Dalam tutorial ini, kita akan belajar cara men-setup cluster hadoop multi-node di Ubuntu 16.04. Sebuah cluster hadoop yang memiliki lebih dari 1 datanode adalah cluster hadoop multi-node, oleh karena itu, tujuan dari tutorial ini adalah untuk mendapatkan 2 datanode dan berjalan.
1) Prasyarat
- Ubuntu 16.04
- Hadoop-2.7.3
- Java 7
- SSH
Untuk tutorial ini, saya punya dua ubuntu 16.04 sistem, saya menyebutnya master dan budak sistem, satu datanode akan berjalan di setiap sistem.
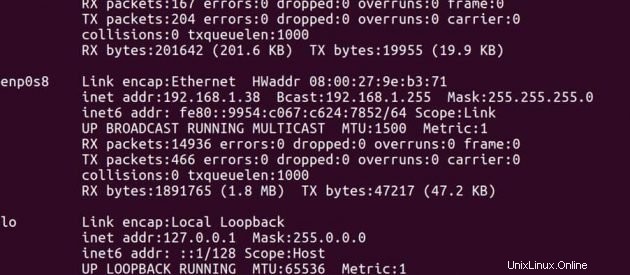
Alamat IP Master -> 192.168.1.37
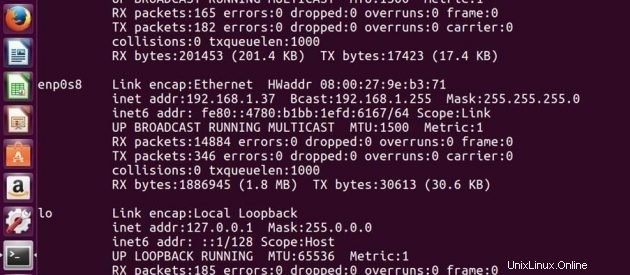
Alamat IP Budak -> 192.168.1.38
Atas Guru
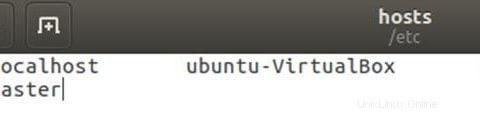
Edit file host dengan alamat ip master dan slave.
sudo gedit /etc/hostsEdit file seperti di bawah ini, Anda dapat menghapus baris lain dalam file. Setelah mengedit, simpan file dan tutup.

Pada Budak
Edit file host dengan alamat ip master dan slave.
sudo gedit /etc/hostsEdit file seperti di bawah ini, Anda dapat menghapus baris lain dalam file. Setelah mengedit, simpan file dan tutup.
2) Instalasi Java
Sebelum mengatur hadoop, Anda harus menginstal Java di sistem Anda. Instal JDK 7 yang terbuka di kedua mesin ubuntu menggunakan perintah di bawah ini.
sudo add-apt-repository ppa:openjdk-r/ppasudo apt-get updatedo apt-get install openjdk-7-jdk
Jalankan perintah di bawah ini untuk melihat apakah java telah terinstal di sistem Anda.
java -version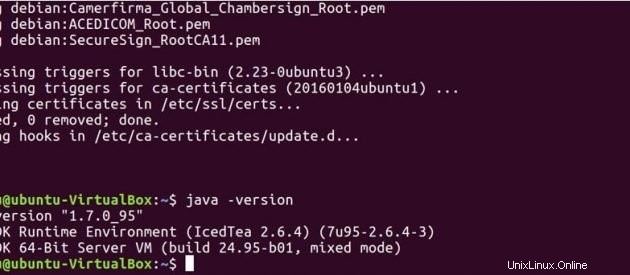
Secara default java disimpan di /usr/lib/jvm/ direktori.
ls /usr/lib/jvm
Setel jalur Java di .bashrc berkas.
