Agar berhasil bekerja dengan editor sed Linux dan perintah awk di skrip shell Anda, Anda harus memahami ekspresi reguler atau singkatnya regex. Karena ada banyak mesin untuk regex, kami akan menggunakan shell regex dan melihat kekuatan bash dalam bekerja dengan regex.
Pertama, kita perlu memahami apa itu regex; maka kita akan melihat cara menggunakannya.
Apa itu regex
Bagi sebagian orang, ketika mereka melihat ekspresi reguler untuk pertama kalinya, mereka mengatakan apa itu ASCII pukes !!
Nah, ekspresi reguler atau regex, secara umum, adalah pola teks yang Anda definisikan yang digunakan oleh program Linux seperti sed atau awk untuk memfilter teks.
Kami melihat beberapa pola tersebut saat memperkenalkan perintah dasar Linux dan melihat bagaimana perintah ls menggunakan karakter karakter pengganti untuk memfilter keluaran.
Jenis ekspresi reguler
Banyak aplikasi yang berbeda menggunakan berbagai jenis regex di Linux, seperti regex yang disertakan dalam bahasa pemrograman (Java, Perl, Python,) dan program Linux seperti (sed, awk, grep,) dan banyak aplikasi lainnya.
Pola regex menggunakan mesin ekspresi reguler yang menerjemahkan pola tersebut.
Linux memiliki dua mesin ekspresi reguler:
- Ekspresi Reguler Dasar (BRE) mesin.
- Extended Regular Expression (ERE) mesin.
Sebagian besar program Linux bekerja dengan baik dengan spesifikasi mesin BRE, tetapi beberapa alat seperti sed memahami beberapa aturan mesin BRE.
Mesin POSIX ERE hadir dengan beberapa bahasa pemrograman. Ini memberikan lebih banyak pola, seperti mencocokkan angka dan kata. Perintah awk menggunakan mesin ERE untuk memproses pola ekspresi regulernya.
Karena ada banyak implementasi regex, sulit untuk menulis pola yang berfungsi di semua mesin. Oleh karena itu, kami akan fokus pada regex yang paling umum ditemukan dan mendemonstrasikan cara menggunakannya di sed dan awk.
Tentukan Pola BRE
Anda dapat menentukan pola untuk mencocokkan teks seperti ini:
$ echo "Testing regex using sed" | sed -n '/regex/p'
$ echo "Testing regex using awk" | awk '/regex/{print $0}'

Anda mungkin memperhatikan bahwa ekspresi reguler tidak peduli di mana pola muncul atau berapa kali dalam aliran data.
Aturan pertama yang harus diketahui adalah bahwa pola ekspresi reguler peka terhadap huruf besar/kecil.
$ echo "Welcome to LikeGeeks" | awk '/Geeks/{print $0}' $ echo "Welcome to Likegeeks" | awk '/Geeks/{print $0}'

Regex pertama berhasil karena kata "Geeks" ada dalam huruf besar, sedangkan baris kedua gagal karena menggunakan huruf kecil.
Anda dapat menggunakan spasi atau angka dalam pola Anda seperti ini:
$ echo "Testing regex 2 again" | awk '/regex 2/{print $0}'

Karakter khusus
pola regex menggunakan beberapa karakter khusus. Dan Anda tidak dapat memasukkannya ke dalam pola Anda, dan jika Anda melakukannya, Anda tidak akan mendapatkan hasil yang diharapkan.
Karakter khusus ini dikenali oleh regex:
.*[]^${}\+?|() Anda harus keluar dari karakter khusus ini menggunakan karakter garis miring terbalik (\).
Misalnya, jika Anda ingin mencocokkan tanda dolar ($), hindari dengan karakter garis miring terbalik seperti ini:
$ cat myfile There is 10$ on my pocket
$ awk '/\$/{print $0}' myfile
Jika Anda perlu mencocokkan garis miring terbalik (\) itu sendiri, Anda harus menghindarinya seperti ini:
$ echo "\ is a special character" | awk '/\\/{print $0}'

Meskipun garis miring ke depan bukan karakter khusus, Anda masih mendapatkan kesalahan jika menggunakannya secara langsung.
$ echo "3 / 2" | awk '///{print $0}'

Jadi Anda harus menghindarinya seperti ini:
$ echo "3 / 2" | awk '/\//{print $0}'

