Pendahuluan
HDFS (Hadoop Distributed File System) adalah komponen penting dari proyek Apache Hadoop. Hadoop adalah ekosistem perangkat lunak yang bekerja sama untuk membantu Anda mengelola data besar. Dua elemen utama Hadoop adalah:
- MapReduce – bertanggung jawab untuk melaksanakan tugas
- HDFS – bertanggung jawab untuk menjaga data
Pada artikel ini, kita akan berbicara tentang yang kedua dari dua modul. Anda akan belajar apa itu HDFS, cara kerjanya, dan terminologi dasar HDFS .

Apa itu HDFS?
Hadoop Distributed File System adalah sistem file penyimpanan data yang toleran terhadap kesalahan yang berjalan pada perangkat keras komoditas. Itu dirancang untuk mengatasi tantangan yang tidak bisa dilakukan oleh database tradisional. Oleh karena itu, potensi penuhnya hanya dimanfaatkan saat menangani data besar.
Masalah utama yang harus dipecahkan oleh sistem file Hadoop adalah kecepatan , biaya , dan keandalan .
Apa Manfaat HDFS?
Manfaat HDFS sebenarnya adalah solusi yang disediakan sistem file untuk tantangan yang disebutkan sebelumnya:
- Cepat. Ini dapat mengirimkan lebih dari 2 GB data per detik berkat arsitektur clusternya.
- Gratis. HDFS adalah perangkat lunak sumber terbuka yang datang tanpa biaya lisensi atau dukungan.
- Dapat diandalkan. Sistem file menyimpan banyak salinan data dalam sistem terpisah untuk memastikannya selalu dapat diakses.
Keuntungan ini sangat signifikan saat menangani data besar dan dimungkinkan dengan cara khusus HDFS menangani data.
Bagaimana HDFS Menyimpan Data?
HDFS membagi file menjadi blok dan menyimpan setiap blok pada DataNode. Beberapa DataNodes ditautkan ke master node di cluster, NameNode. Node master mendistribusikan replika blok data ini di seluruh cluster. Itu juga menginstruksikan pengguna di mana menemukan informasi yang diinginkan.
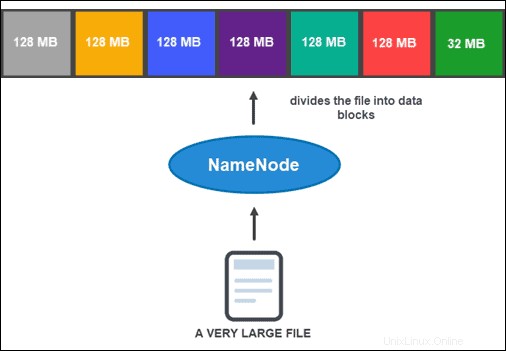
Namun, sebelum NameNode dapat membantu Anda menyimpan dan mengelola data, terlebih dahulu perlu mempartisi file menjadi blok data yang lebih kecil dan dapat dikelola. Proses ini disebut pemisahan blok data .
Pemisahan Blok Data
Secara default, ukuran blok tidak boleh lebih dari 128 MB. Jumlah blok tergantung pada ukuran awal file. Semua kecuali blok terakhir berukuran sama (128 MB), sedangkan yang terakhir adalah sisa file.
Misalnya, file 800 MB dipecah menjadi tujuh blok data. Enam dari tujuh blok berukuran 128 MB, sedangkan blok data ketujuh adalah 32 MB sisanya.
Kemudian, setiap blok direplikasi menjadi beberapa salinan.
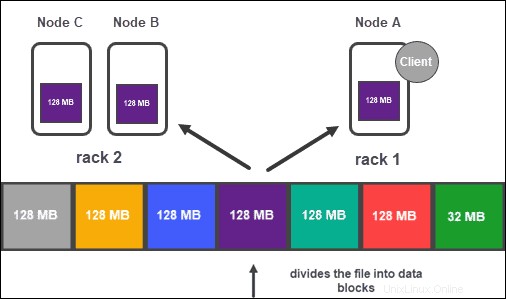
Replikasi Data
Berdasarkan konfigurasi cluster, NameNode membuat sejumlah salinan dari setiap blok data menggunakan metode replikasi .
Disarankan untuk memiliki setidaknya tiga replika, yang juga merupakan pengaturan default. Node master menyimpannya ke DataNodes terpisah dari cluster. Status node dipantau secara ketat untuk memastikan data selalu tersedia.
Untuk memastikan aksesibilitas tinggi, keandalan, dan toleransi kesalahan, pengembang menyarankan untuk menyiapkan tiga replika menggunakan topologi berikut:
- Simpan replika pertama pada node tempat klien berada.
- Kemudian, simpan replika kedua di rak yang berbeda.
- Terakhir, simpan replika ketiga pada rak yang sama dengan replika kedua, tetapi pada simpul yang berbeda.
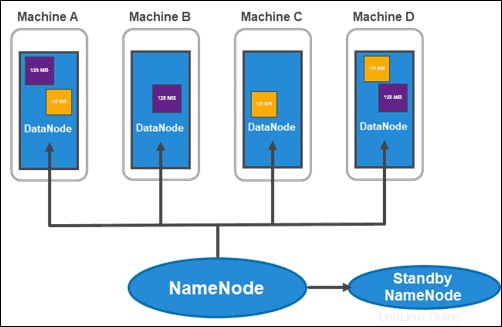
Arsitektur HDFS:NameNodes dan DataNodes
HDFS memiliki arsitektur master-slave. Node master adalah NameNode , yang mengelola lebih dari beberapa node slave dalam cluster, yang dikenal sebagai DataNodes .
