Pendahuluan
Apache Spark adalah kerangka kerja sumber terbuka yang memproses sejumlah besar aliran data dari berbagai sumber. Spark digunakan dalam komputasi terdistribusi dengan aplikasi pembelajaran mesin, analisis data, dan pemrosesan grafik paralel.
Panduan ini akan menunjukkan kepada Anda cara menginstal Apache Spark di Windows 10 dan uji penginstalan.

Prasyarat
- Sistem yang menjalankan Windows 10
- Akun pengguna dengan hak administrator (diperlukan untuk menginstal perangkat lunak, memodifikasi izin file, dan memodifikasi PATH sistem)
- Prompt Perintah atau Powershell
- Alat untuk mengekstrak file .tar, seperti 7-Zip
Instal Apache Spark di Windows
Menginstal Apache Spark di Windows 10 mungkin tampak rumit bagi pengguna pemula, tetapi tutorial sederhana ini akan membuat Anda siap dan berjalan. Jika Anda sudah menginstal Java 8 dan Python 3, Anda dapat melewati dua langkah pertama.
Langkah 1:Instal Java 8
Apache Spark membutuhkan Java 8. Anda dapat memeriksa apakah Java telah diinstal menggunakan command prompt.
Buka baris perintah dengan mengeklik Mulai> ketik cmd> klik Prompt Perintah .
Ketik perintah berikut di command prompt:
java -versionJika Java diinstal, itu akan merespons dengan output berikut:
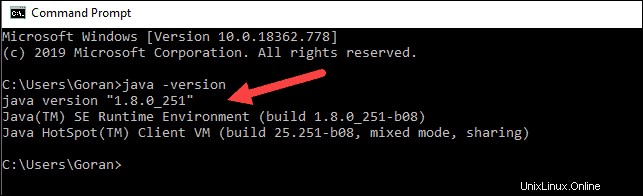
Versi Anda mungkin berbeda. Digit kedua adalah versi Java – dalam hal ini, Java 8.
Jika Anda belum menginstal Java:
1. Buka jendela browser, dan navigasikan ke https://java.com/en/download/.
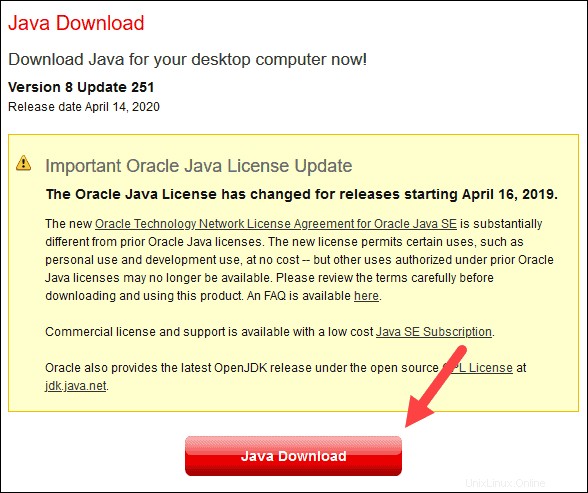
2. Klik Unduhan Java tombol dan simpan file ke lokasi pilihan Anda.
3. Setelah unduhan selesai, klik dua kali file tersebut untuk menginstal Java.
Langkah 2:Instal Python
1. Untuk menginstal pengelola paket Python, navigasikan ke https://www.python.org/ di browser web Anda.
2. Arahkan mouse ke Unduh opsi menu dan klik Python 3.8.3 . 3.8.3 adalah versi terbaru pada saat artikel ini ditulis.
3. Setelah unduhan selesai, jalankan file tersebut.
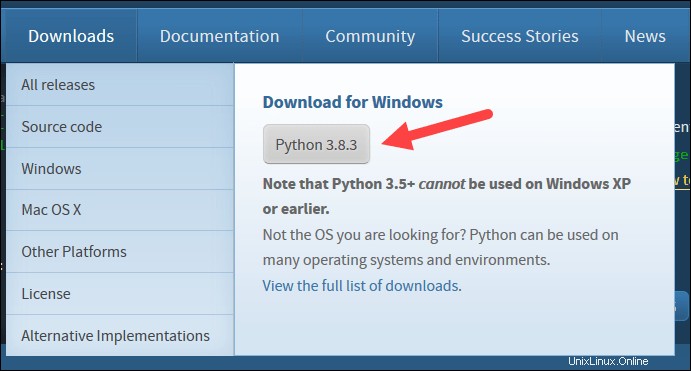
4. Di dekat bagian bawah kotak dialog pengaturan pertama, centang Tambahkan Python 3.8 ke PATH . Biarkan kotak lainnya dicentang.
