Spark bergantung pada komputasi dalam memori untuk pemrosesan data waktu nyata. Jadi, memutar node dengan banyak RAM akan meningkatkan biaya kepemilikan secara signifikan.
Kekhawatiran lainnya adalah pengembangan aplikasi. Hadoop telah ada lebih lama dari Spark dan tidak terlalu sulit untuk menemukan pengembang perangkat lunak.
Poin di atas menunjukkan bahwa Infrastruktur Hadoop lebih hemat biaya . Meskipun pernyataan ini benar, kita perlu diingatkan bahwa Spark memproses data lebih cepat. Oleh karena itu, dibutuhkan lebih sedikit mesin untuk menyelesaikan tugas yang sama.
Pemrosesan Data
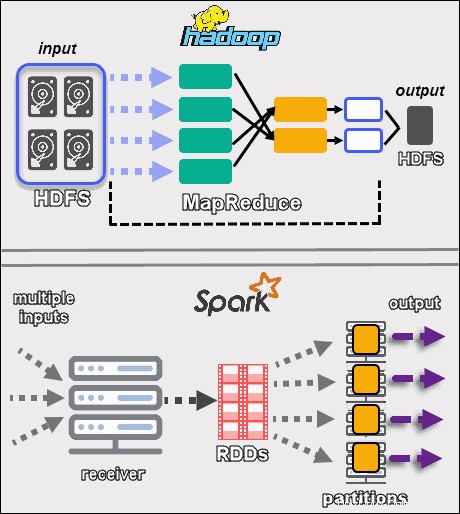
Kedua kerangka kerja menangani data dengan cara yang sangat berbeda . Meskipun Hadoop dengan MapReduce dan Spark dengan RDD memproses data dalam lingkungan terdistribusi, Hadoop lebih cocok untuk pemrosesan batch. Sebaliknya, Spark bersinar dengan pemrosesan waktu nyata.
Tujuan Hadoop adalah untuk menyimpan data pada disk dan kemudian menganalisisnya secara paralel dalam batch di lingkungan terdistribusi. MapReduce tidak memerlukan RAM dalam jumlah besar untuk menangani volume data yang besar. Hadoop mengandalkan perangkat keras sehari-hari untuk penyimpanan, dan paling cocok untuk pemrosesan data linier.
Apache Spark bekerja dengan kumpulan data terdistribusi yang tangguh (RDD ). RDD adalah kumpulan elemen terdistribusi yang disimpan dalam partisi pada node di seluruh cluster. Ukuran RDD biasanya terlalu besar untuk ditangani oleh satu node. Oleh karena itu, Spark mempartisi RDD ke node terdekat dan melakukan operasi secara paralel. Sistem melacak semua tindakan yang dilakukan pada RDD dengan menggunakan Grafik Asiklik Berarah (DAG ).
Dengan komputasi dalam memori dan API tingkat tinggi, Spark secara efektif menangani aliran data tidak terstruktur secara langsung. Selanjutnya, data disimpan dalam jumlah partisi yang telah ditentukan. Satu node dapat memiliki partisi sebanyak yang diperlukan, tetapi satu partisi tidak dapat diperluas ke node lain.
Toleransi Kesalahan
Berbicara tentang Hadoop vs. Spark dalam kategori toleransi kesalahan, kita dapat mengatakan bahwa keduanya memberikan tingkat kegagalan penanganan yang terhormat . Juga, kita dapat mengatakan bahwa cara mereka mendekati toleransi kesalahan berbeda.
Hadoop memiliki toleransi kesalahan sebagai dasar operasinya. Ini mereplikasi data berkali-kali di seluruh node. Jika terjadi masalah, sistem melanjutkan pekerjaan dengan membuat blok yang hilang dari lokasi lain. Node master melacak status semua node slave. Terakhir, jika node slave tidak merespon ping dari master, master memberikan tugas yang tertunda ke node slave lainnya.
Spark menggunakan blok RDD untuk mencapai toleransi kesalahan. Sistem melacak bagaimana kumpulan data yang tidak dapat diubah dibuat. Kemudian, itu dapat memulai kembali proses ketika ada masalah. Spark dapat membangun kembali data dalam kluster dengan menggunakan pelacakan alur kerja DAG. Struktur data ini memungkinkan Spark untuk menangani kegagalan dalam ekosistem pemrosesan data terdistribusi.
Skalabilitas
Garis antara Hadoop dan Spark menjadi kabur di bagian ini. Hadoop menggunakan HDFS untuk menangani data besar. Ketika volume data berkembang pesat, Hadoop dapat dengan cepat menskalakan untuk mengakomodasi permintaan. Karena Spark tidak memiliki sistem filenya, Spark harus bergantung pada HDFS saat data terlalu besar untuk ditangani.
Cluster dapat dengan mudah memperluas dan meningkatkan daya komputasi dengan menambahkan lebih banyak server ke jaringan. Alhasil, jumlah node di kedua framework bisa mencapai ribuan. Tidak ada batasan tegas berapa banyak server yang dapat Anda tambahkan ke setiap cluster dan berapa banyak data yang dapat Anda proses.
