Pendahuluan
Kerangka kerja pemrosesan data, seperti Apache Hadoop dan Spark, telah mendukung pengembangan Big Data. Kemampuan mereka untuk mengumpulkan data dalam jumlah besar dari aliran data yang berbeda sangat luar biasa, namun, mereka membutuhkan gudang data untuk menganalisis, mengelola, dan menanyakan semua data.
Apakah Anda tertarik untuk mempelajari lebih lanjut tentang apa itu gudang data dan terdiri dari apa?
Artikel ini menjelaskan arsitektur gudang data dan peran setiap komponen dalam sistem.
Apa itu Gudang Data?
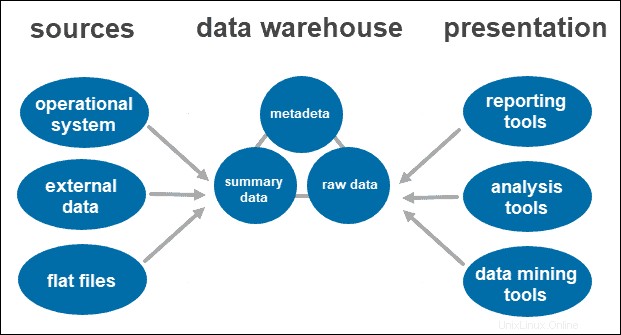
Gudang data (DW atau DWH) adalah sistem kompleks yang menyimpan data historis dan kumulatif yang digunakan untuk peramalan, pelaporan, dan analisis data. Ini melibatkan pengumpulan, pembersihan, dan transformasi data dari aliran data yang berbeda dan memuatnya ke dalam tabel fakta/dimensi.
Gudang data mewakili struktur data yang berorientasi subjek, terintegrasi, bervariasi waktu, dan tidak mudah berubah.
Berfokus pada subjek daripada operasi, DWH mengintegrasikan data dari berbagai sumber yang memberi pengguna satu sumber informasi dalam format yang konsisten. Karena non-volatile, ia mencatat semua perubahan data sebagai entri baru tanpa menghapus status sebelumnya. Fitur ini terkait erat dengan varian waktu, karena fitur ini menyimpan catatan data historis, memungkinkan Anda untuk memeriksa perubahan dari waktu ke waktu.
Semua properti ini membantu bisnis membuat laporan analitis yang diperlukan untuk mempelajari perubahan dan tren.
Arsitektur Gudang Data
Ada tiga cara Anda dapat membangun sistem gudang data. Pendekatan ini diklasifikasikan berdasarkan jumlah tingkatan dalam arsitektur. Oleh karena itu, Anda dapat memiliki:
- Arsitektur tingkat tunggal
- Arsitektur dua tingkat
- Arsitektur tiga tingkat
Arsitektur Data Warehouse Tingkat Tunggal
Arsitektur single-tier bukanlah pendekatan yang sering dilakukan. Tujuan utama memiliki arsitektur seperti itu adalah untuk menghilangkan redundansi dengan meminimalkan jumlah data yang disimpan.
Kerugian utamanya adalah tidak memiliki komponen yang memisahkan pemrosesan analitis dan transaksional.
Arsitektur Data Warehouse Dua Tingkat
Arsitektur dua tingkat mencakup area pementasan untuk semua sumber data, sebelum lapisan gudang data. Dengan menambahkan area staging antara sumber dan repositori penyimpanan, Anda memastikan semua data yang dimuat ke dalam gudang dibersihkan dan dalam format yang sesuai.
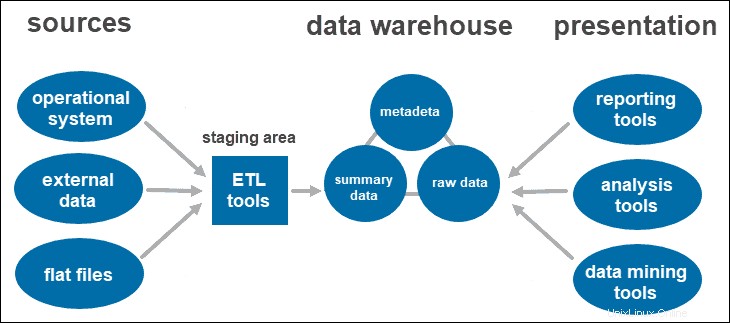
Pendekatan ini memiliki keterbatasan jaringan tertentu. Selain itu, Anda tidak dapat memperluasnya untuk mendukung lebih banyak pengguna.