NameNodes
Hadoop 2.x memperkenalkan kemungkinan memiliki beberapa NameNodes per rak. Kebaruan ini cukup signifikan karena memiliki node master tunggal dengan semua informasi di dalam cluster menimbulkan kerentanan besar.
Cluster biasa terdiri dari dua NameNodes:
- Node Nama yang aktif
- dan NameNode siaga
Sementara yang pertama menangani semua operasi klien dalam cluster, yang kedua tetap sinkron dengan semua pekerjaannya jika ada kebutuhan untuk failover.
The NameNode aktif melacak metadata setiap blok data dan replikanya. Ini termasuk nama file, izin, ID, lokasi, dan jumlah replika. Itu menyimpan semua informasi dalam fsimage , gambar namespace yang disimpan di memori lokal sistem file. Selain itu, ia memelihara log transaksi yang disebut EditLogs , yang merekam semua perubahan yang dibuat pada sistem.
Tujuan utama Stanby NameNode adalah untuk memecahkan masalah titik tunggal kegagalan. Itu membaca setiap perubahan yang dibuat pada EditLogs dan menerapkannya ke NameSpace (file dan direktori dalam data). Jika master node gagal, layanan Zookeeper melakukan failover yang memungkinkan standby untuk mempertahankan sesi aktif.
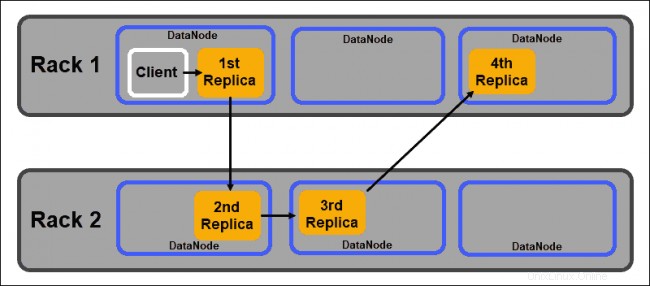
DataNode
DataNodes adalah daemon budak yang menyimpan blok data yang ditetapkan oleh NameNode. Seperti disebutkan di atas, pengaturan default memastikan setiap blok data memiliki tiga replika. Anda dapat mengubah jumlah replika, namun tidak disarankan untuk kurang dari tiga.
Replika harus didistribusikan sesuai dengan Rack Awareness Hadoop kebijakan yang menyatakan bahwa:
- Jumlah replika harus lebih banyak dari jumlah rak.
- Satu DataNode hanya dapat menyimpan satu replika blok data.
- Satu rak tidak dapat menyimpan lebih dari dua replika blok data.
Dengan mengikuti panduan ini, Anda dapat:
- Maksimalkan bandwidth jaringan.
- Melindungi dari kehilangan data.
- Tingkatkan performa dan keandalan.
Fitur Utama HDFS
Ini adalah karakteristik utama dari Sistem File Terdistribusi Hadoop:
1. Mengelola data besar. HDFS sangat baik dalam menangani kumpulan data besar dan memberikan solusi yang tidak dapat dilakukan oleh sistem file tradisional. Ini dilakukan dengan memisahkan data ke dalam blok yang dapat dikelola yang memungkinkan waktu pemrosesan yang cepat.
2. Sadar akan rak. Ini mengikuti pedoman kesadaran rak yang memastikan sistem sangat tersedia dan efisien.
3. Toleran terhadap kesalahan. Karena data disimpan di beberapa rak dan node, data tersebut direplikasi. Ini berarti bahwa jika salah satu mesin dalam cluster gagal, replika data tersebut akan tersedia dari node yang berbeda.
4. Dapat diskalakan. Anda dapat menskalakan sumber daya sesuai dengan ukuran sistem file Anda. HDFS mencakup mekanisme skalabilitas vertikal dan horizontal.
Penggunaan Kehidupan Nyata HDFS
Perusahaan yang berurusan dengan data dalam jumlah besar telah lama mulai bermigrasi ke Hadoop, salah satu solusi terkemuka untuk memproses data besar karena kemampuan penyimpanan dan analitiknya.
Layanan keuangan. Sistem File Terdistribusi Hadoop dirancang untuk mendukung data yang diharapkan tumbuh secara eksponensial. Sistem ini dapat diskalakan tanpa bahaya memperlambat pemrosesan data yang rumit.
Eceran. Karena mengetahui pelanggan Anda adalah komponen penting untuk sukses di industri ritel, banyak perusahaan menyimpan sejumlah besar data pelanggan terstruktur dan tidak terstruktur. Mereka menggunakan Hadoop untuk melacak dan menganalisis data yang dikumpulkan untuk membantu merencanakan inventaris, harga, kampanye pemasaran, dan proyek lainnya di masa mendatang.
Telekomunikasi. Industri telekomunikasi mengelola sejumlah besar data dan harus memproses dalam skala petabyte. Ini menggunakan analitik Hadoop untuk mengelola catatan data panggilan, analitik lalu lintas jaringan, dan proses terkait telekomunikasi lainnya.
Industri energi. Industri energi selalu mencari cara untuk meningkatkan efisiensi energi. Itu bergantung pada sistem seperti Hadoop dan sistem filenya untuk membantu menganalisis dan memahami pola dan praktik konsumsi.
Asuransi. Perusahaan asuransi kesehatan bergantung pada analisis data. Hasil ini menjadi dasar bagaimana mereka merumuskan dan mengimplementasikan kebijakan. Bagi perusahaan asuransi, wawasan tentang sejarah klien sangat berharga. Memiliki kemampuan untuk memelihara database yang mudah diakses sambil terus berkembang adalah alasan mengapa begitu banyak orang beralih ke Apache Hadoop.