5. Selanjutnya, klik Sesuaikan pemasangan .
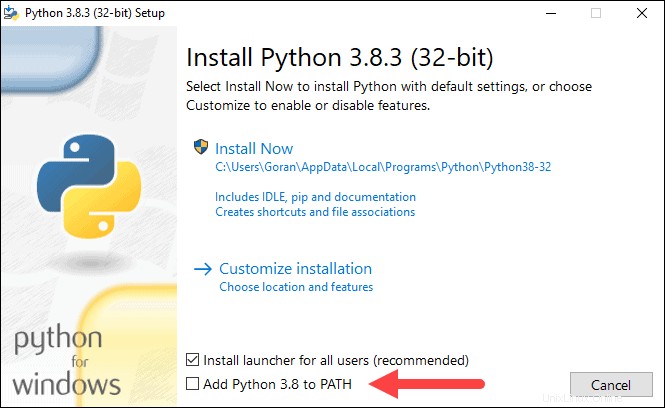
6. Anda dapat membiarkan semua kotak dicentang pada langkah ini, atau Anda dapat menghapus centang pada opsi yang tidak Anda inginkan.
7. Klik Berikutnya .
8. Pilih kotak Instal untuk semua pengguna dan biarkan kotak lain apa adanya.
9. Di bawah Sesuaikan lokasi pemasangan, klik Jelajahi dan arahkan ke drive C. Tambahkan folder baru dan beri nama Python .
10. Pilih folder itu dan klik OK .
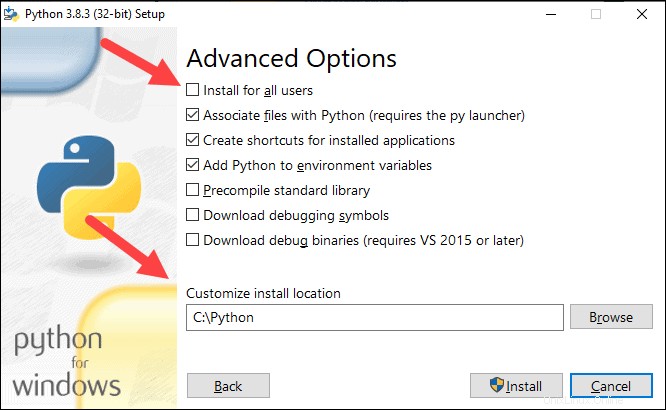
11. Klik Pasang , dan biarkan penginstalan selesai.
12. Saat penginstalan selesai, klik Disable path length limit di bagian bawah, lalu klik Tutup .
13. Jika Anda memiliki prompt perintah yang terbuka, mulai ulang. Verifikasi instalasi dengan memeriksa versi Python:
python --version
Outputnya harus mencetak Python 3.8.3 .
Langkah 3:Unduh Apache Spark
1. Buka browser dan navigasikan ke https://spark.apache.org/downloads.html.
2. Di bawah Unduh Apache Spark menuju, ada dua menu drop-down. Gunakan versi non-pratinjau saat ini.
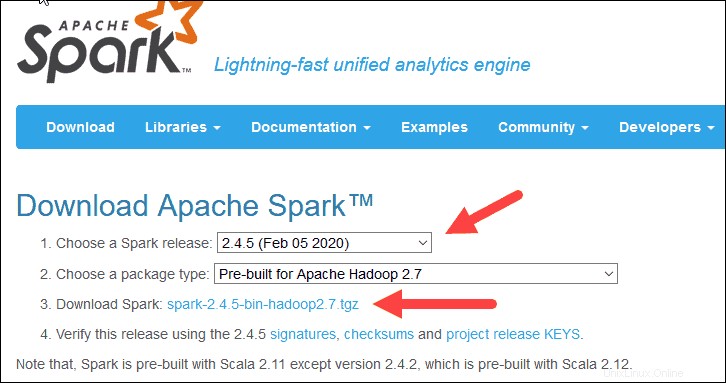
- Dalam kasus kami, di Pilih rilis Spark menu tarik-turun pilih 2.4.5 (5 Februari 2020) .
