Pendahuluan
Mempelajari cara membuat Spark DataFrame adalah salah satu langkah praktis pertama di lingkungan Spark. Spark DataFrames membantu memberikan pandangan ke dalam struktur data dan fungsi manipulasi data lainnya. Ada metode yang berbeda tergantung pada sumber data dan format penyimpanan data file.
Artikel ini menjelaskan cara membuat Spark DataFrame secara manual dengan Python menggunakan PySpark.

Prasyarat
- Python 3 diinstal dan dikonfigurasi.
- PySpark diinstal dan dikonfigurasi.
- Lingkungan pengembangan Python yang siap untuk menguji contoh kode (kami menggunakan Jupyter Notebook).
Metode untuk membuat Spark DataFrame
Ada tiga cara untuk membuat DataFrame di Spark dengan tangan:
1. Buat daftar dan parsing sebagai DataFrame menggunakan toDataFrame() metode dari SparkSession .
2. Konversi RDD ke DataFrame menggunakan toDF() metode.
3. Impor file ke SparkSession sebagai DataFrame secara langsung.
Contoh menggunakan data sampel dan RDD untuk demonstrasi, meskipun prinsip umum berlaku untuk struktur data yang serupa.
Buat DataFrame dari daftar data
Untuk membuat Spark DataFrame dari daftar data:
1. Buat daftar kamus sampel dengan data mainan:
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
2. Impor dan buat SparkSession :
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
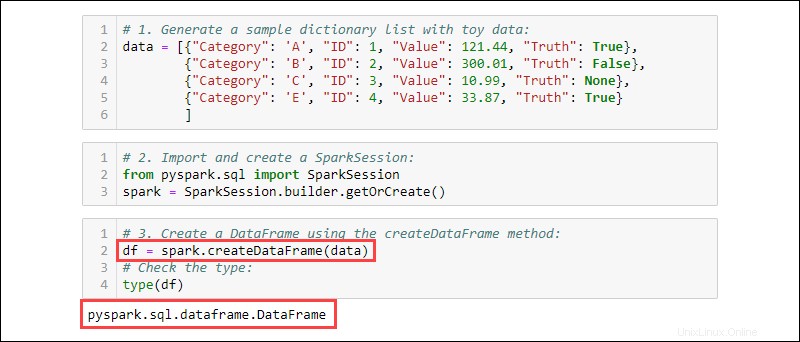
3. Buat DataFrame menggunakan createDataFrame metode. Periksa tipe data untuk mengonfirmasi bahwa variabel tersebut adalah DataFrame:
df = spark.createDataFrame(data)
type(df)
Buat DataFrame dari RDD
Peristiwa khas saat bekerja di Spark adalah membuat DataFrame dari RDD yang ada. Buat contoh RDD, lalu ubah menjadi DataFrame.
1. Buat daftar kamus yang berisi data mainan:
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
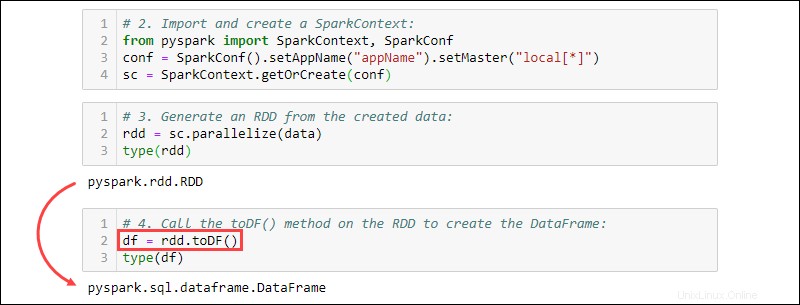
2. Impor dan buat SparkContext :
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("projectName").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
3. Hasilkan RDD dari data yang dibuat. Periksa jenisnya untuk mengonfirmasi bahwa objek tersebut adalah RDD:
rdd = sc.parallelize(data)
type(rdd)
4. Panggil toDF() metode pada RDD untuk membuat DataFrame. Uji jenis objek untuk mengonfirmasi:
df = rdd.toDF()
type(df)
Buat DataFrame dari Sumber data
Spark dapat menangani beragam sumber data eksternal untuk membangun DataFrames. Sintaks umum untuk membaca dari file adalah:
spark.read.format('<data source>').load('<file path/file name>')Nama dan jalur sumber data keduanya adalah tipe String. Sumber data tertentu juga memiliki sintaks alternatif untuk mengimpor file sebagai DataFrames.
