Pendahuluan
Spark DataFrame adalah struktur data terintegrasi dengan API yang mudah digunakan untuk menyederhanakan pemrosesan data besar terdistribusi. DataFrame tersedia untuk bahasa pemrograman tujuan umum seperti Java, Python, dan Scala.
Ini adalah ekstensi dari Spark RDD API yang dioptimalkan untuk menulis kode secara lebih efisien sambil tetap bertenaga.
Artikel ini menjelaskan apa itu Spark DataFrame, fitur, dan cara menggunakan Spark DataFrame saat mengumpulkan data.

Prasyarat
- Spark diinstal dan dikonfigurasi (Ikuti panduan kami:Cara menginstal Spark di Ubuntu, Cara menginstal Spark di Windows 10).
- Lingkungan yang dikonfigurasi untuk menggunakan Spark di Java, Python, atau Scala (panduan ini menggunakan Python).
Apa itu DataFrame?
DataFrame adalah abstraksi pemrograman dalam modul Spark SQL. DataFrames menyerupai tabel database relasional atau spreadsheet excel dengan header:data berada dalam baris dan kolom dari tipe data yang berbeda.
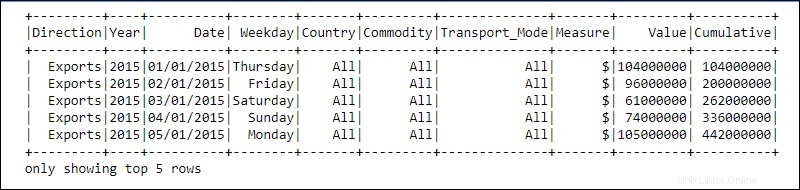
Pemrosesan dicapai menggunakan fungsi kompleks yang ditentukan pengguna dan fungsi manipulasi data yang sudah dikenal, seperti sortir, gabung, grup, dll.
Informasi untuk data terdistribusi disusun menjadi skema . Setiap kolom dalam DataFrame berisi kolom nama , tipe data, dan tidak dapat dibatalkan properti. Ketika nullable disetel ke benar , sebuah kolom menerima null properti juga.

Bagaimana Cara Kerja DataFrame?
DataFrame API adalah bagian dari modul Spark SQL. API menyediakan cara mudah untuk bekerja dengan data dalam kerangka kerja Spark SQL sambil berintegrasi dengan bahasa tujuan umum seperti Java, Python, dan Scala.
Meskipun ada kesamaan dengan kerangka data Python Pandas dan R, Spark melakukan sesuatu yang berbeda. API ini dibuat khusus untuk diintegrasikan dengan data skala besar untuk ilmu data dan pembelajaran mesin serta menghadirkan banyak pengoptimalan.
Spark DataFrames dapat didistribusikan ke beberapa cluster dan dioptimalkan dengan Catalyst. Pengoptimal Catalyst mengambil kueri (termasuk perintah SQL yang diterapkan ke DataFrames) dan membuat rencana komputasi paralel yang optimal.
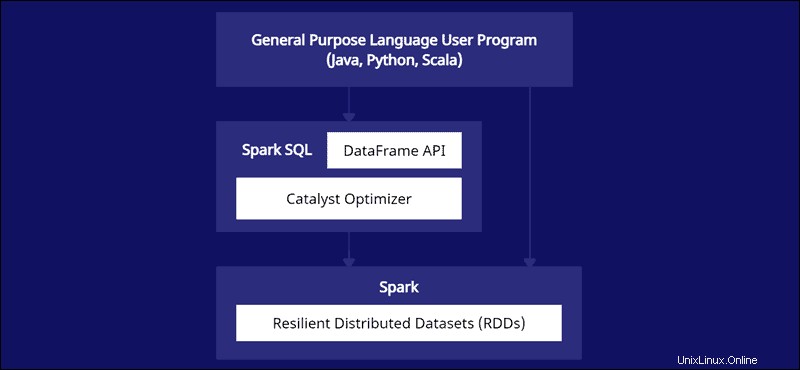
Jika Anda memiliki pengalaman bingkai data Python dan R, kode Spark DataFrame terlihat familier. Di sisi lain, jika Anda menggunakan Spark RDD (Resilient Distributed Dataset), memiliki informasi tentang struktur data memberikan peluang pengoptimalan.
Pembuat Spark merancang DataFrames untuk mengatasi tantangan data besar dengan cara yang paling efisien. Pengembang dapat memanfaatkan kekuatan komputasi terdistribusi dengan API yang sudah dikenal tetapi lebih dioptimalkan.