- Di tarik-turun kedua Pilih jenis paket , biarkan pilihan Pre-built untuk Apache Hadoop 2.7 .
3. Klik spark-2.4.5-bin-hadoop2.7.tgz tautan.
4. Halaman dengan daftar mirror memuat tempat Anda dapat melihat server yang berbeda untuk diunduh. Pilih salah satu dari daftar dan simpan file ke folder Unduhan Anda.
Langkah 4:Verifikasi File Perangkat Lunak Spark
1. Verifikasi integritas unduhan Anda dengan mencentang checksum dari file. Ini memastikan Anda bekerja dengan perangkat lunak yang tidak berubah dan tidak rusak.
2. Navigasikan kembali ke Unduhan Spark halaman dan buka Checksum link, sebaiknya di tab baru.
3. Selanjutnya, buka baris perintah dan masukkan perintah berikut:
certutil -hashfile c:\users\username\Downloads\spark-2.4.5-bin-hadoop2.7.tgz SHA512
4. Ubah nama pengguna menjadi nama pengguna Anda. Sistem menampilkan kode alfanumerik yang panjang, bersama dengan pesan Certutil: -hashfile completed successfully .
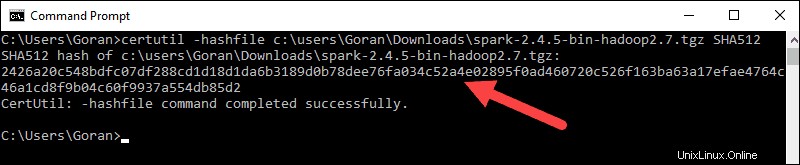
5. Bandingkan kode dengan yang Anda buka di tab browser baru. Jika cocok, file unduhan Anda tidak rusak.
Langkah 5:Instal Apache Spark
Menginstal Apache Spark melibatkan mengekstrak file yang diunduh ke lokasi yang diinginkan.
1. Buat folder baru bernama Spark di root drive C:Anda. Dari baris perintah, masukkan berikut ini:
cd \
mkdir Spark2. Di Explorer, cari file Spark yang Anda unduh.
3. Klik kanan file dan ekstrak ke C:\Spark menggunakan alat yang Anda miliki di sistem Anda (mis., 7-Zip).
4. Sekarang, C:\Spark . Anda folder memiliki folder baru spark-2.4.5-bin-hadoop2.7 dengan file yang diperlukan di dalamnya.
Langkah 6:Tambahkan File winutils.exe
Unduh winutils.exe file untuk versi Hadoop yang mendasari untuk instalasi Spark yang Anda unduh.
1. Navigasikan ke URL ini https://github.com/cdarlint/winutils dan di dalam bin folder, cari winutils.exe , dan klik.
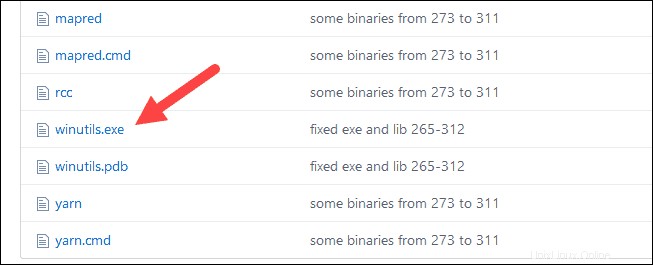
2. Temukan Unduh tombol di sisi kanan untuk mengunduh file.
3. Sekarang, buat folder baru Hadoop dan bin di C:menggunakan Windows Explorer atau Command Prompt.
4. Salin file winutils.exe dari folder Downloads ke C:\hadoop\bin .
Langkah 7:Konfigurasi Variabel Lingkungan
Mengonfigurasi variabel lingkungan di Windows menambahkan lokasi Spark dan Hadoop ke PATH sistem Anda. Ini memungkinkan Anda untuk menjalankan shell Spark langsung dari jendela command prompt.