Membuat dari file CSV
Buat Spark DataFrame dengan membaca langsung dari file CSV:
df = spark.read.csv('<file name>.csv')Baca beberapa file CSV menjadi satu DataFrame dengan menyediakan daftar jalur:
df = spark.read.csv(['<file name 1>.csv', '<file name 2>.csv', '<file name 3>.csv'])
Secara default, Spark menambahkan header untuk setiap kolom. Jika file CSV memiliki header yang ingin Anda sertakan, tambahkan option metode saat mengimpor:
df = spark.read.csv('<file name>.csv').option('header', 'true')
Opsi individu ditumpuk dengan memanggilnya satu demi satu. Atau, gunakan option metode ketika lebih banyak opsi diperlukan selama impor:
df = spark.read.csv('<file name>.csv').options(header = True)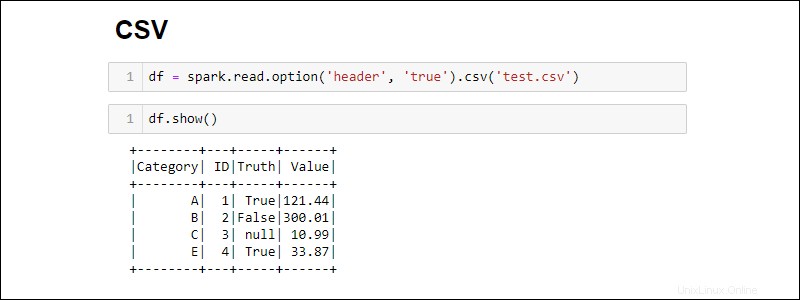
Perhatikan sintaksnya berbeda saat menggunakan option vs. option .
Membuat dari file TXT
Buat DataFrame dari file teks dengan:
df = spark.read.text('<file name>.txt')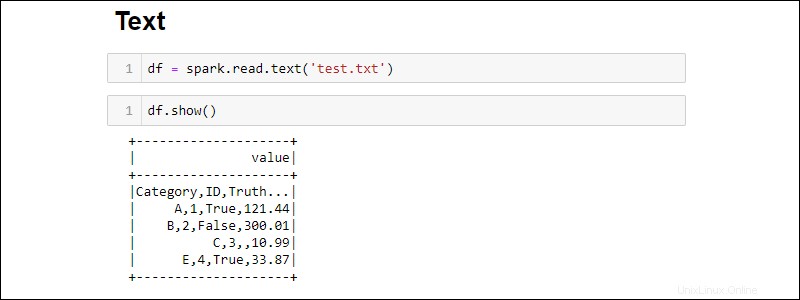
csv metode adalah cara lain untuk membaca dari txt jenis file ke dalam DataFrame. Misalnya:
df = spark.read.option('header', 'true').csv('<file name>.txt')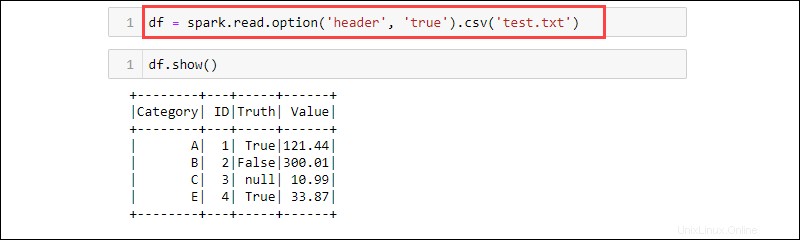
CSV adalah format tekstual di mana pembatasnya adalah koma (,) dan oleh karena itu fungsinya dapat membaca data dari file teks.
Membuat dari file JSON
Buat Spark DataFrame dari file JSON dengan menjalankan:
df = spark.read.json('<file name>.json')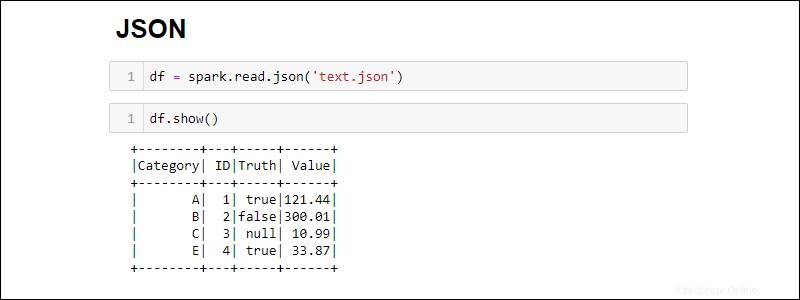
Membuat dari file XML
Kompatibilitas file XML tidak tersedia secara default. Instal dependensi untuk membuat DataFrame dari sumber XML.
