Pendahuluan
Apache Hadoop adalah kerangka kerja yang sangat sukses yang berhasil memecahkan banyak tantangan yang ditimbulkan oleh data besar. Solusi efisien ini mendistribusikan daya penyimpanan dan pemrosesan ke ribuan node dalam sebuah cluster. Platform Hadoop yang dikembangkan sepenuhnya mencakup kumpulan alat yang menyempurnakan kerangka kerja inti Hadoop dan memungkinkannya mengatasi hambatan apa pun.
Arsitektur yang mendasari dan peran banyak alat yang tersedia dalam ekosistem Hadoop terbukti rumit bagi pendatang baru.
Artikel ini menggunakan banyak diagram dan deskripsi langsung untuk membantu Anda menjelajahi ekosistem Apache Hadoop yang menarik.

Ikhtisar Arsitektur Hadoop
Data besar, dengan volume yang sangat besar dan struktur data yang bervariasi telah membanjiri kerangka kerja dan alat jaringan tradisional. Menggunakan perangkat keras berperforma tinggi dan server khusus dapat membantu, tetapi mereka tidak fleksibel dan memiliki harga yang cukup mahal.
Hadoop berhasil memproses dan menyimpan data dalam jumlah besar dengan menggunakan perangkat keras komoditas yang saling terhubung dan terjangkau. Ratusan atau bahkan ribuan server khusus berbiaya rendah bekerja sama untuk menyimpan dan memproses data dalam satu ekosistem.
Sistem File Terdistribusi Hadoop (HDFS), BENANG , dan MapReduce berada di jantung ekosistem itu. HDFS adalah kumpulan protokol yang digunakan untuk menyimpan kumpulan data besar, sedangkan MapReduce secara efisien memproses data yang masuk.
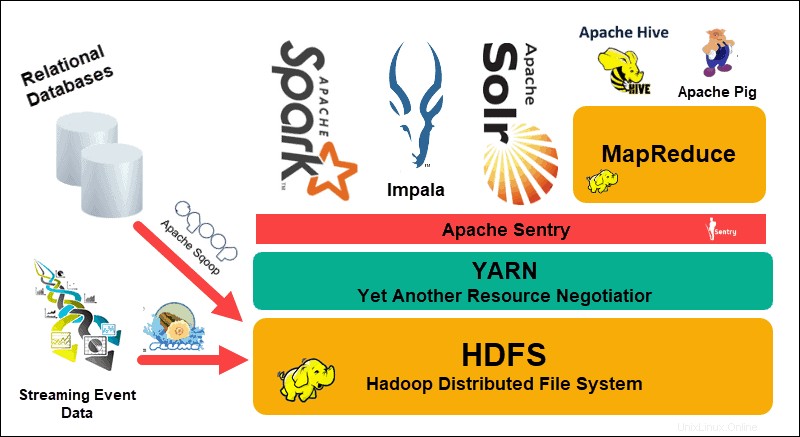
Sebuah cluster Hadoop terdiri dari satu, atau beberapa, Master Node dan banyak lagi yang disebut Slave Node. HDFS dan MapReduce membentuk fondasi fleksibel yang dapat ditingkatkan secara linier dengan menambahkan node tambahan. Namun, kompleksitas data besar berarti selalu ada ruang untuk perbaikan.
Yang Lain Negosiator Sumber Daya (BENANG) dibuat untuk meningkatkan manajemen sumber daya dan proses penjadwalan di cluster Hadoop. Pengenalan YARN, dengan antarmuka generiknya, membuka pintu bagi alat pemrosesan data lainnya untuk dimasukkan ke dalam ekosistem Hadoop.
Komunitas pengembang yang dinamis telah menciptakan banyak proyek Apache sumber terbuka untuk melengkapi Hadoop. Banyak dari solusi ini memiliki nama yang menarik dan kreatif seperti Apache Hive, Impala, Pig, Sqoop, Spark, dan Flume. Alat-alat ini mengkompilasi dan memproses berbagai tipe data. Mereka juga menyediakan antarmuka yang ramah pengguna, layanan pengiriman pesan, dan meningkatkan kecepatan pemrosesan cluster.
Kumpulan perangkat lunak yang diperluas, dengan HDFS, YARN, dan MapReduce pada intinya, menjadikan Hadoop solusi yang tepat untuk memproses data besar.
Memahami Lapisan Arsitektur Hadoop
Memisahkan elemen sistem terdistribusi ke dalam lapisan fungsional membantu merampingkan pengelolaan dan pengembangan data. Pengembang dapat bekerja pada kerangka kerja tanpa berdampak negatif pada proses lain di ekosistem yang lebih luas.