sudo gedit .bashrcekspor JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
ekspor PATH=$PATH:/usr/lib/jvm/java-7-openjdk-amd64/bin
Jalankan perintah di bawah ini untuk memperbarui perubahan yang dibuat pada file .bashrc.
source .bashrc3) SSH
Hadoop membutuhkan akses SSH untuk mengelola node-nya, oleh karena itu kita perlu menginstal ssh pada sistem master dan slave.
sudo apt-get install openssh-server</pre
Now, we have to generate an SSH key on master machine. When it asks you to enter a file name to save the key, do not give any name, just press enter.
ssh-keygen -t rsa -P ""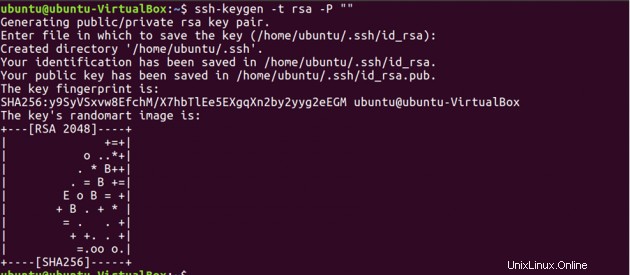
Kedua, Anda harus mengaktifkan akses SSH ke mesin master Anda dengan kunci yang baru dibuat ini.
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
Sekarang uji penyiapan SSH dengan menghubungkan ke mesin lokal Anda.
ssh localhost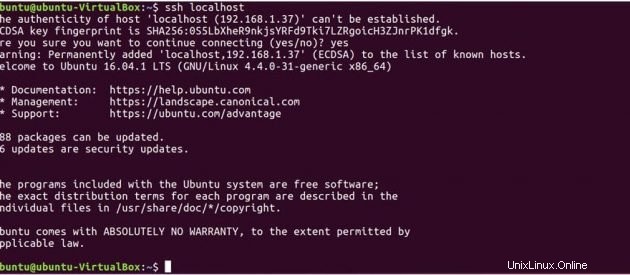
Sekarang jalankan perintah di bawah ini untuk mengirim kunci publik yang dihasilkan pada master ke slave.
ssh-copy-id -i $HOME/.ssh/id_rsa.pub ubuntu@slave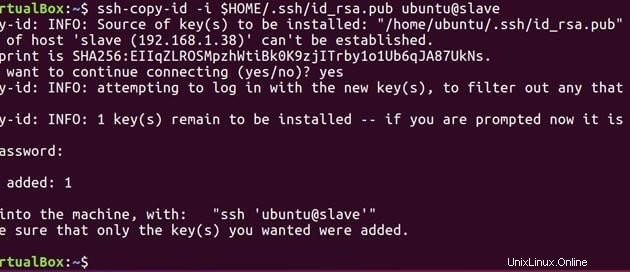
Sekarang master dan slave memiliki kunci publik, Anda juga dapat menghubungkan master ke master dan master ke slave.
ssh master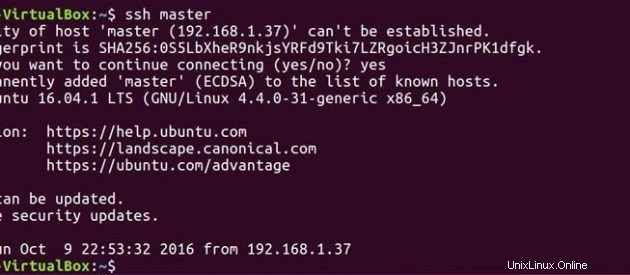
ssh slave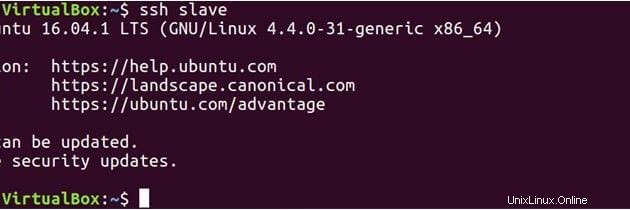
Atas Guru
Edit file master seperti di bawah ini.
