Pendahuluan
Setiap industri besar menerapkan Apache Hadoop sebagai kerangka kerja standar untuk memproses dan menyimpan data besar. Hadoop dirancang untuk digunakan di jaringan ratusan atau bahkan ribuan server khusus. Semua mesin ini bekerja sama untuk menangani volume besar dan berbagai set data yang masuk.
Menyebarkan layanan Hadoop pada satu node adalah cara yang bagus untuk membiasakan diri Anda dengan perintah dan konsep dasar Hadoop.
Panduan yang mudah diikuti ini membantu Anda menginstal Hadoop di Ubuntu 18.04 atau Ubuntu 20.04.

Prasyarat
- Akses ke jendela terminal/baris perintah
- Sudo atau akar hak istimewa pada mesin lokal /jarak jauh
Instal OpenJDK di Ubuntu
Kerangka kerja Hadoop ditulis dalam Java, dan layanannya memerlukan Java Runtime Environment (JRE) dan Java Development Kit (JDK) yang kompatibel. Gunakan perintah berikut untuk memperbarui sistem Anda sebelum memulai instalasi baru:
sudo apt updateSaat ini, Apache Hadoop 3.x mendukung penuh Java 8 . Paket OpenJDK 8 di Ubuntu berisi lingkungan runtime dan kit pengembangan.
Ketik perintah berikut di terminal Anda untuk menginstal OpenJDK 8:
sudo apt install openjdk-8-jdk -yVersi OpenJDK atau Oracle Java dapat memengaruhi cara elemen ekosistem Hadoop berinteraksi. Untuk menginstal versi Java tertentu, lihat panduan terperinci kami tentang cara menginstal Java di Ubuntu.
Setelah proses instalasi selesai, verifikasi versi Java saat ini:
java -version; javac -versionOutputnya memberi tahu Anda edisi Java mana yang sedang digunakan.

Menyiapkan Pengguna Non-Root untuk Lingkungan Hadoop
Disarankan untuk membuat pengguna non-root, khusus untuk lingkungan Hadoop. Pengguna yang berbeda meningkatkan keamanan dan membantu Anda mengelola cluster dengan lebih efisien. Untuk memastikan kelancaran fungsi layanan Hadoop, pengguna harus memiliki kemampuan untuk membuat koneksi SSH tanpa kata sandi dengan localhost.
Instal OpenSSH di Ubuntu
Instal server dan klien OpenSSH menggunakan perintah berikut:
sudo apt install openssh-server openssh-client -yPada contoh di bawah, output mengonfirmasi bahwa versi terbaru sudah diinstal.

Jika Anda telah menginstal OpenSSH untuk pertama kalinya, gunakan kesempatan ini untuk menerapkan rekomendasi keamanan SSH yang vital ini.
Buat Pengguna Hadoop
Gunakan adduser perintah untuk membuat pengguna Hadoop baru:
sudo adduser hdoopNama pengguna, dalam contoh ini, adalah hdoop . Anda bebas menggunakan nama pengguna dan kata sandi apa pun yang Anda inginkan. Beralih ke pengguna yang baru dibuat dan masukkan kata sandi yang sesuai:
su - hdoopPengguna sekarang harus dapat melakukan SSH ke localhost tanpa diminta kata sandi.
Aktifkan SSH Tanpa Kata Sandi untuk Pengguna Hadoop
Buat pasangan kunci SSH dan tentukan lokasi yang akan disimpan di:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsaSistem melanjutkan untuk menghasilkan dan menyimpan pasangan kunci SSH.
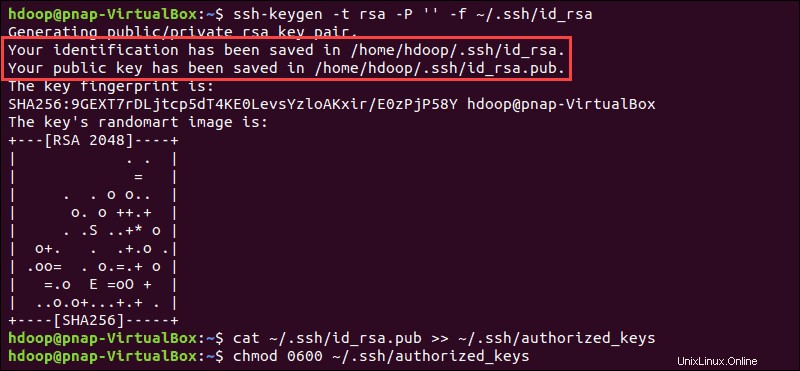
Gunakan cat perintah untuk menyimpan kunci publik sebagai authorized_keys di ssh direktori:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
Setel izin untuk pengguna Anda dengan chmod perintah:
chmod 0600 ~/.ssh/authorized_keysPengguna baru sekarang dapat melakukan SSH tanpa perlu memasukkan kata sandi setiap saat. Pastikan semuanya sudah diatur dengan benar dengan menggunakan hdoop pengguna ke SSH ke localhost:
ssh localhostSetelah prompt awal, pengguna Hadoop sekarang dapat membuat koneksi SSH ke localhost dengan mulus.