1. Klik Mulai dan ketik lingkungan .
2. Pilih hasil berlabel Edit variabel lingkungan sistem .
3. Kotak dialog System Properties muncul. Di pojok kanan bawah, klik Variabel Lingkungan lalu klik Baru di jendela berikutnya.
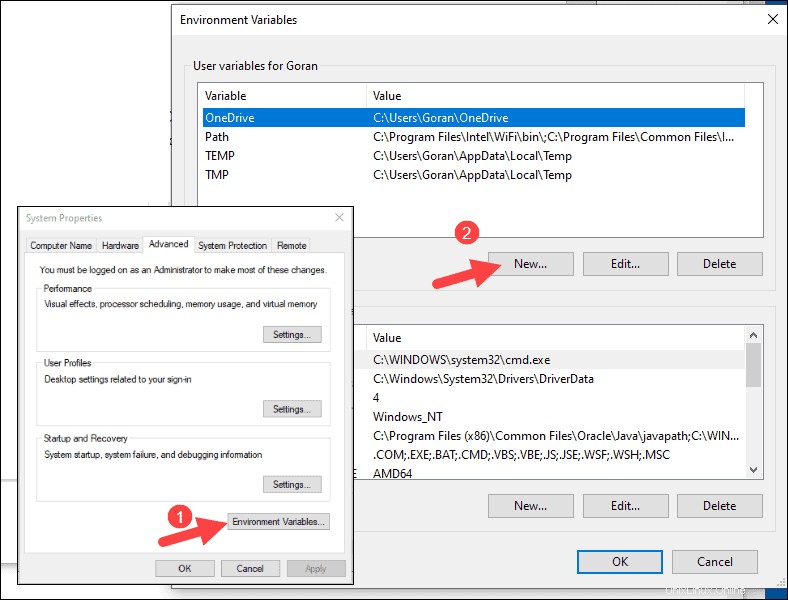
4. Untuk Nama Variabel ketik SPARK_HOME .
5. Untuk Nilai Variabel ketik C:\Spark\spark-2.4.5-bin-hadoop2.7 dan klik OK. Jika Anda mengubah jalur folder, gunakan yang itu saja.
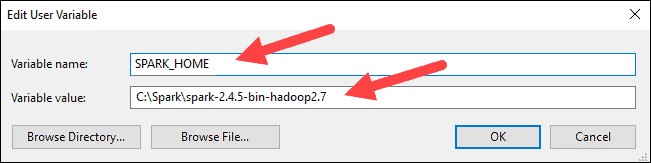
6. Di kotak atas, klik Jalur entri, lalu klik Edit . Hati-hati dengan mengedit jalur sistem. Hindari menghapus entri yang sudah ada dalam daftar.
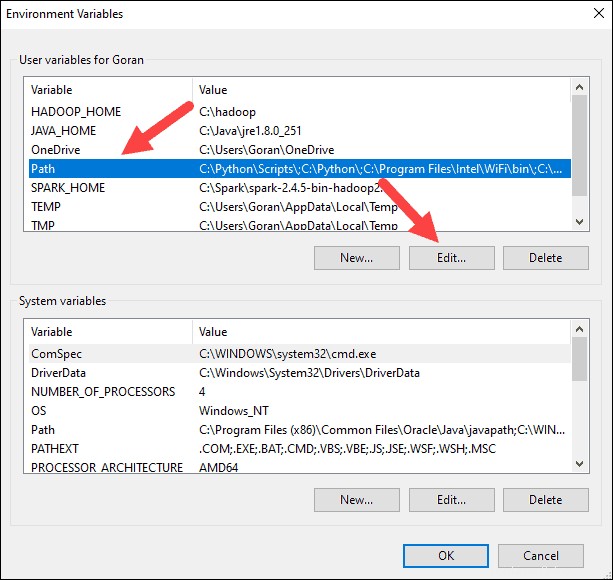
7. Anda akan melihat kotak dengan entri di sebelah kiri. Di sebelah kanan, klik Baru .
8. Sistem menyoroti baris baru. Masukkan jalur ke folder Spark C:\Spark\spark-2.4.5-bin-hadoop2.7\bin . Sebaiknya gunakan %SPARK_HOME%\bin untuk menghindari kemungkinan masalah dengan jalur.