sudo gedit hadoop-2.7.3/etc/hadoop/masters
Edit file slave seperti di bawah ini.
sudo gedit hadoop-2.7.3/etc/hadoop/slaves
Pada Budak
Edit file master seperti di bawah ini.
sudo gedit hadoop-2.7.3/etc/hadoop/masters4) Instalasi Hadoop
Sekarang setelah kita menyiapkan Java dan ssh kita. Kami baik untuk pergi dan menginstal hadoop pada kedua sistem. Gunakan tautan di bawah ini untuk mengunduh paket hadoop. Saya menggunakan versi stabil terbaru hadoop 2.7.3
http://hadoop.apache.org/releases.html
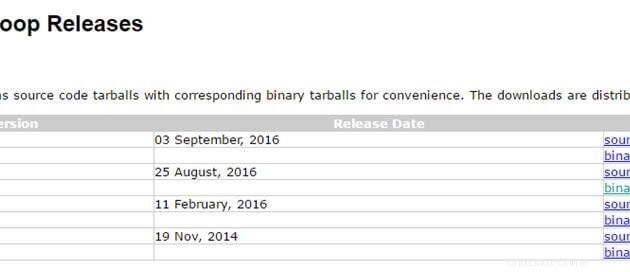
Atas Guru
Perintah di bawah ini akan mengunduh hadoop-2.7.3 berkas tar.
wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.3/hadoop-2.7.3.tar.gz
lsBuka tar file
tar -xvf hadoop-2.7.3.tar.gz
ls
Konfirmasikan bahwa hadoop telah terinstal di sistem Anda.
cd hadoop-2.7.3/
bin/hadoop-2.7.3/
Sebelum mengatur konfigurasi untuk hadoop, kita akan mengatur variabel lingkungan di bawah ini dalam file .bashrc.
cd
sudo gedit .bashrcVariabel lingkungan Hadoop
# Set Hadoop-related environment variables
export HADOOP_HOME=$HOME/hadoop-2.7.3
export HADOOP_CONF_DIR=$HOME/hadoop-2.7.3/etc/hadoop
export HADOOP_MAPRED_HOME=$HOME/hadoop-2.7.3
export HADOOP_COMMON_HOME=$HOME/hadoop-2.7.3
export HADOOP_HDFS_HOME=$HOME/hadoop-2.7.3
export YARN_HOME=$HOME/hadoop-2.7.3
# Add Hadoop bin/ directory to PATH
export PATH=$PATH:$HOME/hadoop-2.7.3/bin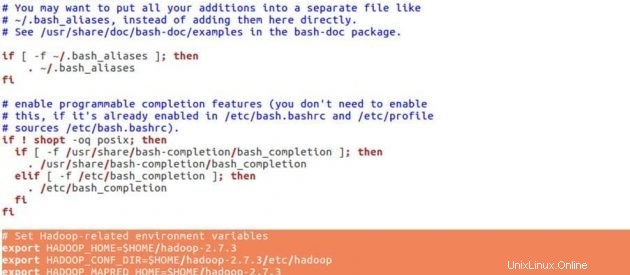
Letakkan baris di bawah ini di akhir .bashrc . Anda file, simpan file dan tutup.
source .bashrcKonfigurasi JAVA_HOME di 'hadoop-env.sh' . File ini menentukan variabel lingkungan yang memengaruhi JDK yang digunakan oleh daemon Apache Hadoop 2.7.3 yang dimulai oleh skrip start-up Hadoop:
cd hadoop-2.7.3/etc/hadoop/sudo gedit hadoop-env.sh
ekspor JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64

Atur jalur java seperti yang ditunjukkan di atas, simpan file dan tutup.
