
Dalam tutorial ini, kami akan menunjukkan kepada Anda cara menginstal Apache Hadoop di CentOS 7. Bagi Anda yang belum tahu, Apache Hadoop adalah kerangka kerja perangkat lunak sumber terbuka yang ditulis dalam Java untuk penyimpanan terdistribusi dan proses distribusi, ia menangani kumpulan data berukuran sangat besar dengan mendistribusikannya ke seluruh cluster komputer. Daripada mengandalkan perangkat keras untuk memberikan ketersediaan tinggi, perpustakaan itu sendiri dirancang untuk mendeteksi dan menangani kegagalan pada lapisan aplikasi, sehingga memberikan -layanan yang tersedia di atas sekelompok komputer, yang masing-masing mungkin rentan terhadap kegagalan.
Artikel ini mengasumsikan Anda memiliki setidaknya pengetahuan dasar tentang Linux, tahu cara menggunakan shell, dan yang paling penting, Anda meng-host situs Anda di VPS Anda sendiri. Instalasinya cukup sederhana. Saya akan menunjukkan kepada Anda langkah demi langkah instalasi Apache Hadoop di CentOS 7.
Prasyarat
- Server yang menjalankan salah satu sistem operasi berikut:CentOS 7.
- Sebaiknya Anda menggunakan penginstalan OS baru untuk mencegah potensi masalah.
- Akses SSH ke server (atau cukup buka Terminal jika Anda menggunakan desktop).
- Seorang
non-root sudo useratau akses keroot user. Kami merekomendasikan untuk bertindak sebagainon-root sudo user, namun, karena Anda dapat membahayakan sistem jika tidak berhati-hati saat bertindak sebagai root.
Instal Apache Hadoop di CentOS 7
Langkah 1. Instal Java.
Karena Hadoop berbasis Java, pastikan Anda telah menginstal Java JDK di sistem. Jika Anda belum menginstal Java di sistem, gunakan tautan berikut untuk menginstalnya terlebih dahulu.
- Instal Java JDK 8 di CentOS 7
root@idroot.us ~# java -version java version "1.8.0_45" Java(TM) SE Runtime Environment (build 1.8.0_45-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, mixed mode)
Langkah 2. Instal Apache Hadoop.
Direkomendasikan untuk membuat user biasa untuk mengkonfigurasi apache Hadoop, buat user menggunakan perintah berikut:
useradd hadoop passwd hadoop
Setelah membuat pengguna, juga diperlukan untuk mengatur ssh berbasis kunci ke akunnya sendiri. Untuk melakukan ini, jalankan perintah berikut:
su - hadoop ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
Unduh Apache Hadoop versi stabil terbaru, Saat artikel ini ditulis adalah versi 2.7.0:
wget http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.0/hadoop-2.7.0.tar.gz tar xzf hadoop-2.7.0.tar.gz mv hadoop-2.7.0 hadoop
Langkah 3. Konfigurasi Apache Hadoop.
Setel variabel lingkungan yang digunakan oleh Hadoop. Edit file ~/.bashrc dan tambahkan nilai berikut di akhir file:
export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Menerapkan variabel lingkungan ke sesi yang sedang berjalan:
source ~/.bashrc
Sekarang edit $HADOOP_HOME/etc/hadoop/hadoop-env.sh file dan setel variabel lingkungan Java_HOME:
export JAVA_HOME=/usr/jdk1.8.0_45/
Hadoop memiliki banyak file konfigurasi, yang perlu dikonfigurasikan sesuai dengan persyaratan infrastruktur Hadoop Anda. Mari kita mulai dengan konfigurasi dengan pengaturan cluster node tunggal Hadoop dasar:
cd $HADOOP_HOME/etc/hadoop
Edit core-site.xml :
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
Edit hdfs-site.xml :
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:///home/hadoop/hadoopdata/hdfs/namenode</value> </property> <property> <name>dfs.data.dir</name> <value>file:///home/hadoop/hadoopdata/hdfs/datanode</value> </property> </configuration>
Edit mapred-site.xml :
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Edit yarn-site.xml :
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
Sekarang format namenode menggunakan perintah berikut, jangan lupa untuk memeriksa direktori penyimpanan:
hdfs namenode -format
Mulai semua layanan Hadoop gunakan perintah berikut:
cd $HADOOP_HOME/sbin/ start-dfs.sh start-yarn.sh
Untuk memeriksa apakah semua layanan dimulai dengan baik, gunakan ‘jps ' perintah:
jps
Langkah 4. Mengakses Apache Hadoop.
Apache Hadoop akan tersedia di HTTP port 8088 dan port 50070 secara default. Buka browser favorit Anda dan navigasikan ke http://your-domain.com:50070 atau http://server-ip:50070 . Jika Anda menggunakan firewall, buka port 8088 dan 50070 untuk mengaktifkan akses ke panel kontrol.
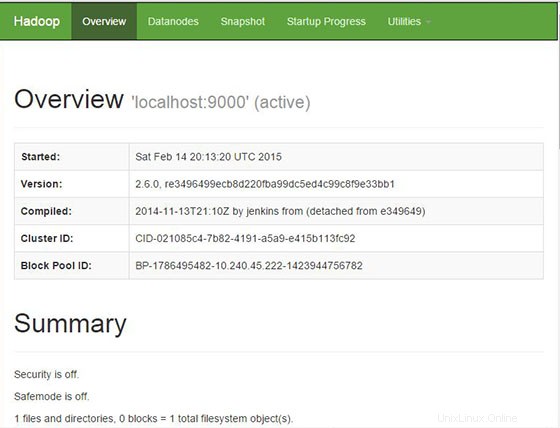
Sekarang akses port 8088 untuk mendapatkan informasi tentang cluster dan semua aplikasi:
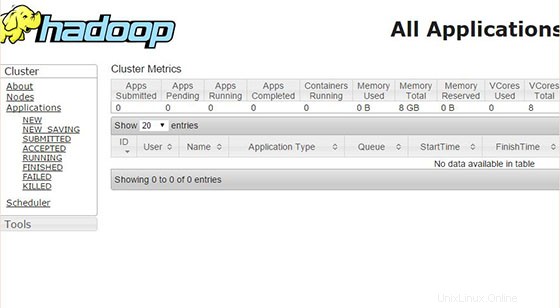
Selamat! Anda telah berhasil menginstal Apache Hadoop. Terima kasih telah menggunakan tutorial ini untuk menginstal Apache Hadoop pada sistem CentOS 7. Untuk bantuan tambahan atau informasi berguna, kami sarankan Anda memeriksa situs web resmi Apache Hadoop.