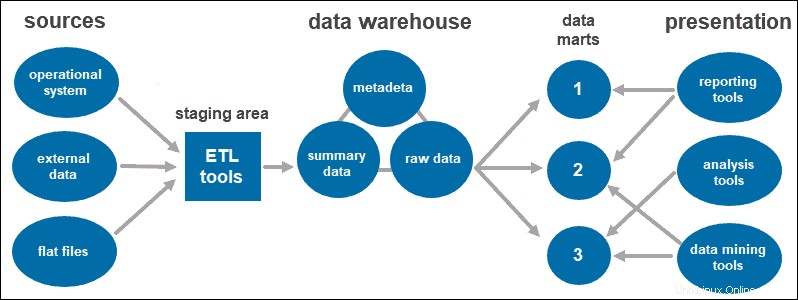
Arsitektur Gudang Data Tiga Tingkat
Pendekatan tiga tingkat adalah arsitektur yang paling banyak digunakan untuk sistem gudang data.
Pada dasarnya, ini terdiri dari tiga tingkatan:
- Tingkat bawah adalah database gudang, tempat data yang telah dibersihkan dan diubah dimuat.
- Tingkat menengah adalah lapisan aplikasi yang memberikan tampilan abstrak dari database. Ini mengatur data agar lebih cocok untuk analisis. Ini dilakukan dengan server OLAP, diimplementasikan menggunakan model ROLAP atau MOLAP.
- Tingkat teratas adalah tempat pengguna mengakses dan berinteraksi dengan data. Ini mewakili lapisan klien front-end. Anda dapat menggunakan alat pelaporan, kueri, analisis, atau alat penambangan data.
Komponen Gudang Data
Dari arsitektur yang diuraikan di atas, Anda melihat beberapa komponen tumpang tindih, sementara yang lain unik untuk jumlah tingkatan.
Di bawah ini Anda akan menemukan beberapa komponen gudang data yang paling penting dan perannya dalam sistem.
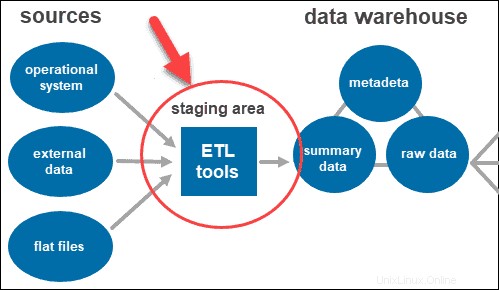
Alat ETL
ETL adalah singkatan dari Ekstrak , Transformasi , dan Muat . Lapisan pementasan menggunakan alat ETL untuk mengekstrak data yang diperlukan dari berbagai format dan memeriksa kualitasnya sebelum memuatnya ke dalam gudang data.
Data yang berasal dari lapisan sumber data bisa datang dalam berbagai format. Sebelum menggabungkan semua data yang dikumpulkan dari berbagai sumber ke dalam satu database, sistem harus membersihkan dan mengatur informasi.
Basis Data
Komponen yang paling penting dan jantung dari setiap arsitektur adalah database. Gudang adalah tempat data disimpan dan diakses.
Saat membuat sistem gudang data, Anda harus terlebih dahulu memutuskan jenis database yang ingin Anda gunakan.
Ada empat jenis database yang dapat Anda pilih:
- Basis data relasional (basis data yang berpusat pada baris).
- Basis data Analytics (dikembangkan untuk mempertahankan dan mengelola analitik).
- Aplikasi gudang data (perangkat lunak untuk pengelolaan data dan perangkat keras untuk menyimpan data yang ditawarkan oleh dealer pihak ketiga).
- Basis data berbasis cloud (dihosting di cloud).
Data
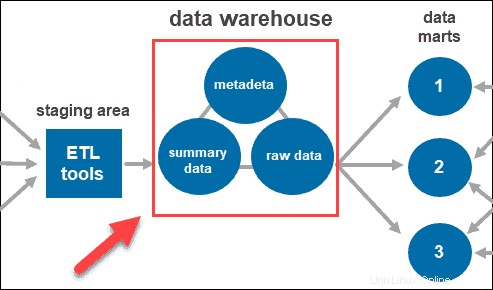
Setelah sistem membersihkan dan mengatur data, ia menyimpannya di gudang data. Gudang data mewakili repositori pusat yang menyimpan metadata, data ringkasan, dan data mentah yang berasal dari setiap sumber.