Unduh dan Instal Hadoop di Ubuntu
Kunjungi halaman proyek resmi Apache Hadoop, dan pilih versi Hadoop yang ingin Anda terapkan.
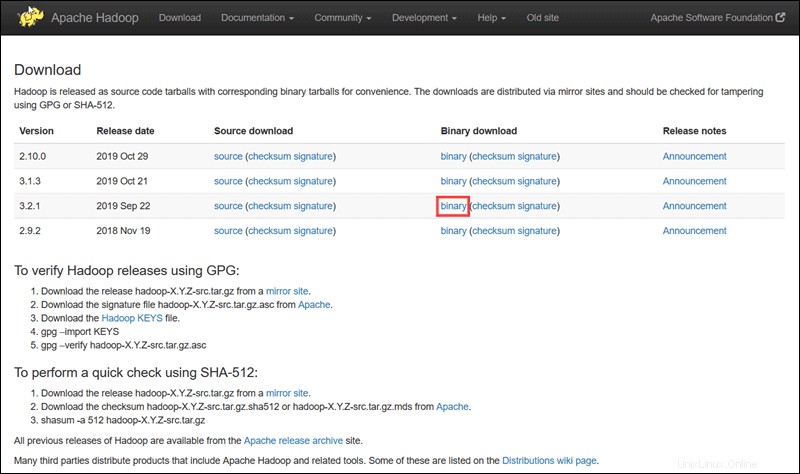
Langkah-langkah yang diuraikan dalam tutorial ini menggunakan unduhan Biner untuk Hadoop Versi 3.2.1 .
Pilih opsi yang Anda inginkan, dan Anda akan diberikan tautan cermin yang memungkinkan Anda mengunduh paket tar Hadoop .
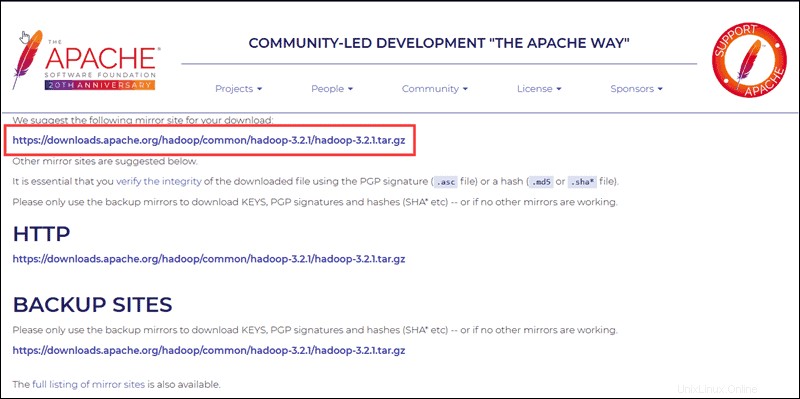
Gunakan tautan cermin yang disediakan dan unduh paket Hadoop dengan wget perintah:
wget https://downloads.apache.org/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz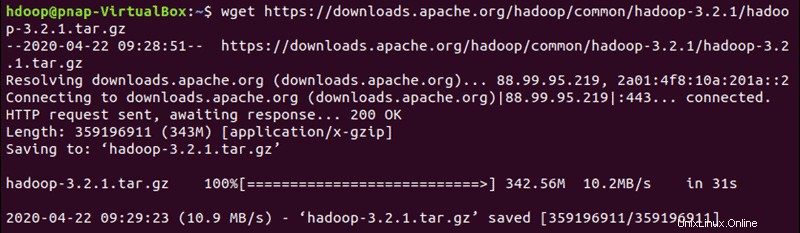
Setelah unduhan selesai, ekstrak file untuk memulai instalasi Hadoop:
tar xzf hadoop-3.2.1.tar.gzFile biner Hadoop sekarang berada di dalam hadoop-3.2.1 direktori.