Hadoop dapat dibagi menjadi empat (4) lapisan yang berbeda.
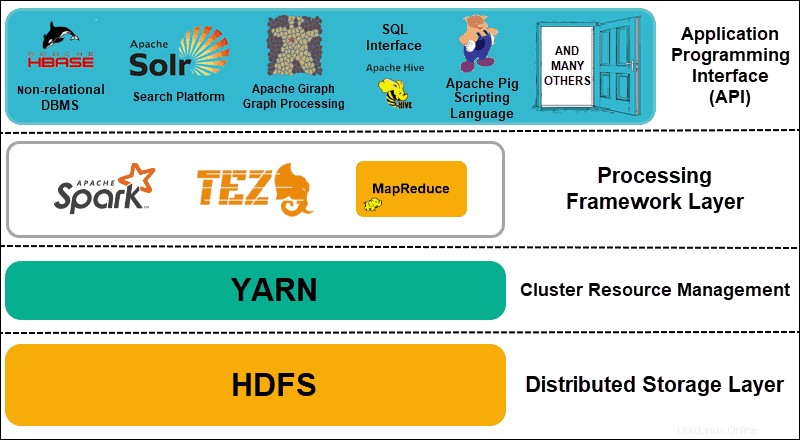
1. Lapisan Penyimpanan Terdistribusi
Setiap node dalam cluster Hadoop memiliki ruang disk, memori, bandwidth, dan pemrosesannya sendiri. Data yang masuk dibagi menjadi blok data individual, yang kemudian disimpan dalam lapisan penyimpanan terdistribusi HDFS. HDFS mengasumsikan bahwa setiap drive disk dan node slave dalam cluster tidak dapat diandalkan. Sebagai tindakan pencegahan, HDFS menyimpan tiga salinan dari setiap kumpulan data di seluruh cluster. Node master HDFS (NameNode ) menyimpan metadata untuk blok data individual dan semua replikanya.
2. Manajemen Sumber Daya Klaster
Hadoop perlu mengoordinasikan node dengan sempurna sehingga aplikasi dan pengguna yang tak terhitung jumlahnya dapat berbagi sumber daya mereka secara efektif. Awalnya, MapReduce menangani manajemen sumber daya dan pemrosesan data. YARN memisahkan kedua fungsi ini. Sebagai alat manajemen sumber daya de-facto untuk Hadoop, YARN sekarang dapat mengalokasikan sumber daya ke berbagai kerangka kerja yang ditulis untuk Hadoop. Ini termasuk proyek seperti Apache Pig, Hive, Giraph, Zookeeper, serta MapReduce itu sendiri.
3. Lapisan Kerangka Pemrosesan
Lapisan pemrosesan terdiri dari kerangka kerja yang menganalisis dan memproses kumpulan data yang masuk ke dalam cluster. Kumpulan data terstruktur dan tidak terstruktur dipetakan, diacak, diurutkan, digabungkan, dan direduksi menjadi blok data yang lebih kecil yang dapat dikelola. Operasi ini tersebar di beberapa node sedekat mungkin dengan server tempat data berada. Kerangka kerja komputasi seperti Spark, Storm, Tez sekarang memungkinkan pemrosesan waktu nyata, pemrosesan kueri interaktif, dan opsi pemrograman lain yang membantu mesin MapReduce dan memanfaatkan HDFS jauh lebih efisien.
4. Antarmuka Pemrograman Aplikasi
Pengenalan YARN di Hadoop 2 telah mengarah pada pembuatan kerangka kerja pemrosesan dan API baru. Data besar terus berkembang dan berbagai alat perlu mengikuti pertumbuhan itu. Proyek yang berfokus pada platform pencarian, streaming data, antarmuka yang mudah digunakan, bahasa pemrograman, pengiriman pesan, failover, dan keamanan adalah bagian rumit dari ekosistem Hadoop yang komprehensif.
Penjelasan HDFS
Sistem File Terdistribusi Hadoop (HDFS) dirancang dengan toleransi kesalahan. Data disimpan dalam blok data individual dalam tiga salinan terpisah di beberapa node dan rak server. Jika sebuah node atau bahkan seluruh rak gagal, dampaknya pada sistem yang lebih luas dapat diabaikan.
DataNode memproses dan menyimpan blok data, sementara NameNodes mengelola banyak DataNodes, memelihara metadata blok data, dan mengontrol akses klien.