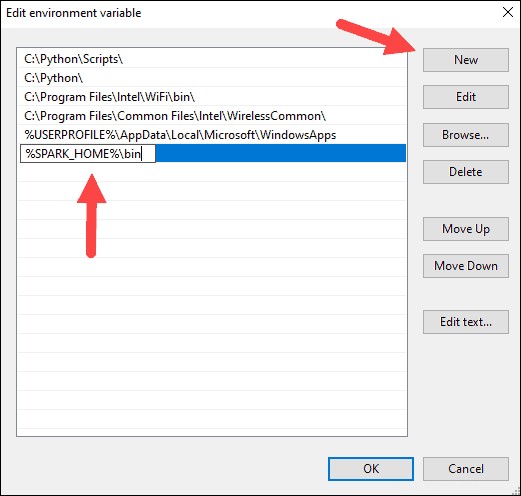
9. Ulangi proses ini untuk Hadoop dan Java.
- Untuk Hadoop, nama variabelnya adalah HADOOP_HOME dan untuk value gunakan path folder yang anda buat tadi:C:\hadoop. Tambahkan C:\hadoop\bin ke Variabel jalur bidang, tetapi sebaiknya gunakan %HADOOP_HOME%\bin .
- Untuk Java, nama variabelnya adalah JAVA_HOME dan untuk nilainya gunakan jalur ke direktori Java JDK Anda (dalam kasus kami ini C:\Program Files\Java\jdk1.8.0_251 ).
10. Klik Oke untuk menutup semua jendela yang terbuka.
Langkah 8:Luncurkan Spark
1. Buka jendela prompt perintah baru menggunakan klik kanan dan Run as administrator :
2. Untuk memulai Spark, masukkan:
C:\Spark\spark-2.4.5-bin-hadoop2.7\bin\spark-shell
Jika Anda menyetel jalur lingkungan dengan benar, Anda dapat mengetik spark-shell untuk meluncurkan Spark.
3. Sistem harus menampilkan beberapa baris yang menunjukkan status aplikasi. Anda mungkin mendapatkan pop-up Java. Pilih Izinkan akses untuk melanjutkan.
Terakhir, logo Spark muncul, dan prompt menampilkan Scala shell .
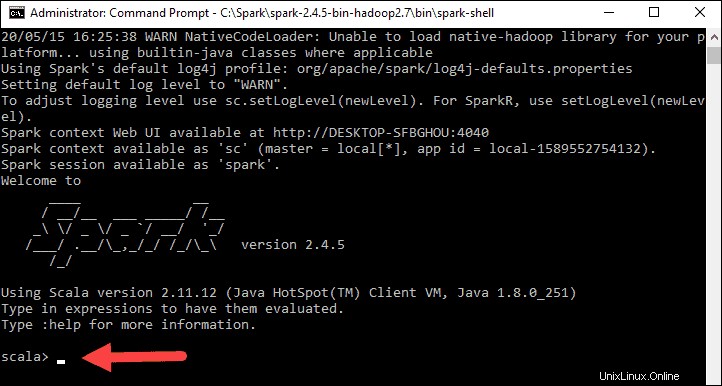
4., Buka browser web dan navigasikan ke http://localhost:4040/ .
