Apache Spark adalah kerangka kerja sumber terbuka dan sistem komputasi cluster tujuan umum. Spark menyediakan API tingkat tinggi di Java, Scala, Python, dan R yang mendukung grafik eksekusi umum. Muncul dengan modul bawaan yang digunakan untuk streaming, SQL, pembelajaran mesin, dan pemrosesan grafik. Ia mampu menganalisis sejumlah besar data dan mendistribusikannya ke seluruh cluster dan memproses data secara paralel.
Dalam tutorial ini, kami akan menjelaskan cara menginstal tumpukan komputasi cluster Apache Spark di Ubuntu 20.04.
Prasyarat
- Server yang menjalankan server Ubuntu 20.04.
- Sandi root dikonfigurasi untuk server.
Memulai
Pertama, Anda perlu memperbarui paket sistem Anda ke versi terbaru. Anda dapat memperbarui semuanya dengan perintah berikut:
apt-get update -y
Setelah semua paket diperbarui, Anda dapat melanjutkan ke langkah berikutnya.
Instal Java
Apache Spark adalah aplikasi berbasis Java. Jadi Java harus diinstal di sistem Anda. Anda dapat menginstalnya dengan perintah berikut:
apt-get install default-jdk -y
Setelah Java diinstal, verifikasi versi Java yang diinstal dengan perintah berikut:
java --version
Anda akan melihat output berikut:
openjdk 11.0.8 2020-07-14 OpenJDK Runtime Environment (build 11.0.8+10-post-Ubuntu-0ubuntu120.04) OpenJDK 64-Bit Server VM (build 11.0.8+10-post-Ubuntu-0ubuntu120.04, mixed mode, sharing)
Instal Scala
Apache Spark dikembangkan menggunakan Scala. Jadi, Anda perlu menginstal Scala di sistem Anda. Anda dapat menginstalnya dengan perintah berikut:
apt-get install scala -y
Setelah menginstal Scala. Anda dapat memverifikasi versi Scala menggunakan perintah berikut:
scala -version
Anda akan melihat output berikut:
Scala code runner version 2.11.12 -- Copyright 2002-2017, LAMP/EPFL
Sekarang, sambungkan ke antarmuka Scala dengan perintah berikut:
scala
Anda akan mendapatkan output berikut:
Welcome to Scala 2.11.12 (OpenJDK 64-Bit Server VM, Java 11.0.8). Type in expressions for evaluation. Or try :help.
Sekarang, uji Scala dengan perintah berikut:
scala> println("Hitesh Jethva") Anda akan mendapatkan output berikut:
Hitesh Jethva
Instal Apache Spark
Pertama, Anda perlu mengunduh Apache Spark versi terbaru dari situs resminya. Pada saat penulisan tutorial ini, versi terbaru Apache Spark adalah 2.4.6. Anda dapat mengunduhnya ke direktori /opt dengan perintah berikut:
cd /opt
wget https://archive.apache.org/dist/spark/spark-2.4.6/spark-2.4.6-bin-hadoop2.7.tgz
Setelah diunduh, ekstrak file yang diunduh dengan perintah berikut:
tar -xvzf spark-2.4.6-bin-hadoop2.7.tgz
Selanjutnya, ganti nama direktori yang diekstraksi menjadi spark seperti yang ditunjukkan di bawah ini:
mv spark-2.4.6-bin-hadoop2.7 spark
Selanjutnya, Anda perlu mengonfigurasi lingkungan Spark sehingga Anda dapat dengan mudah menjalankan perintah Spark. Anda dapat mengonfigurasinya dengan mengedit file .bashrc:
nano ~/.bashrc
Tambahkan baris berikut di akhir file:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Simpan dan tutup file kemudian aktifkan lingkungan dengan perintah berikut:
source ~/.bashrc
Mulai Spark Master Server