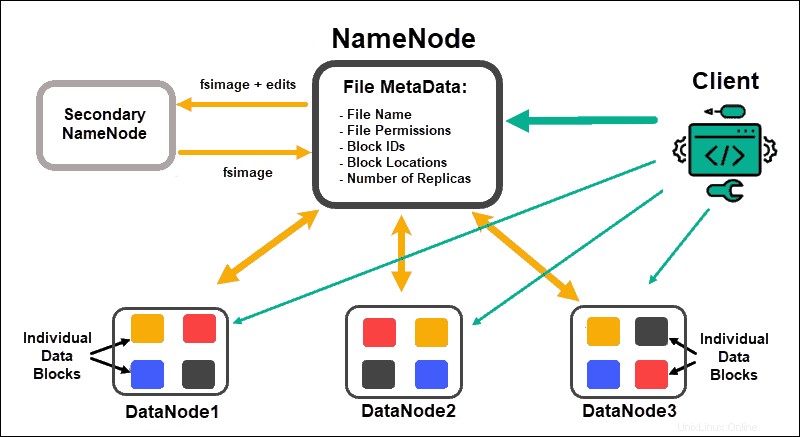
NameNode
Awalnya, data dipecah menjadi blok data abstrak. Metadata file untuk blok ini, yang mencakup nama file, izin file, ID, lokasi, dan jumlah replika, disimpan dalam fsimage, pada memori lokal NameNode.
Jika NameNode gagal, HDFS tidak akan dapat menemukan set data mana pun yang didistribusikan di seluruh DataNodes. Ini menjadikan NameNode sebagai satu-satunya titik kegagalan untuk seluruh cluster. Kerentanan ini diatasi dengan menerapkan Node Nama Sekunder atau Node Nama Siaga.
Node Nama Sekunder
Sekunder NameNode berfungsi sebagai solusi cadangan utama dalam versi Hadoop awal. Sekunder NameNode, sering kali, mengunduh instance fsimage saat ini dan mengedit log dari NameNode dan menggabungkannya. Fsimage yang diedit kemudian dapat diambil dan dipulihkan di NameNode utama.
Kegagalan bukanlah proses otomatis karena administrator perlu memulihkan data dari Node Nama Sekunder secara manual.
Node Nama Siaga
Ketersediaan Tinggi fitur diperkenalkan di Hadoop 2.0 dan versi berikutnya untuk menghindari downtime jika terjadi kegagalan NameNode. Fitur ini memungkinkan Anda untuk mempertahankan dua NameNode yang berjalan pada node master khusus yang terpisah.
Standby NameNode adalah failover otomatis jika NameNode Aktif menjadi tidak tersedia. Standby NameNode juga melakukan proses check-pointing. Karena properti ini, Node Nama Sekunder dan Siaga tidak kompatibel. Sebuah cluster Hadoop dapat mempertahankan salah satu atau yang lain.
Penjaga kebun binatang
Zookeeper adalah alat ringan yang mendukung ketersediaan dan redundansi tinggi. Standby NameNode mempertahankan sesi aktif dengan daemon Zookeeper.
Jika NameNode Aktif terputus-putus, daemon Zookeeper mendeteksi kegagalan dan melakukan proses failover ke NameNode baru. Gunakan Zookeeper untuk mengotomatiskan failover dan meminimalkan dampak kegagalan NameNode pada cluster.
DataNode
Setiap DataNode dalam sebuah cluster menggunakan proses latar belakang untuk menyimpan blok data individual di server slave.
Secara default, HDFS menyimpan tiga salinan dari setiap blok data pada DataNodes yang terpisah. NameNode menggunakan kebijakan penempatan yang sadar rak. Ini berarti DataNodes yang berisi replika blok data tidak semuanya dapat ditempatkan di rak server yang sama.
DataNode berkomunikasi dan menerima instruksi dari NameNode kira-kira dua puluh kali dalam satu menit. Juga, ini melaporkan status dan kesehatan blok data yang terletak di node itu sekali dalam satu jam. Berdasarkan informasi yang diberikan, NameNode dapat meminta DataNode untuk membuat replika tambahan, menghapusnya, atau mengurangi jumlah blok data yang ada pada node.
Kebijakan Penempatan Rack Aware
Salah satu tujuan utama dari sistem penyimpanan terdistribusi seperti HDFS adalah untuk mempertahankan ketersediaan dan replikasi yang tinggi. Oleh karena itu, blok data perlu didistribusikan tidak hanya pada DataNodes yang berbeda tetapi juga pada node yang terletak di rak server yang berbeda.
Ini memastikan bahwa kegagalan seluruh rak tidak menghentikan semua replika data. HDFS NameNode mempertahankan kebijakan penempatan replika rak-aware default:
- Replika blok data pertama ditempatkan pada node yang sama dengan klien.