- Metadata adalah informasi yang mendefinisikan data. Peran utamanya adalah untuk menyederhanakan bekerja dengan instance data. Ini memungkinkan analis data untuk mengklasifikasikan, menemukan, dan mengarahkan kueri ke data yang diperlukan.
- Ringkasan data dihasilkan oleh manajer gudang. Ini diperbarui saat data baru dimuat ke dalam gudang. Komponen ini dapat mencakup data yang ringan atau sangat diringkas. Peran utamanya adalah untuk mempercepat kinerja kueri.
- Data mentah adalah pemuatan data aktual ke dalam repositori, yang belum diproses. Memiliki data dalam bentuk mentahnya membuatnya dapat diakses untuk pemrosesan dan analisis lebih lanjut.
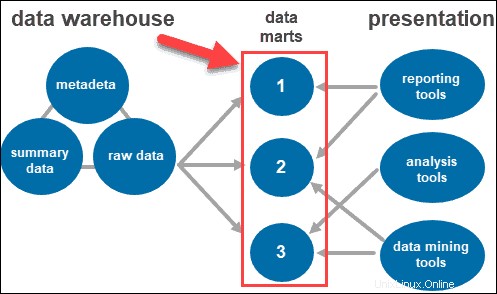
Alat Akses
Pengguna berinteraksi dengan informasi yang dikumpulkan melalui alat dan teknologi yang berbeda. Mereka dapat menganalisis data, mengumpulkan wawasan, dan membuat laporan.
Beberapa alat yang digunakan antara lain:
- Alat pelaporan. Mereka memainkan peran penting dalam memahami bagaimana bisnis Anda berjalan dan apa yang harus dilakukan selanjutnya. Alat pelaporan mencakup visualisasi seperti grafik dan bagan yang menunjukkan bagaimana data berubah dari waktu ke waktu.
- Alat OLAP. Alat pemrosesan analitik online yang memungkinkan pengguna menganalisis data multidimensi dari berbagai perspektif. Alat-alat ini memberikan pemrosesan yang cepat dan analisis yang berharga. Mereka mengekstrak data dari berbagai kumpulan data relasional dan mengaturnya kembali ke dalam format multidimensi.
- Alat penambangan data. Periksa kumpulan data untuk menemukan pola di dalam gudang dan korelasi di antara mereka. Data mining juga membantu membangun hubungan saat menganalisis data multidimensi.
Data Mart
Data mart memungkinkan Anda untuk memiliki beberapa grup dalam sistem dengan mengelompokkan data di gudang ke dalam kategori. Ini mempartisi data, memproduksinya untuk grup pengguna tertentu.
Misalnya, Anda dapat menggunakan data mart untuk mengkategorikan informasi berdasarkan departemen dalam perusahaan.
Praktik Terbaik Gudang Data
Mendesain gudang data bergantung pada pemahaman logika bisnis dari kasus penggunaan individual Anda.
Persyaratannya bervariasi, tetapi ada praktik terbaik gudang data yang harus Anda ikuti:
- Buat model data. Mulailah dengan mengidentifikasi logika bisnis organisasi. Pahami data apa yang vital bagi organisasi dan bagaimana data tersebut akan mengalir melalui gudang data.
- Pilih standar arsitektur gudang data yang terkenal. Model data menyediakan kerangka kerja dan serangkaian praktik terbaik untuk diikuti saat merancang arsitektur atau memecahkan masalah. Standar arsitektur populer mencakup 3NF, pemodelan Data Vault, dan skema bintang.
- Buat diagram aliran data. Dokumentasikan bagaimana data mengalir melalui sistem. Ketahui hubungannya dengan persyaratan dan logika bisnis Anda.
- Memiliki satu sumber kebenaran. Ketika berhadapan dengan begitu banyak data, sebuah organisasi harus memiliki satu sumber kebenaran. Konsolidasikan data ke dalam satu repositori.
- Gunakan otomatisasi. Alat otomatisasi membantu saat menangani data dalam jumlah besar.
- Izinkan berbagi metadata. Rancang arsitektur yang memfasilitasi pembagian metadata antar komponen gudang data.
- Terapkan standar pengkodean. Standar pengkodean memastikan efisiensi sistem.