Penerapan Hadoop Node Tunggal (Mode Terdistribusi Semu)
Hadoop unggul saat digunakan dalam mode terdistribusi penuh pada sekelompok besar server jaringan. Namun, jika Anda baru mengenal Hadoop dan ingin menjelajahi perintah dasar atau menguji aplikasi, Anda dapat mengonfigurasi Hadoop pada satu node.
Penyiapan ini, juga disebut mode terdistribusi semu , memungkinkan setiap daemon Hadoop berjalan sebagai satu proses Java. Lingkungan Hadoop dikonfigurasi dengan mengedit satu set file konfigurasi:
- bashrc
- hadoop-env.sh
- situs-inti.xml
- hdfs-site.xml
- situs-dipetakan-xml
- situs-benang.xml
Konfigurasi Variabel Lingkungan Hadoop (bashrc)
Edit .bashrc file konfigurasi shell menggunakan editor teks pilihan Anda (kami akan menggunakan nano):
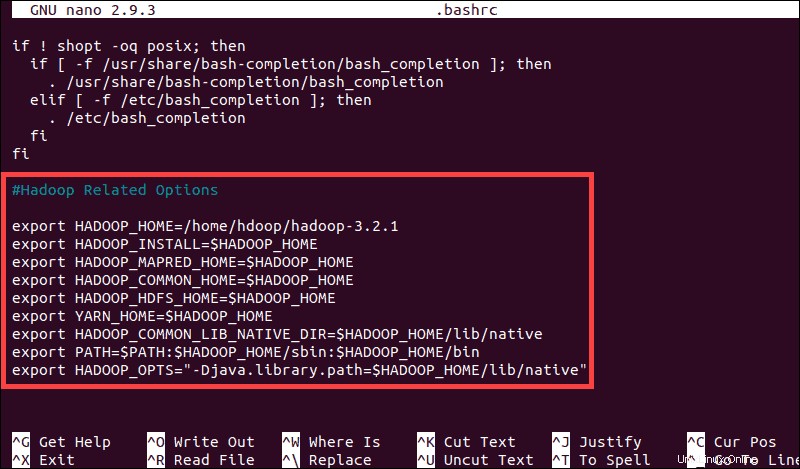
sudo nano .bashrcTentukan variabel lingkungan Hadoop dengan menambahkan konten berikut ke akhir file:
#Hadoop Related Options
export HADOOP_HOME=/home/hdoop/hadoop-3.2.1
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS"-Djava.library.path=$HADOOP_HOME/lib/nativ"
Setelah Anda menambahkan variabel, simpan dan keluar dari .bashrc berkas.
Sangat penting untuk menerapkan perubahan pada lingkungan yang sedang berjalan dengan menggunakan perintah berikut:
source ~/.bashrcEdit Berkas hadoop-env.sh
hadoop-env.sh file berfungsi sebagai file master untuk mengonfigurasi pengaturan proyek terkait YARN, HDFS, MapReduce, dan Hadoop.
Saat menyiapkan kluster Hadoop node tunggal , Anda perlu menentukan implementasi Java mana yang akan digunakan. Gunakan $HADOOP_HOME yang dibuat sebelumnya variabel untuk mengakses hadoop-env.sh berkas:
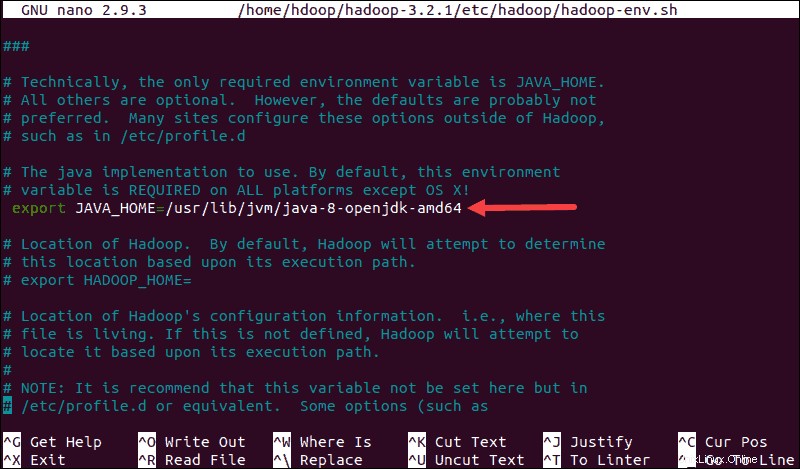
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Batalkan komentar $JAVA_HOME variabel (yaitu, hapus # sign) dan tambahkan path lengkap ke instalasi OpenJDK di sistem Anda. Jika Anda telah menginstal versi yang sama seperti yang disajikan di bagian pertama tutorial ini, tambahkan baris berikut:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64Jalur harus cocok dengan lokasi penginstalan Java di sistem Anda.