- Replika kedua secara otomatis ditempatkan pada DataNode acak di rak yang berbeda.
- Replika ketiga ditempatkan di DataNode terpisah di rak yang sama dengan replika kedua.
- Setiap replika tambahan disimpan di DataNodes acak di seluruh cluster.
Kebijakan penempatan rak ini hanya mempertahankan satu replika per node dan menetapkan batas dua replika per rak server.
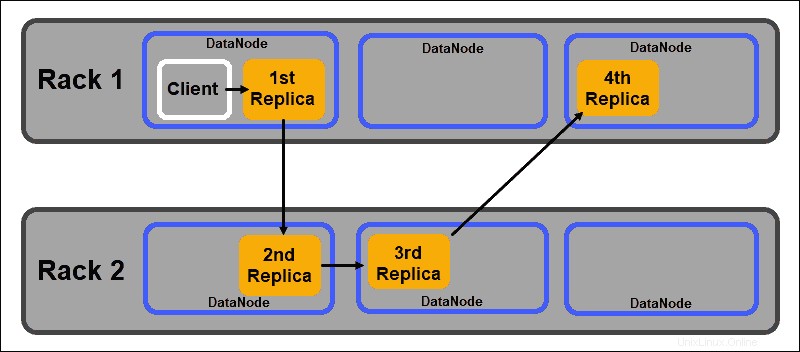
Kegagalan rak jauh lebih jarang daripada kegagalan simpul. HDFS memastikan keandalan yang tinggi dengan selalu menyimpan setidaknya satu replika blok data di DataNode di rak yang berbeda.
BENANG Dijelaskan
YARN (Yet Another Resource Negotiator) adalah sumber daya manajemen cluster default untuk Hadoop 2 dan Hadoop 3. Dalam versi Hadoop sebelumnya, MapReduce digunakan untuk melakukan pemrosesan data dan alokasi sumber daya. Seiring waktu, kebutuhan untuk membagi pemrosesan dan manajemen sumber daya mengarah pada pengembangan YARN.
Peran alokasi sumber daya YARN menempatkannya di antara lapisan penyimpanan, yang diwakili oleh HDFS, dan mesin pemrosesan MapReduce. YARN juga menyediakan antarmuka generik yang memungkinkan Anda mengimplementasikan mesin pemrosesan baru untuk berbagai tipe data.
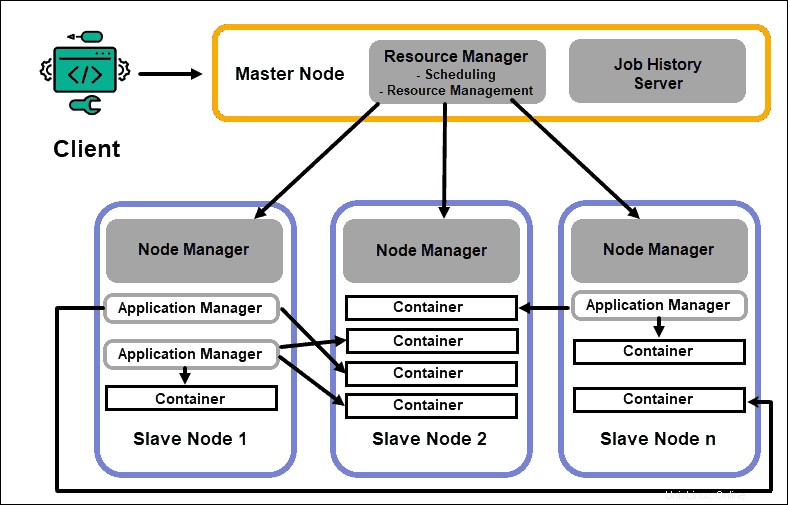
Pengelola Sumber Daya
Daemon ResourceManager (RM) mengontrol semua sumber daya pemrosesan di cluster Hadoop. Tujuan utamanya adalah untuk menunjuk sumber daya untuk aplikasi individu yang terletak di node budak. Ini mempertahankan gambaran global dari proses yang sedang berlangsung dan yang direncanakan, menangani permintaan sumber daya, dan menjadwalkan serta menetapkan sumber daya yang sesuai. ResourceManager sangat penting untuk framework Hadoop dan harus berjalan pada node master khusus.
Satu-satunya fokus RM adalah pada penjadwalan beban kerja. Tidak seperti MapReduce, ia tidak tertarik pada failover atau tugas pemrosesan individu. Pemisahan tugas di YARN inilah yang membuat Hadoop secara inheren dapat diskalakan dan mengubahnya menjadi platform komputasi yang dikembangkan sepenuhnya.