Sekarang kita akan membuat NameNode dan DataNode direktori.
cd
mkdir -p $HADOOP_HOME/hadoop2_data/hdfs/namenode
mkdir -p $HADOOP_HOME/hadoop2_data/hdfs/datanode
Hadoop memiliki banyak file konfigurasi, yang perlu dikonfigurasi sesuai kebutuhan infrastruktur hadoop Anda. Mari kita konfigurasikan file konfigurasi hadoop satu per satu.
cd hadoop-2.7.3/etc/hadoop/
sudo gedit core-site.xmlSitus-inti.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>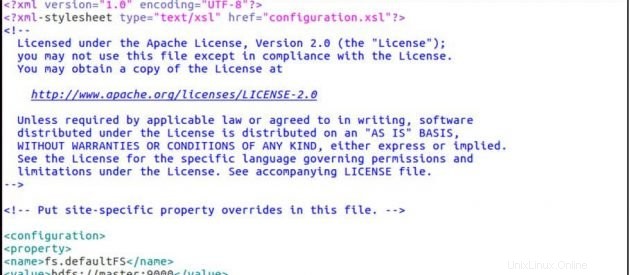
sudo gedit hdfs-site.xmlhdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/ubuntu/hadoop-2.7.3/hadoop2_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/ubuntu/hadoop-2.7.3/hadoop2_data/hdfs/datanode</value>
</property>
</configuration>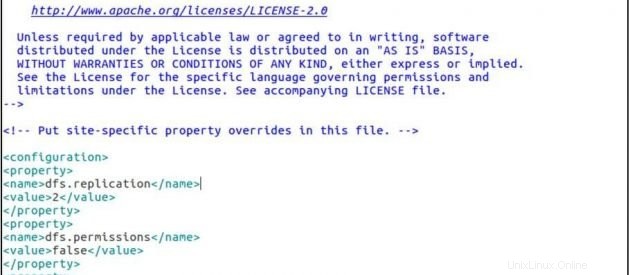
sudo gedit yarn-site.xmlsitus-benang.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
cp mapred-site.xml.template mapred-site.xml
sudo gedit mapred-site.xmlsitus yang dipetakan.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>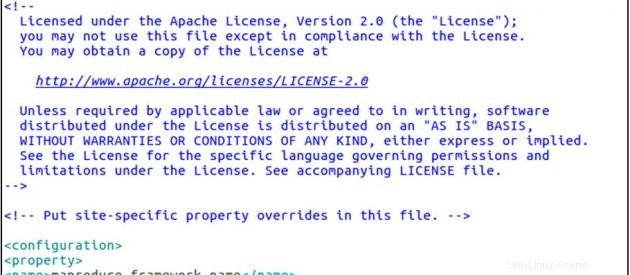
Sekarang ikuti instalasi hadoop yang sama dan langkah-langkah konfigurasi pada mesin slave juga. Setelah Anda menginstal dan mengonfigurasi hadoop di kedua sistem, hal pertama dalam memulai cluster hadoop Anda adalah memformat hsistem file adoop , yang diimplementasikan di atas sistem file lokal cluster Anda. Ini diperlukan pada saat pertama kali menginstal hadoop. Jangan memformat sistem file hadoop yang sedang berjalan, ini akan menghapus semua data HDFS Anda.
Atas Guru
cd
cd hadoop-2.7.3/bin
hadoop namenode -format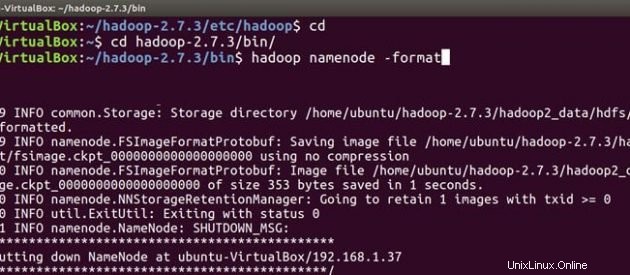
Kami sekarang siap untuk memulai daemon hadoop yaitu NameNode, DataNode, ResourceManager dan NodeManager di Cluster Apache Hadoop kami.