Pada titik ini, Apache Spark diinstal dan dikonfigurasi. Sekarang, mulai server master Spark menggunakan perintah berikut:
start-master.sh
Anda akan melihat output berikut:
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-ubuntu2004.out
Secara default, Spark mendengarkan pada port 8080. Anda dapat memeriksanya menggunakan perintah berikut:
ss -tpln | grep 8080
Anda akan melihat output berikut:
LISTEN 0 1 *:8080 *:* users:(("java",pid=4930,fd=249))
Sekarang, buka browser web Anda dan akses antarmuka web Spark menggunakan URL http://your-server-ip:8080. Anda akan melihat layar berikut:
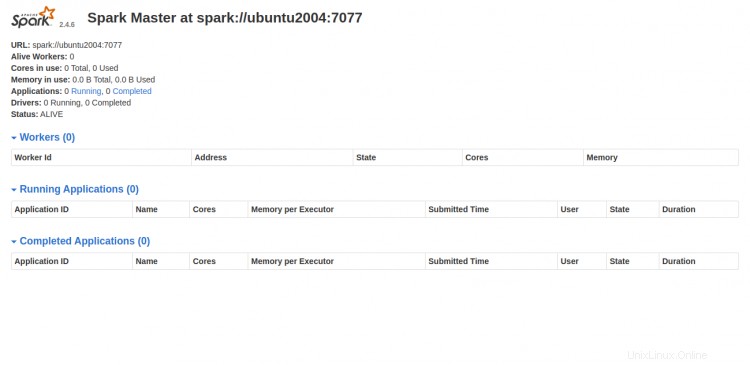
Mulai Proses Spark Worker
Seperti yang Anda lihat, layanan master Spark berjalan di spark://your-server-ip:7077. Jadi Anda dapat menggunakan alamat ini untuk memulai proses pekerja Spark menggunakan perintah berikut:
start-slave.sh spark://your-server-ip:7077
Anda akan melihat output berikut:
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-ubuntu2004.out
Sekarang, buka dasbor Spark dan segarkan layar. Anda akan melihat proses pekerja Spark di layar berikut:
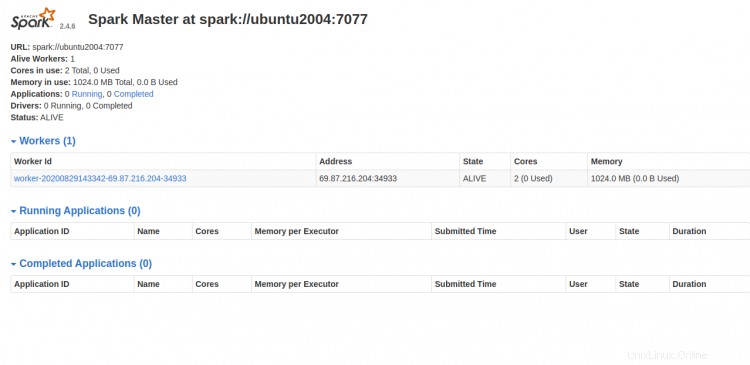
Bekerja dengan Spark Shell
Anda juga dapat menghubungkan server Spark menggunakan baris perintah. Anda dapat menghubungkannya menggunakan perintah spark-shell seperti yang ditunjukkan di bawah ini:
spark-shell
Setelah terhubung, Anda akan melihat output berikut:
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.11-2.4.6.jar) to method java.nio.Bits.unaligned()
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
20/08/29 14:35:07 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://ubuntu2004:4040
Spark context available as 'sc' (master = local[*], app id = local-1598711719335).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.6
/_/
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 11.0.8)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Jika Anda ingin menggunakan Python di Spark. Anda dapat menggunakan utilitas baris perintah pyspark.
Pertama, instal Python versi 2 dengan perintah berikut:
apt-get install python -y
Setelah terinstal, Anda dapat menghubungkan Spark dengan perintah berikut:
pyspark
Setelah terhubung, Anda akan mendapatkan output berikut:
Python 2.7.18rc1 (default, Apr 7 2020, 12:05:55)
[GCC 9.3.0] on linux2
Type "help", "copyright", "credits" or "license" for more information.
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.11-2.4.6.jar) to method java.nio.Bits.unaligned()
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
20/08/29 14:36:40 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.6
/_/
Using Python version 2.7.18rc1 (default, Apr 7 2020 12:05:55)
SparkSession available as 'spark'.
>>>
Jika Anda ingin menghentikan server Master dan Slave. Anda dapat melakukannya dengan perintah berikut:
stop-slave.sh
stop-master.sh
Kesimpulan
Selamat! Anda telah berhasil menginstal Apache Spark di server Ubuntu 20.04. Sekarang Anda seharusnya dapat melakukan pengujian dasar sebelum mulai mengonfigurasi kluster Spark. Jangan ragu untuk bertanya kepada saya jika Anda memiliki pertanyaan.