Pengelola Node
Setiap node budak memiliki layanan pemrosesan NodeManager dan layanan penyimpanan DataNode. Bersama-sama mereka membentuk tulang punggung sistem terdistribusi Hadoop.
DataNode, seperti yang disebutkan sebelumnya, adalah elemen HDFS dan dikendalikan oleh NameNode. NodeManager, dengan cara yang sama, bertindak sebagai budak dari ResourceManager. Fungsi utama daemon NodeManager adalah untuk melacak data pemrosesan-sumber daya pada node budaknya dan mengirim laporan reguler ke ResourceManager.
Wadah
Sumber daya pemrosesan dalam kluster Hadoop selalu digunakan dalam wadah. Wadah memiliki memori, file sistem, dan ruang pemrosesan.
Deployment container bersifat umum dan dapat menjalankan resource kustom apa pun yang diminta pada sistem apa pun. Jika jumlah sumber daya cluster yang diminta berada dalam batas yang dapat diterima, RM menyetujui dan menjadwalkan container tersebut untuk disebarkan.
Proses container pada node slave awalnya disediakan, dipantau, dan dilacak oleh NodeManager pada node slave tertentu.
Master Aplikasi
Setiap wadah pada node budak memiliki Master Aplikasi khusus. Master Aplikasi juga dikerahkan dalam wadah. Bahkan MapReduce memiliki Master Aplikasi yang mengeksekusi peta dan mengurangi tugas.
Selama aktif, Master Aplikasi mengirim pesan ke Manajer Sumber Daya tentang statusnya saat ini dan status aplikasi yang dipantaunya. Berdasarkan informasi yang diberikan, Resource Manager menjadwalkan resource tambahan atau menetapkannya di tempat lain di cluster jika tidak lagi diperlukan.
Master Aplikasi mengawasi siklus hidup penuh aplikasi, mulai dari meminta kontainer yang dibutuhkan dari RM hingga mengirimkan permintaan sewa kontainer ke NodeManager.
Server JobHistory
Server JobHistory memungkinkan pengguna untuk mengambil informasi tentang aplikasi yang telah menyelesaikan aktivitas mereka. REST API menyediakan interoperabilitas dan dapat secara dinamis memberi tahu pengguna tentang pekerjaan saat ini dan yang telah diselesaikan yang dilayani oleh server yang bersangkutan.
Bagaimana BENANG Bekerja?
Alur kerja dasar untuk penerapan di YARN dimulai saat aplikasi klien mengirimkan permintaan ke ResourceManager.
- Pengelola Sumber Daya menginstruksikan NodeManager untuk memulai Master Aplikasi untuk permintaan ini, yang kemudian dimulai dalam wadah.
- Master Aplikasi . yang baru dibuat mendaftarkan dirinya dengan RM . Master Aplikasi melanjutkan untuk menghubungi HDFS NameNode dan menentukan lokasi blok data yang dibutuhkan serta menghitung jumlah peta dan mengurangi tugas yang diperlukan untuk memproses data.
- Master Aplikasi kemudian meminta sumber daya yang dibutuhkan dari RM dan terus mengomunikasikan persyaratan sumber daya sepanjang siklus hidup container.
- RM menjadwalkan sumber daya bersama dengan permintaan dari semua Application Masters . lainnya dan mengantri permintaan mereka. Saat sumber daya tersedia, RM membuatnya tersedia untuk Master Aplikasi pada node budak tertentu.
- Pengelola Aplikasi menghubungi NodeManager untuk node budak itu dan memintanya untuk membuat wadah dengan menyediakan variabel, token otentikasi, dan string perintah untuk proses tersebut. Berdasarkan permintaan itu, NodeManager membuat dan memulai wadah .
- Pengelola Aplikasi kemudian memantau proses dan bereaksi jika terjadi kegagalan dengan memulai kembali proses pada slot berikutnya yang tersedia. Jika gagal setelah empat upaya berbeda, seluruh pekerjaan gagal. Selama proses ini, Manajer Aplikasi merespons permintaan status klien.
Setelah semua tugas selesai, Master Aplikasi mengirimkan hasilnya ke aplikasi klien, memberi tahu RM bahwa aplikasi telah menyelesaikan tugasnya, membatalkan pendaftarannya sendiri dari Resource Manager, dan menutup dirinya sendiri.
RM juga dapat menginstruksikan NameNode untuk menghentikan container tertentu selama proses jika terjadi perubahan prioritas pemrosesan.