1. Unduh dependensi Spark XML. Simpan .jar file di folder Spark jar.
2. Baca file XML ke dalam DataFrame dengan menjalankan:
df = spark.read\
.format('com.databricks.spark.xml')\
.option('rowTag', 'row')\
.load('test.xml')
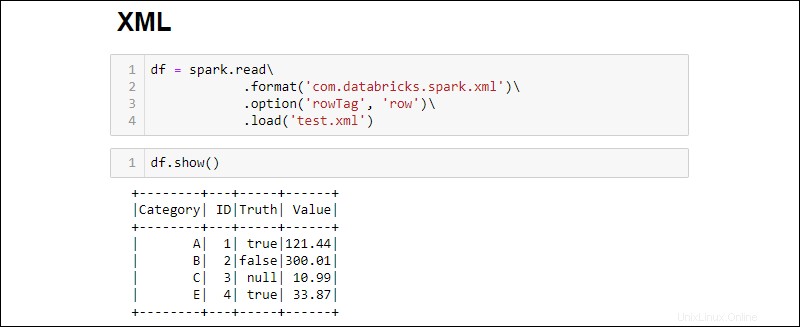
Ubah rowTag opsi jika setiap baris di XML . Anda file diberi label berbeda.
Buat DataFrame dari Basis Data RDBMS
Membaca dari RDBMS memerlukan konektor driver. Contohnya melalui cara menghubungkan dan menarik data dari database MySQL. Langkah serupa bekerja untuk tipe database lainnya.
1. Unduh konektor MySQL Java Driver. Simpan .jar file di folder Spark jar.
2. Jalankan server SQL dan buat koneksi.
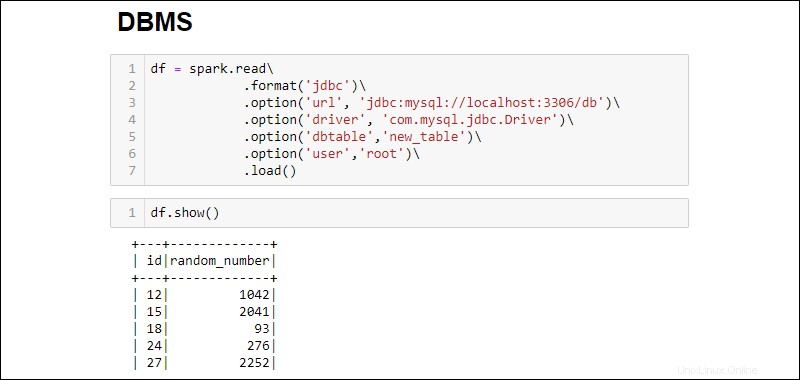
3. Buat koneksi dan ambil seluruh tabel database MySQL ke dalam DataFrame:
df = spark.read\
.format('jdbc')\
.option('url', 'jdbc:mysql://localhost:3306/db')\
.option('driver', 'com.mysql.jdbc.Driver')\
.option('dbtable','new_table')\
.option('user','root')\
.load()
Opsi yang ditambahkan adalah sebagai berikut:
- URL adalah
localhost:3306jika server berjalan secara lokal. Jika tidak, ambil URL server database Anda. - Nama basis data memperluas URL untuk mengakses database tertentu di server. Misalnya, jika database bernama
dbdan server berjalan secara lokal, URL lengkap untuk membuat koneksi adalahjdbc:mysql://localhost:3306/db. - Nama tabel memastikan seluruh tabel database ditarik ke dalam DataFrame. Gunakan
.option('query', '<query>')bukannya.option('dbtable', '<table name>')untuk menjalankan kueri tertentu daripada memilih seluruh tabel. - Gunakan nama pengguna dan sandi dari database untuk membangun koneksi. Saat menjalankan tanpa kata sandi, abaikan opsi yang ditentukan.