Karakter jangkar
Untuk menemukan awal baris dalam teks, gunakan karakter tanda sisipan (^).
Anda dapat menggunakannya seperti ini:
$ echo "welcome to likegeeks website" | awk '/^likegeeks/{print $0}' $ echo "likegeeks website" | awk '/^likegeeks/{print $0}'

Karakter tanda sisipan (^) cocok dengan awal teks:
$ awk '/^this/{print $0}' myfile

Bagaimana jika Anda menggunakannya di tengah teks?
$ echo "This ^ caret is printed as it is" | sed -n '/s ^/p'

Itu dicetak seperti karakter biasa.
Saat menggunakan awk, Anda harus menghindarinya seperti ini:
$ echo "This ^ is a test" | awk '/s \^/{print $0}'

Ini tentang melihat bagian awal teks, bagaimana dengan melihat bagian akhir?
Tanda dolar ($) memeriksa akhir baris:
$ echo "Testing regex again" | awk '/again$/{print $0}'

Anda dapat menggunakan tanda sisipan dan dolar pada baris yang sama seperti ini:
$ cat myfile this is a test This is another test And this is one more
$ awk '/^this is a test$/{print $0}' myfile
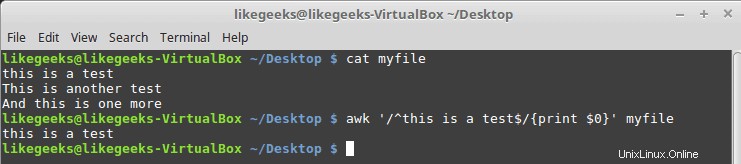
Seperti yang Anda lihat, ia hanya mencetak garis yang memiliki pola yang cocok saja.
Anda dapat memfilter baris kosong dengan pola berikut:
$ awk '!/^$/{print $0}' myfile Di sini kami memperkenalkan negasi yang dapat Anda lakukan dengan tanda seru !
Pola mencari baris kosong di mana tidak ada antara awal dan akhir baris dan meniadakan bahwa untuk mencetak hanya baris yang memiliki teks.
Karakter titik
Kami menggunakan karakter titik untuk mencocokkan karakter apa pun kecuali baris baru (\n).
Lihat contoh berikut untuk mendapatkan idenya:
$ cat myfile this is a test This is another test And this is one more start with this
$ awk '/.st/{print $0}' myfile
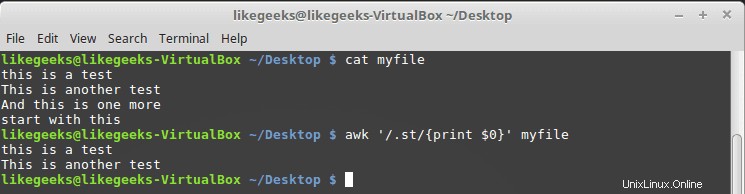
Anda dapat melihat dari hasil bahwa ia hanya mencetak dua baris pertama karena mengandung pola st sedangkan baris ketiga tidak memiliki pola itu, dan baris keempat dimulai dengan st, sehingga juga tidak cocok dengan pola kita.
Kelas karakter
Anda dapat mencocokkan karakter apa pun dengan karakter khusus titik, tetapi bagaimana jika Anda hanya mencocokkan satu set karakter, Anda dapat menggunakan kelas karakter.
Kelas karakter cocok dengan sekumpulan karakter jika ada yang ditemukan, polanya cocok.
Kita dapat mendefinisikan kelas karakter menggunakan tanda kurung siku [] seperti ini:
$ awk '/[oi]th/{print $0}' myfile
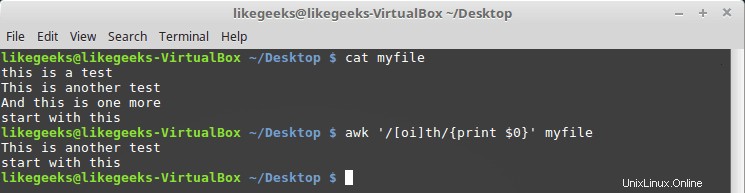
Di sini kami mencari karakter apa pun yang memiliki karakter o atau i sebelumnya.
Ini berguna saat Anda mencari kata yang mungkin berisi huruf besar atau kecil, dan Anda tidak yakin tentang itu.
$ echo "testing regex" | awk '/[Tt]esting regex/{print $0}' $ echo "Testing regex" | awk '/[Tt]esting regex/{print $0}'