Penjelasan MapReduce
MapReduce adalah algoritma pemrograman yang memproses data yang tersebar di seluruh cluster Hadoop. Seperti halnya proses di Hadoop, setelah pekerjaan MapReduce dimulai, ResourceManager meminta Master Aplikasi untuk mengelola dan memantau siklus hidup pekerjaan MapReduce.
Master Aplikasi menempatkan blok data yang diperlukan berdasarkan informasi yang disimpan di NameNode. AM juga menginformasikan ResourceManager untuk memulai pekerjaan MapReduce pada node yang sama dengan lokasi blok data. Bila memungkinkan, data diproses secara lokal pada node slave untuk mengurangi penggunaan bandwidth dan meningkatkan efisiensi cluster.
Data input dipetakan, diacak, dan kemudian direduksi menjadi hasil agregat. Output dari pekerjaan MapReduce disimpan dan direplikasi dalam HDFS.
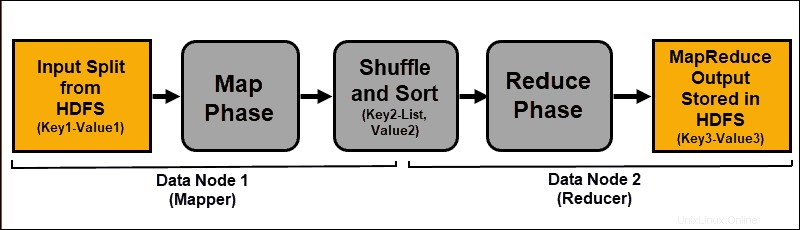
Server Hadoop yang melakukan tugas pemetaan dan pengurangan sering disebut sebagai Mappers dan Pengurang .
ResourceManager memutuskan berapa banyak pembuat peta yang akan digunakan. Keputusan ini tergantung pada ukuran data yang diproses dan blok memori yang tersedia di setiap server mapper.
Fase Peta
Proses pemetaan menyerap ekspresi logis individu dari data yang disimpan dalam blok data HDFS. Ekspresi ini dapat menjangkau beberapa blok data dan disebut pembagian input . Pemisahan input dimasukkan ke dalam proses pemetaan sebagai pasangan nilai kunci .
Tugas mapper melewati setiap pasangan nilai kunci dan membuat kumpulan pasangan nilai kunci baru, berbeda dari data input asli. Bermacam-macam lengkap dari semua pasangan nilai kunci mewakili output dari tugas pembuat peta.
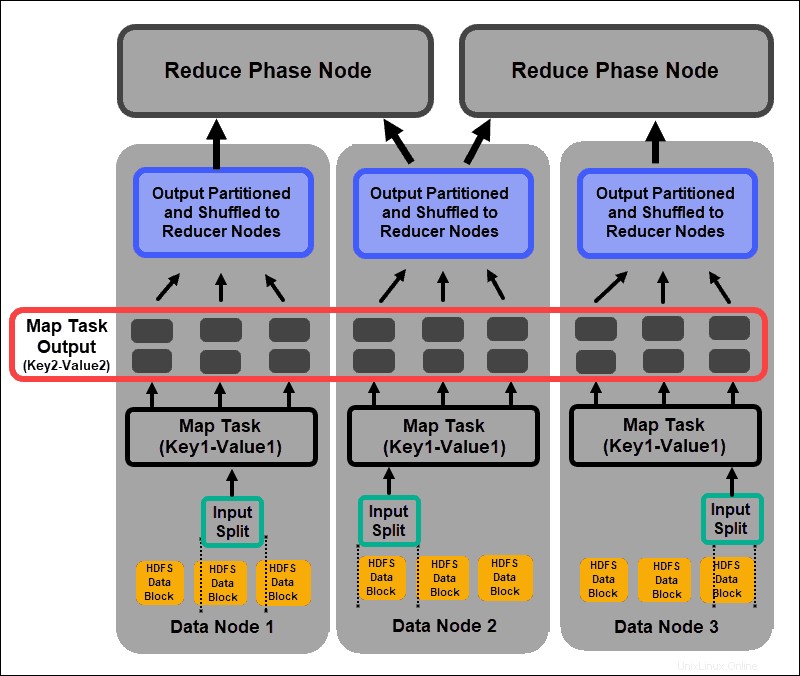
Berdasarkan kunci dari setiap pasangan, data dikelompokkan, dipartisi, dan diacak ke node peredam.
Fase Acak dan Urutkan
Acak adalah proses di mana hasil dari semua tugas peta disalin ke node peredam. Penyalinan output tugas peta adalah satu-satunya pertukaran data antar node selama seluruh pekerjaan MapReduce.