Jika Anda memerlukan bantuan untuk menemukan jalur Java yang benar, jalankan perintah berikut di jendela terminal Anda:
which javacOutput yang dihasilkan menyediakan jalur ke direktori biner Java.

Gunakan jalur yang disediakan untuk menemukan direktori OpenJDK dengan perintah berikut:
readlink -f /usr/bin/javac
Bagian jalur tepat sebelum /bin/javac direktori harus ditetapkan ke $JAVA_HOME variabel.

Edit File core-site.xml
situs-inti.xml file mendefinisikan properti inti HDFS dan Hadoop.
Untuk menyiapkan Hadoop dalam mode terdistribusi semu, Anda perlu menentukan URL untuk NameNode Anda, dan direktori sementara yang digunakan Hadoop untuk proses peta dan pengurangan.
Buka situs-inti.xml file dalam editor teks:
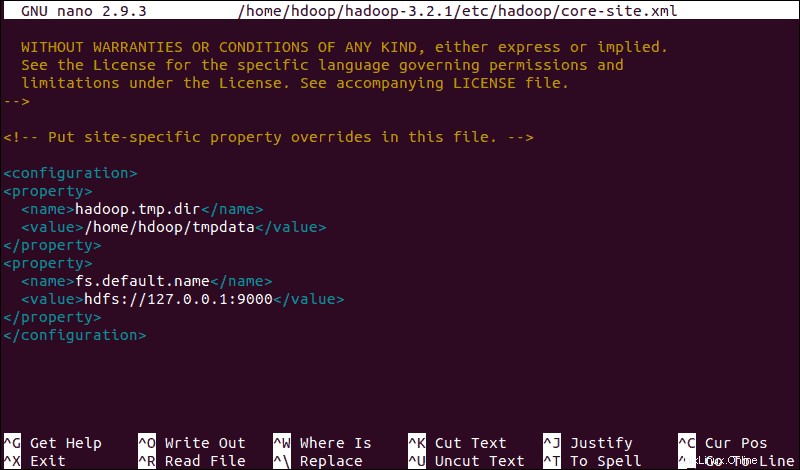
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xmlTambahkan konfigurasi berikut untuk mengganti nilai default untuk direktori sementara dan tambahkan URL HDFS Anda untuk menggantikan pengaturan sistem file lokal default:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdoop/tmpdata</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
</configuration>Contoh ini menggunakan nilai khusus untuk sistem lokal. Anda harus menggunakan nilai yang sesuai dengan persyaratan sistem Anda. Data harus konsisten selama proses konfigurasi.
Jangan lupa untuk membuat direktori Linux di lokasi yang Anda tentukan untuk data sementara Anda.
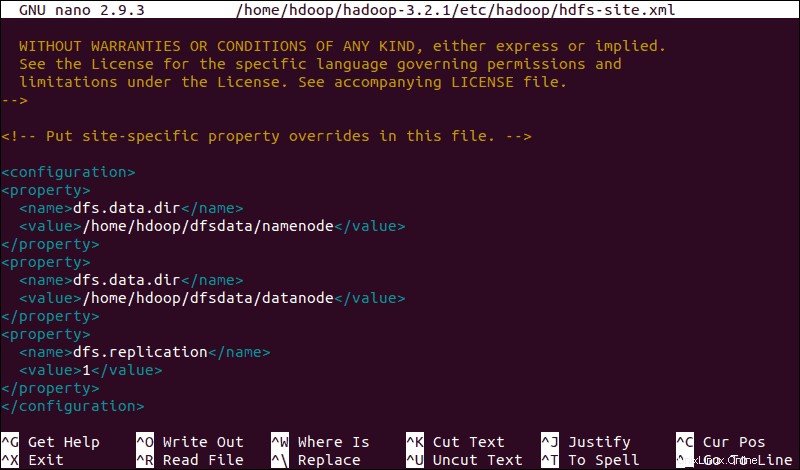
Edit File hdfs-site.xml
Properti di hdfs-site.xml file mengatur lokasi untuk menyimpan metadata node, file fsimage, dan mengedit file log. Konfigurasikan file dengan mendefinisikan NameNode dan direktori penyimpanan DataNode .