Beberapa nomor yang dikonfirmasi termasuk 8000 mesin di lingkungan Spark dengan petabyte data. Ketika berbicara tentang kluster Hadoop, kluster Hadoop diketahui dapat menampung puluhan ribu mesin dan mendekati satu exabyte data.
Kemudahan Penggunaan dan Dukungan Bahasa Pemrograman
Spark mungkin merupakan kerangka kerja yang lebih baru dengan tidak banyak ahli yang tersedia seperti Hadoop, tetapi dikenal lebih ramah pengguna. Sebaliknya, Spark menyediakan dukungan untuk beberapa bahasa di sebelah bahasa asli (Scala):Java, Python, R, dan Spark SQL. Ini memungkinkan pengembang untuk menggunakan bahasa pemrograman yang mereka sukai.
Kerangka Hadoop didasarkan pada Java . Dua bahasa utama untuk menulis kode MapReduce adalah Java atau Python. Hadoop tidak memiliki mode interaktif untuk membantu pengguna. Namun, ini terintegrasi dengan alat Pig and Hive untuk memfasilitasi penulisan program MapReduce yang kompleks.
Selain dukungan untuk API dalam berbagai bahasa, Spark menang di bagian kemudahan penggunaan dengan mode interaktifnya. Anda dapat menggunakan shell Spark untuk menganalisis data secara interaktif dengan Scala atau Python. Shell memberikan umpan balik instan ke kueri, yang membuat Spark lebih mudah digunakan daripada Hadoop MapReduce.
Hal lain yang membuat Spark unggul adalah pemrogram dapat menggunakan kembali kode yang ada jika memungkinkan. Dengan demikian, pengembang dapat mengurangi waktu pengembangan aplikasi. Data historis dan aliran dapat digabungkan untuk membuat proses ini lebih efektif.
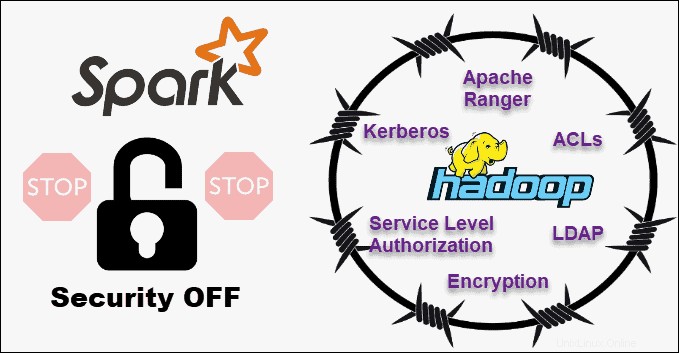
Keamanan
Membandingkan keamanan Hadoop vs. Spark, kami akan segera mengeluarkannya – Hadoop adalah pemenangnya . Di atas segalanya, keamanan Spark tidak aktif secara default. Ini berarti penyiapan Anda akan terungkap jika Anda tidak mengatasi masalah ini.
Anda dapat meningkatkan keamanan Spark dengan memperkenalkan otentikasi melalui rahasia bersama atau pencatatan peristiwa. Namun, itu tidak cukup untuk beban kerja produksi.
Sebaliknya, Hadoop bekerja dengan beberapa metode otentikasi dan kontrol akses. Yang paling sulit untuk diterapkan adalah otentikasi Kerberos. Jika Kerberos terlalu banyak untuk ditangani, Hadoop juga mendukung Ranger , LDAP , ACL , enkripsi antar-simpul , izin file standar pada HDFS, dan Otorisasi Tingkat Layanan .
Namun, Spark dapat mencapai tingkat keamanan yang memadai dengan berintegrasi dengan Hadoop . Dengan cara ini, Spark dapat menggunakan semua metode yang tersedia untuk Hadoop dan HDFS. Selanjutnya, ketika Spark berjalan pada YARN, Anda dapat mengadopsi manfaat dari metode otentikasi lain yang kami sebutkan di atas.
Pembelajaran Mesin
Pembelajaran mesin adalah proses berulang yang bekerja paling baik dengan menggunakan komputasi dalam memori. Karena alasan ini, Spark terbukti menjadi solusi yang lebih cepat di area ini.
Alasannya adalah karena Hadoop MapReduce membagi tugas menjadi tugas paralel yang mungkin terlalu besar untuk algoritme pembelajaran mesin. Proses ini menciptakan masalah kinerja I/O dalam aplikasi Hadoop ini.
Pustaka Mahout adalah platform pembelajaran mesin utama di cluster Hadoop. Mahout mengandalkan MapReduce untuk melakukan clustering, klasifikasi, dan rekomendasi. Samsara mulai menggantikan proyek ini.
Spark hadir dengan perpustakaan pembelajaran mesin default, MLlib. Pustaka ini melakukan komputasi ML dalam memori berulang. Ini mencakup alat untuk melakukan regresi, klasifikasi, ketekunan, pembuatan saluran, evaluasi, dan banyak lagi.
Spark dengan MLlib terbukti sembilan kali lebih cepat daripada Apache Mahout dalam lingkungan berbasis disk Hadoop. Saat Anda membutuhkan hasil yang lebih efisien daripada yang ditawarkan Hadoop, Spark adalah pilihan yang lebih baik untuk Machine Learning.