Output dari tugas peta perlu diatur untuk meningkatkan efisiensi fase pengurangan. Pasangan nilai kunci yang dipetakan, yang diacak dari node pembuat peta, disusun menurut kunci dengan nilai yang sesuai. Fase pengurangan dimulai setelah input diurutkan dengan kunci dalam satu file input.
Fase shuffle dan sort berjalan secara paralel. Bahkan saat output peta diambil dari node mapper, mereka dikelompokkan dan diurutkan pada node peredam.
Kurangi Fase
Keluaran peta dikocok dan diurutkan ke dalam satu file masukan pereduksi yang terletak di simpul peredam. Fungsi pengurangan menggunakan file input untuk menggabungkan nilai berdasarkan kunci yang dipetakan terkait. Keluaran dari proses reduksi adalah pasangan nilai kunci baru. Hasil ini mewakili output dari seluruh pekerjaan MapReduce dan, secara default, disimpan dalam HDFS.
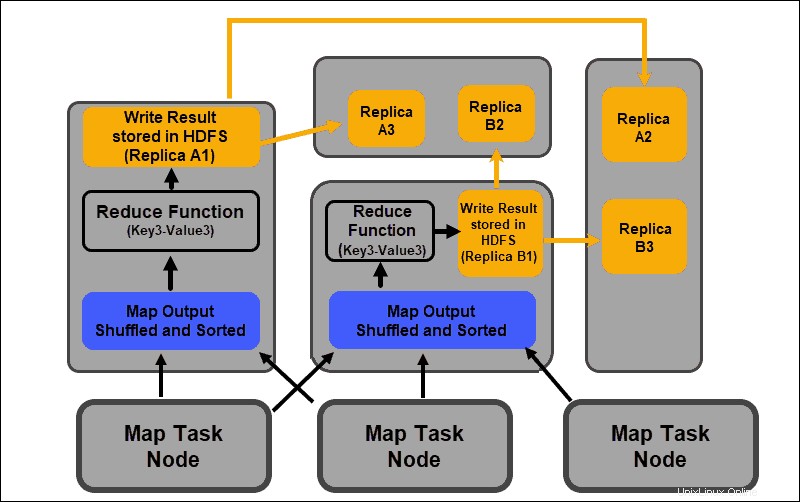
Semua tugas pengurangan berlangsung secara bersamaan dan bekerja secara independen satu sama lain. Tugas pengurangan juga opsional.
Ada contoh di mana hasil tugas peta adalah hasil yang diinginkan dan tidak perlu menghasilkan nilai output tunggal.
Praktik Terbaik untuk Menerapkan Hadoop
Bagian berikut menjelaskan bagaimana hardware yang mendasari, izin pengguna, dan pemeliharaan cluster yang seimbang dan andal dapat membantu Anda memaksimalkan ekosistem Hadoop.
Sesuaikan Izin Pengguna Hadoop
Protokol jaringan Kerberos adalah sistem otorisasi utama di Hadoop. Ini memastikan bahwa hanya node dan pengguna terverifikasi yang memiliki akses dan beroperasi di dalam cluster.
Setelah Anda menginstal dan mengonfigurasi Pusat Distribusi Kunci Kerberos, Anda perlu membuat beberapa perubahan pada file konfigurasi Hadoop. Hadoop situs-inti.xml file mendefinisikan parameter untuk seluruh cluster Hadoop. Setel hadoop.security.authentication parameter dalam core-site.xml ke kerberos . Properti yang sama perlu disetel ke true untuk mengaktifkan otorisasi layanan.
Daftar kontrol akses di hadoop-policy-xml file juga dapat diedit untuk memberikan tingkat akses yang berbeda kepada pengguna tertentu. Mencapai keseimbangan antara hak istimewa pengguna yang diperlukan dan memberikan terlalu banyak hak istimewa bisa jadi sulit dengan alat baris perintah dasar.
Sebaiknya gunakan kerangka kerja keamanan tambahan seperti Apache Pengawas atau Apache Sentry . Alat ini membantu Anda mengelola semua tugas terkait keamanan dari lingkungan terpusat yang ramah pengguna. Gunakan mereka untuk memberikan otorisasi khusus untuk tugas dan pengguna sambil tetap mengontrol proses secara penuh.
Kluster Hadoop Seimbang
Sistem terdistribusi seperti Hadoop adalah lingkungan yang dinamis. Menambahkan node baru atau menghapus yang lama dapat membuat ketidakseimbangan sementara dalam sebuah cluster. Blok data dapat menjadi kurang direplikasi.