Selain itu, default dfs.replication nilai 3 perlu diubah menjadi 1 agar sesuai dengan penyiapan simpul tunggal.
Gunakan perintah berikut untuk membuka hdfs-site.xml file untuk diedit:
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xmlTambahkan konfigurasi berikut ke file dan, jika perlu, sesuaikan direktori NameNode dan DataNode ke lokasi kustom Anda:
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/home/hdoop/dfsdata/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hdoop/dfsdata/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
Jika perlu, buat direktori khusus yang Anda tetapkan untuk dfs.data.dir nilai.
Edit File mapred-site.xml
Gunakan perintah berikut untuk mengakses mapred-site.xml file dan menentukan nilai MapReduce :
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Tambahkan konfigurasi berikut untuk mengubah nilai default nama framework MapReduce menjadi yarn :
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>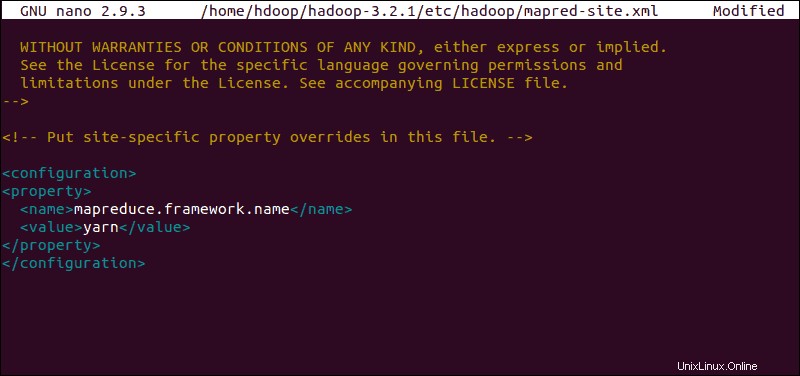
Edit File yarn-site.xml
situs-benang.xml file digunakan untuk menentukan setelan yang relevan dengan BENANG . Ini berisi konfigurasi untuk Node Manager, Resource Manager, Containers, dan Master Aplikasi .
Buka situs-benang.xml file dalam editor teks:
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xmlTambahkan konfigurasi berikut ke file:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>127.0.0.1</value>
</property>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PERPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>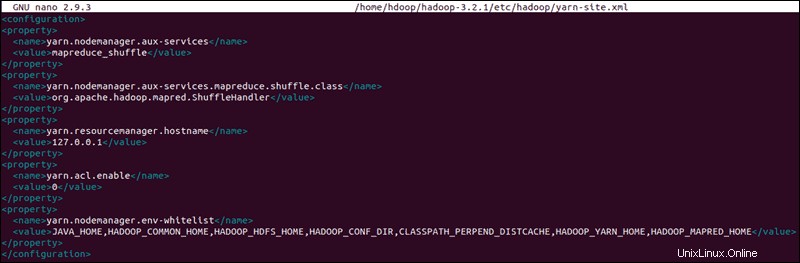
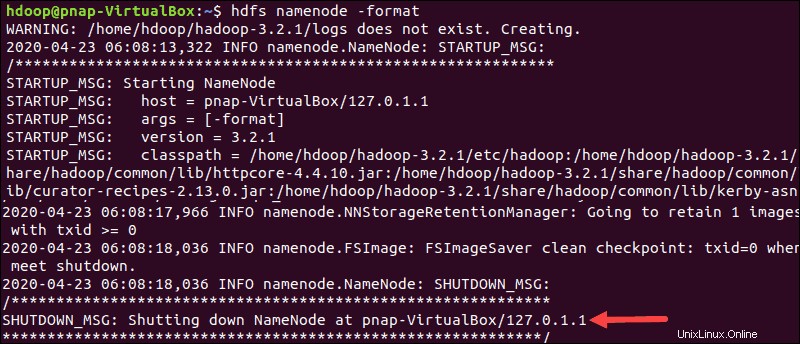
Format HDFS NameNode
Penting untuk memformat NameNode sebelum memulai layanan Hadoop untuk pertama kalinya:
hdfs namenode -formatNotifikasi shutdown menandakan akhir dari proses format NameNode.