Penjadwalan dan Manajemen Sumber Daya
Hadoop tidak memiliki penjadwal bawaan. Ini menggunakan solusi eksternal untuk manajemen sumber daya dan penjadwalan. Dengan ResourceManager dan NodeManager , YARN bertanggung jawab untuk manajemen sumber daya di cluster Hadoop. Salah satu alat yang tersedia untuk menjadwalkan alur kerja adalah Oozie.
YARN tidak berurusan dengan manajemen status aplikasi individu. Itu hanya mengalokasikan kekuatan pemrosesan yang tersedia.
Hadoop MapReduce bekerja dengan plugin seperti CapacityScheduler dan FairScheduler . Penjadwal ini memastikan aplikasi mendapatkan sumber daya penting sesuai kebutuhan sambil mempertahankan efisiensi cluster. FairScheduler memberikan sumber daya yang diperlukan ke aplikasi sambil melacak bahwa, pada akhirnya, semua aplikasi mendapatkan alokasi sumber daya yang sama.
Spark, di sisi lain, memiliki fungsi-fungsi ini bawaan. Penjadwal DAG bertanggung jawab untuk membagi operator menjadi beberapa tahapan. Setiap tahap memiliki banyak tugas yang DAG jadwalkan dan harus dijalankan oleh Spark.
Spark Scheduler dan Block Manager melakukan penjadwalan tugas dan tugas, pemantauan, dan distribusi sumber daya dalam sebuah cluster.
Gunakan Kasus Hadoop versus Spark
Melihat Hadoop versus Spark di bagian yang tercantum di atas, kita dapat mengekstrak beberapa kasus penggunaan untuk setiap kerangka kerja.
Kasus penggunaan Hadoop meliputi:
- Memproses kumpulan data besar di lingkungan yang ukuran datanya melebihi memori yang tersedia.
- Membangun infrastruktur analisis data dengan anggaran terbatas.
- Menyelesaikan pekerjaan yang tidak memerlukan hasil langsung, dan waktu bukanlah faktor pembatas.
- Pemrosesan batch dengan tugas yang mengeksploitasi operasi baca dan tulis disk.
- Analisis data historis dan arsip.
Dengan Spark, kita dapat memisahkan kasus penggunaan berikut yang mengungguli Hadoop:
- Analisis data aliran waktu nyata.
- Saat waktu sangat penting, Spark memberikan hasil yang cepat dengan perhitungan dalam memori.
- Menangani rantai operasi paralel menggunakan algoritme iteratif.
- Pemrosesan grafik paralel untuk memodelkan data.
- Semua aplikasi pembelajaran mesin.
Catatan :Jika Anda telah membuat keputusan, Anda dapat mengikuti panduan kami tentang cara menginstal Hadoop di Ubuntu atau cara menginstal Spark di Ubuntu. Jika Anda bekerja di Windows 10, lihat Cara Memasang Spark di Windows 10.
Hadoop atau Spark?
Hadoop dan Spark adalah teknologi untuk menangani data besar. Selain itu, mereka adalah kerangka kerja yang sangat berbeda dalam cara mereka mengelola dan memproses data.
Menurut bagian sebelumnya dalam artikel ini, tampaknya Spark adalah pemenang yang jelas. Meskipun ini mungkin benar sampai batas tertentu, pada kenyataannya, mereka tidak diciptakan untuk bersaing satu sama lain, melainkan saling melengkapi.
Tentu saja, seperti yang kami sebutkan sebelumnya di artikel ini, ada kasus penggunaan di mana satu atau kerangka lain adalah pilihan yang lebih logis. Di sebagian besar aplikasi lain, Hadoop dan Spark bekerja paling baik bersama . Sebagai penerus, Spark hadir bukan untuk menggantikan Hadoop tetapi menggunakan fitur-fiturnya untuk menciptakan ekosistem baru yang lebih baik.
Dengan menggabungkan keduanya, Spark dapat memanfaatkan fitur yang hilang, seperti sistem file. Hadoop menyimpan sejumlah besar data menggunakan perangkat keras yang terjangkau dan kemudian melakukan analitik, sementara Spark menghadirkan pemrosesan waktu nyata untuk menangani data yang masuk. Tanpa Hadoop, aplikasi bisnis mungkin kehilangan data historis penting yang tidak ditangani Spark.
Dalam lingkungan kooperatif ini, Spark juga memanfaatkan manfaat keamanan dan manajemen sumber daya Hadoop. Dengan YARN, pengelompokan Spark dan manajemen data menjadi lebih mudah. Anda dapat menjalankan beban kerja Spark secara otomatis menggunakan sumber daya yang tersedia.
Kolaborasi ini memberikan hasil terbaik dalam analisis data transaksional retroaktif, analisis lanjutan, dan pemrosesan data IoT. Semua kasus penggunaan ini dimungkinkan dalam satu lingkungan.
Pembuat Hadoop dan Spark bermaksud membuat kedua platform kompatibel dan menghasilkan hasil yang optimal cocok untuk kebutuhan bisnis apa pun.