cd ..Sekarang jalankan perintah di bawah ini untuk memulai NameNode pada mesin master dan DataNodes pada master dan slave.
sbin/start-dfs.sh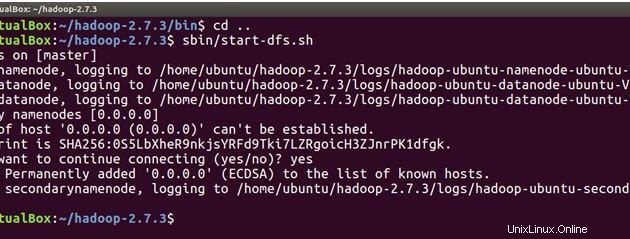
Perintah di bawah ini akan memulai daemon YARN, ResourceManager akan berjalan pada master dan NodeManager akan berjalan pada master dan slave.
sbin/start-yarn.sh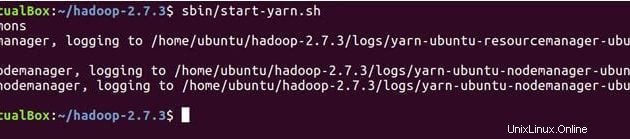
Periksa silang apakah semua layanan sudah dimulai dengan benar menggunakan JPS (Java Process Monitoring Tool). pada mesin master dan slave.
Di bawah ini adalah daemon yang berjalan di mesin master.
jps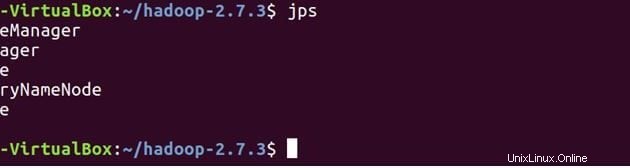
Pada Budak
Anda akan melihat DataNode dan NodeManager juga akan berjalan di mesin slave.
jps
Sekarang buka browser mozilla Anda di mesin master dan buka URL di bawah ini
Periksa status NameNode:http://master:50070/dfshealth.html
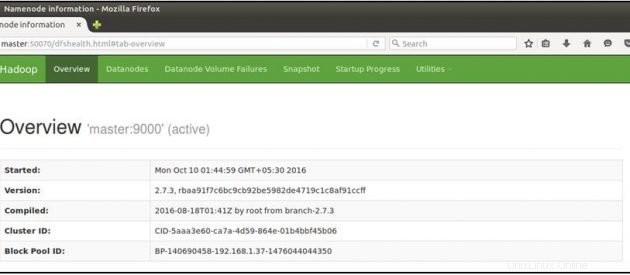
Jika Anda melihat '2' di node aktif , itu berarti 2 DataNodes aktif dan berjalan dan Anda telah berhasil menyiapkan culster hadoop multi-simpul.
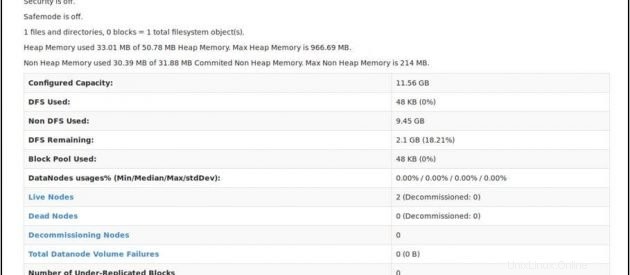
Kesimpulan
Anda dapat menambahkan lebih banyak node ke kluster hadoop Anda, yang perlu Anda lakukan hanyalah menambahkan ip node slave baru ke file slave di master, salin kunci ssh ke node slave baru, letakkan ip master di file master pada node slave baru, lalu mulai ulang layanan hadoop. Selamat!! Anda telah berhasil menyiapkan cluster hadoop multi-simpul.