Fitur Spark DataFrames
Spark DataFrame hadir dengan banyak fitur berharga:
- Dukungan untuk berbagai format data, seperti Hive, CSV, XML, JSON, RDD, Cassandra, Parket, dll.
- Dukungan untuk integrasi dengan berbagai alat Big Data.
- Kemampuan untuk memproses kilobyte data pada mesin yang lebih kecil dan petabyte pada cluster.
- Pengoptimal katalis untuk pemrosesan data yang efisien di berbagai bahasa.
- Penanganan data terstruktur melalui tampilan skematik data.
- Manajemen memori khusus untuk mengurangi kelebihan beban dan meningkatkan kinerja dibandingkan dengan RDD.
- API untuk Java, R, Python, dan Spark.
Bagaimana Cara Membuat Spark DataFrame?
Ada beberapa metode untuk membuat Spark DataFrame. Berikut adalah contoh cara membuatnya dengan Python menggunakan lingkungan notebook Jupyter:
1. Inisialisasi dan buat sesi API:
#Add pyspark to sys.path and initialize
import findspark
findspark.init()
#Load the DataFrame API session into Spark and create a session
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()2. Buat data mainan sebagai daftar kamus:
#Generate toy data using a dictionary list
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
3. Buat DataFrame menggunakan createDataFrame berfungsi dan meneruskan data daftar:
#Create a DataFrame from the data list
df = spark.createDataFrame(data)4. Cetak skema dan tabel untuk melihat DataFrame yang dibuat:
#Print the schema and view the DataFrame in table format
df.printSchema()
df.show()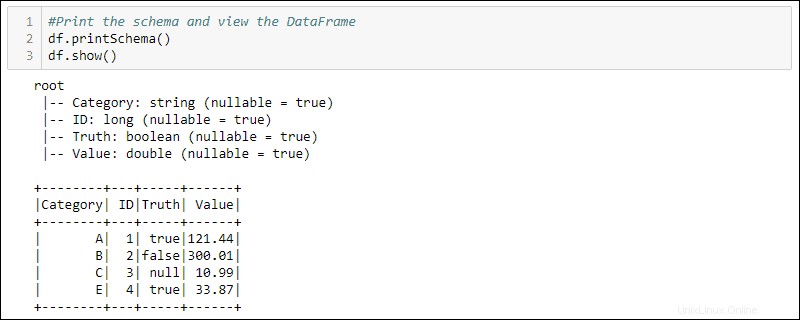
Cara Menggunakan DataFrames
Data terstruktur yang disimpan dalam DataFrame menyediakan dua metode manipulasi
- Menggunakan bahasa khusus domain
- Menggunakan kueri SQL.
Dua metode berikutnya menggunakan DataFrame dari contoh sebelumnya untuk memilih semua baris di mana kolom Kebenaran disetel ke true dan mengurutkan data menurut kolom Nilai.
Metode 1:Menggunakan Kueri Khusus Domain
Python menyediakan metode bawaan untuk memfilter dan menyortir data. Pilih kolom tertentu menggunakan df.<column name> :
df.filter(df.Truth == True).sort(df.Value).show()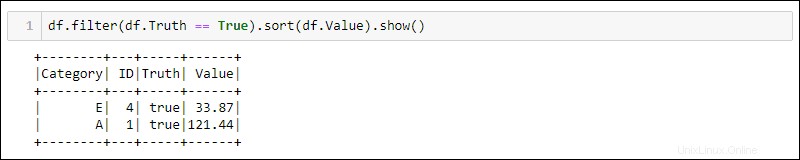
Metode 2:Menggunakan Kueri SQL
Untuk menggunakan kueri SQL dengan DataFrame, buat tampilan dengan createOrReplaceTempView metode bawaan dan jalankan kueri SQL menggunakan spark.sql metode:
df.createOrReplaceTempView('table')
spark.sql('''SELECT * FROM table WHERE Truth=true ORDER BY Value ASC''')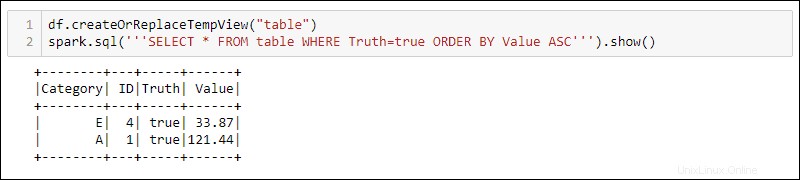
Output menunjukkan hasil kueri SQL yang diterapkan ke tampilan sementara DataFrame. Hal ini memungkinkan pembuatan beberapa tampilan dan kueri pada data yang sama untuk pemrosesan data yang kompleks.