Mulai Hadoop Cluster
Navigasikan ke hadoop-3.2.1/sbin direktori dan jalankan perintah berikut untuk memulai NameNode dan DataNode:
./start-dfs.shSistem membutuhkan beberapa saat untuk memulai node yang diperlukan.

Setelah namenode, datanode, dan secondary namenode aktif dan berjalan, mulai YARN resource dan nodemanagers dengan mengetik:
./start-yarn.shSeperti perintah sebelumnya, output memberitahu Anda bahwa proses sedang dimulai.

Ketik perintah sederhana ini untuk memeriksa apakah semua daemon aktif dan berjalan sebagai proses Java:
jpsJika semuanya berfungsi sebagaimana mestinya, daftar hasil proses Java yang berjalan berisi semua daemon HDFS dan YARN.

Akses Hadoop UI dari Browser
Gunakan browser pilihan Anda dan arahkan ke URL atau IP localhost Anda. Nomor port default 9870 memberi Anda akses ke Hadoop NameNode UI:
http://localhost:9870Antarmuka pengguna NameNode memberikan gambaran menyeluruh tentang seluruh cluster.
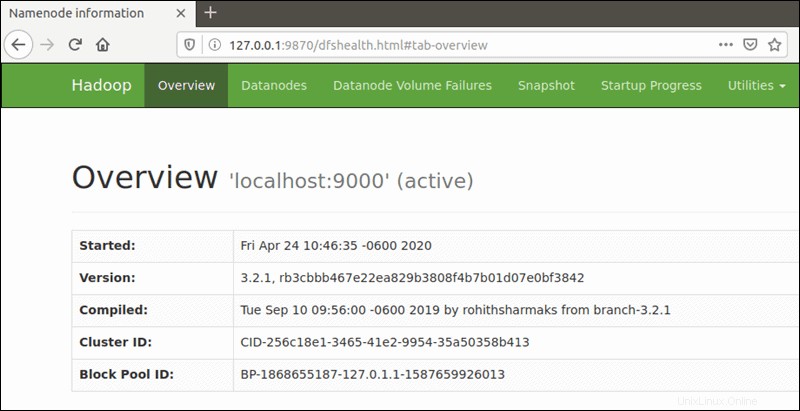
Port default 9864 digunakan untuk mengakses DataNodes individual langsung dari browser Anda:
http://localhost:9864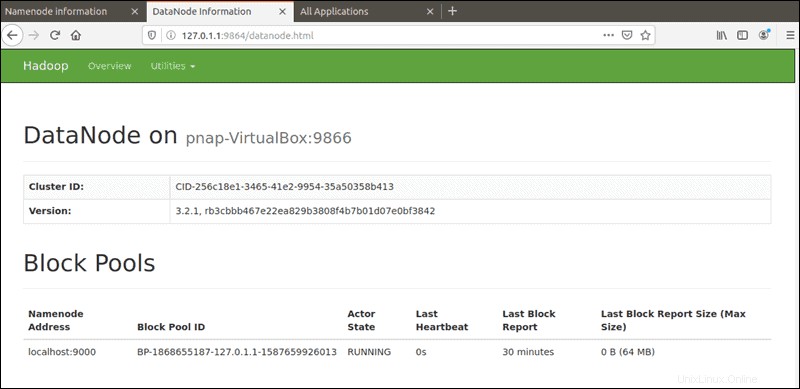
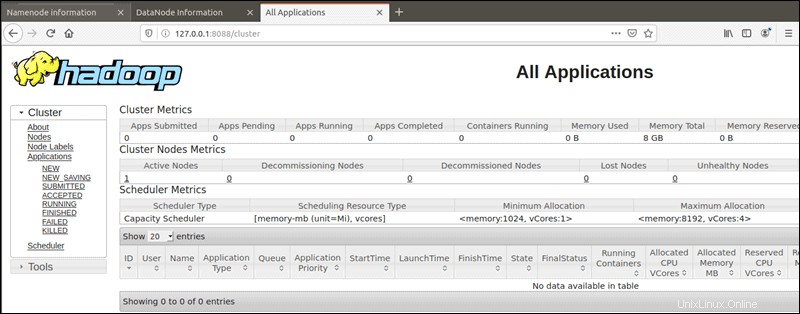
YARN Resource Manager dapat diakses pada port 8088 :
http://localhost:8088Resource Manager adalah alat yang sangat berharga yang memungkinkan Anda memantau semua proses yang berjalan di cluster Hadoop Anda.