Tujuan Anda adalah menyebarkan data sekonsisten mungkin di seluruh node slave dalam sebuah cluster. Gunakan utilitas penyeimbang cluster Hadoop untuk mengubah pengaturan yang telah ditentukan sebelumnya. Tentukan kebijakan penyeimbangan Anda dengan hdfs balancer memerintah. Perintah ini dan opsinya memungkinkan Anda untuk mengubah ambang batas kapasitas disk node.
Ukuran blok default mulai dari Hadoop 2.x adalah 128MB. Hadoop memungkinkan pengguna untuk mengubah pengaturan ini. Pertimbangkan untuk mengubah ukuran blok data default jika memproses data dalam jumlah yang cukup besar; jika tidak, jumlah pekerjaan yang dimulai dapat membanjiri cluster Anda.
Jika Anda menambah ukuran blok data, input ke tugas peta akan lebih besar, dan tugas peta yang dimulai akan lebih sedikit. Ini, pada gilirannya, berarti bahwa fase acak memiliki throughput yang jauh lebih baik saat mentransfer data ke node peredam. Penyesuaian sederhana ini dapat mengurangi waktu yang dibutuhkan untuk menyelesaikan tugas MapReduce.
Menskalakan Hadoop (Perangkat Keras)
NameNode adalah elemen penting dari cluster Hadoop Anda. Libatkan inti pemrosesan sebanyak mungkin untuk node ini. Jumlah RAM menentukan berapa banyak data yang dibaca dari memori node. Jika Anda membebani sumber daya yang tersedia untuk Master Node Anda, Anda membatasi kemampuan cluster Anda untuk tumbuh.
Catu daya redundan harus selalu disediakan untuk Master Node. Cobalah untuk tidak menggunakan catu daya yang berlebihan dan sumber daya perangkat keras yang berharga untuk node data. Mereka adalah bagian penting dari ekosistem Hadoop, namun, mereka dapat dibuang. Server khusus yang terjangkau, dengan kemampuan pemrosesan menengah, ideal untuk node data karena mengkonsumsi lebih sedikit daya dan menghasilkan lebih sedikit panas.
Kemampuan penskalaan Hadoop adalah kekuatan pendorong utama di balik implementasinya yang luas. Anda harus selalu memiliki cukup ruang agar cluster Anda dapat berkembang. Menambahkan node atau ruang disk baru dengan cepat membutuhkan daya, jaringan, dan pendinginan tambahan. Semua ini terbukti sangat sulit tanpa perencanaan yang cermat untuk kemungkinan pertumbuhan di masa depan.
Menskalakan Hadoop (Perangkat Lunak)
Proyek Hadoop baru sedang dikembangkan secara teratur dan yang sudah ada ditingkatkan dengan fitur yang lebih canggih.
Bahkan alat warisan sedang ditingkatkan untuk memungkinkan mereka mendapatkan manfaat dari ekosistem Hadoop. Selalu awasi perkembangan baru di bagian depan ini. Keragaman dan volume set data yang masuk mengharuskan pengenalan kerangka kerja tambahan.
Menerapkan alat baru yang mudah digunakan dapat memecahkan dilema teknis lebih cepat daripada mencoba membuat solusi khusus. Jangan menghindar dari perbaikan cepat komersial yang sudah dikembangkan. Pasar dipenuhi dengan vendor yang menawarkan Hadoop-as-a-service atau alat mandiri yang disesuaikan.
Keandalan Data dan Toleransi Kesalahan
Hdetak jantung adalah sinyal jabat tangan TCP berulang. DataNodes, yang terletak di setiap server budak, terus mengirim detak jantung ke NameNode yang terletak di server master. Kerangka waktu detak jantung default adalah tiga detik. Jika NameNode tidak menerima sinyal selama lebih dari sepuluh menit, DataNode akan dihapus, dan blok datanya dijadwalkan otomatis pada node yang berbeda.
Jangan turunkan frekuensi detak jantung untuk mencoba dan meringankan beban pada NameNode. Menjaga NameNodes 'informasi' sangat penting, bahkan dalam cluster yang sangat besar. Tanpa aliran detak jantung yang teratur dan sering, NameNode sangat terhambat dan tidak dapat mengontrol cluster secara efektif.
Untuk menghindari konsekuensi kesalahan yang serius, pertahankan pengaturan kesadaran rak default dan simpan replika blok data di seluruh rak server. Jika Anda kehilangan rak server, replika lainnya akan bertahan, dan dampaknya pada pemrosesan data minimal.