5. Anda dapat mengganti localhost dengan nama sistem Anda.
6. Anda akan melihat UI Web shell Apache Spark. Contoh di bawah ini menunjukkan Pelaksana halaman.
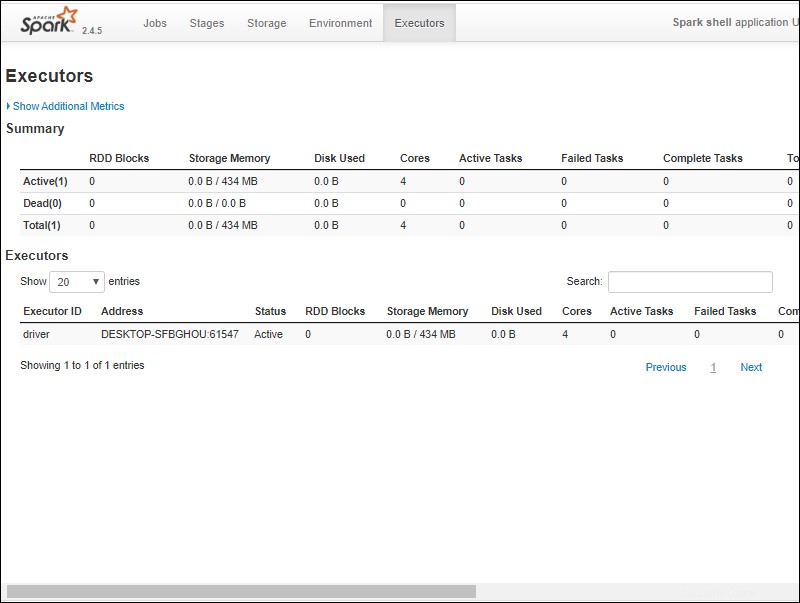
7. Untuk keluar dari Spark dan menutup shell Scala, tekan ctrl-d di jendela prompt perintah.
Percikan Uji
Dalam contoh ini, kami akan meluncurkan shell Spark dan menggunakan Scala untuk membaca konten file. Anda dapat menggunakan file yang ada, seperti README file di direktori Spark, atau Anda dapat membuatnya sendiri. Kami membuat pnaptest dengan beberapa teks.
1. Buka jendela prompt perintah dan navigasikan ke folder dengan file yang ingin Anda gunakan dan luncurkan shell Spark.
2. Pertama, nyatakan variabel yang akan digunakan dalam konteks Spark dengan nama file. Ingatlah untuk menambahkan ekstensi file jika ada.
val x =sc.textFile("pnaptest")3. Output menunjukkan RDD dibuat. Kemudian, kita dapat melihat isi file dengan menggunakan perintah ini untuk memanggil suatu tindakan:
x.take(11).foreach(println)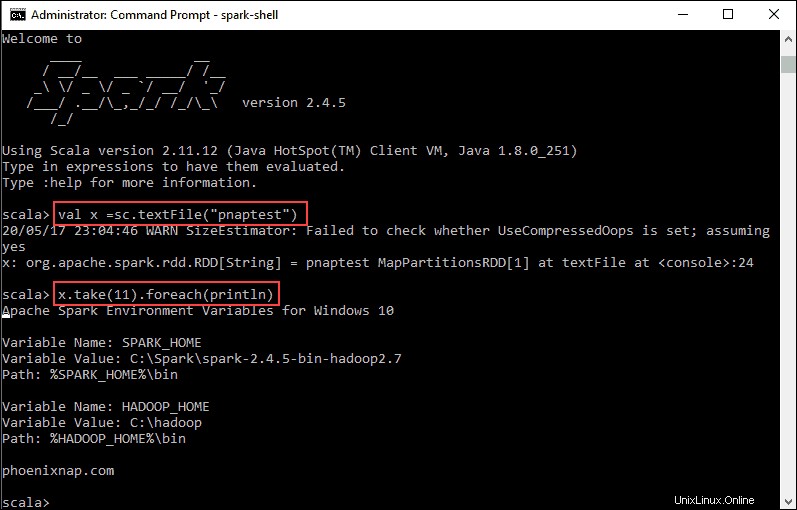
Perintah ini menginstruksikan Spark untuk mencetak 11 baris dari file yang Anda tentukan. Untuk melakukan tindakan pada file ini (nilai x ), tambahkan nilai lain y , dan lakukan transformasi peta.
4. Misalnya, Anda dapat mencetak karakter secara terbalik dengan perintah ini:
val y = x.map(_.reverse)5. Sistem membuat anak RDD dalam kaitannya dengan yang pertama. Kemudian, tentukan berapa banyak baris yang ingin Anda cetak dari nilai y :
y.take(11).foreach(println)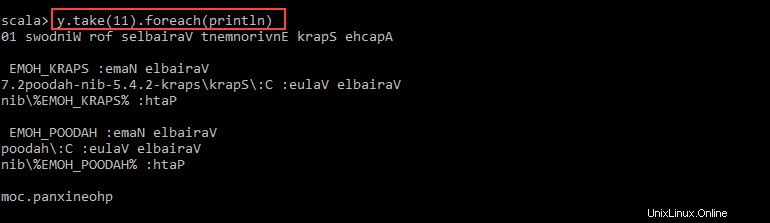
Output mencetak 11 baris pnaptest file dalam urutan terbalik.
Setelah selesai, keluar dari shell menggunakan ctrl-d .