Tentu saja, ini tidak terbatas pada karakter; Anda dapat menggunakan angka atau apa pun yang Anda inginkan. Anda dapat menggunakannya sesuka Anda selama Anda memiliki ide.
Meniadakan kelas karakter
Bagaimana dengan mencari karakter yang tidak ada di kelas karakter?
Untuk mencapai itu, awali rentang kelas karakter dengan tanda sisipan seperti ini:
$ awk '/[^oi]th/{print $0}' myfile
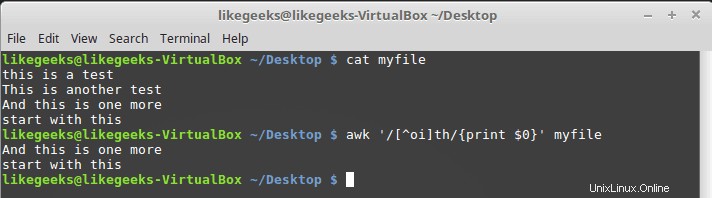
Jadi apapun bisa diterima kecuali o dan i.
Menggunakan rentang
Untuk menentukan rentang karakter, Anda dapat menggunakan simbol (-) seperti ini:
$ awk '/[e-p]st/{print $0}' myfile
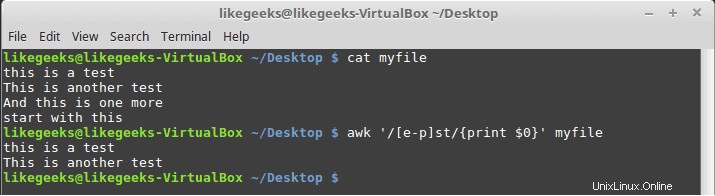
Ini cocok dengan semua karakter antara e dan p kemudian diikuti oleh st seperti yang ditunjukkan.
Anda juga dapat menggunakan rentang untuk angka:
$ echo "123" | awk '/[0-9][0-9][0-9]/'
$ echo "12a" | awk '/[0-9][0-9][0-9]/'

Anda dapat menggunakan beberapa rentang dan terpisah seperti ini:
$ awk '/[a-fm-z]st/{print $0}' myfile
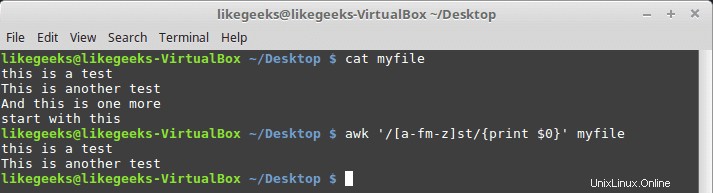
Pola di sini berarti dari a sampai f, dan m sampai z harus muncul sebelum teks pertama.
Kelas karakter khusus
Daftar berikut termasuk kelas karakter khusus yang dapat Anda gunakan:
| [[:alnum:]] | Pola untuk 0–9, A–Z, atau a–z. |
| [[:blank:]] | Pola untuk spasi atau Tab saja. |
| [[:digit:]] | Pola untuk 0 hingga 9. |
| [[:bawah:]] | Pola untuk huruf kecil a–z saja. |
| [[:print:]] | Pola untuk setiap karakter yang dapat dicetak. |
| [[:punct:]] | Pola untuk karakter tanda baca apa pun. |
| [[:spasi:]] | Pola untuk karakter spasi putih apa pun:spasi, Tab, NL, FF, VT, CR. |
| [[:upper:]] | Pola untuk huruf besar A–Z saja. |
Anda dapat menggunakannya seperti ini:
$ echo "abc" | awk '/[[:alpha:]]/{print $0}' $ echo "abc" | awk '/[[:digit:]]/{print $0}' $ echo "abc123" | awk '/[[:digit:]]/{print $0}'

Tanda bintang
Tanda bintang berarti karakter harus ada nol kali atau lebih.
$ echo "test" | awk '/tes*t/{print $0}' $ echo "tessst" | awk '/tes*t/{print $0}'

Simbol pola ini berguna untuk memeriksa kesalahan ejaan atau variasi bahasa.
$ echo "I like green color" | awk '/colou*r/{print $0}' $ echo "I like green color" | awk '/colou*r/{print $0}'

Di sini, dalam contoh ini, apakah Anda mengetiknya warna atau warna itu akan cocok, karena tanda bintang berarti jika karakter "u" ada berkali-kali atau nol waktu yang akan cocok.
Untuk mencocokkan sejumlah karakter apa pun, Anda dapat menggunakan titik dengan tanda bintang seperti ini:
$ awk '/this.*test/{print $0}' myfile
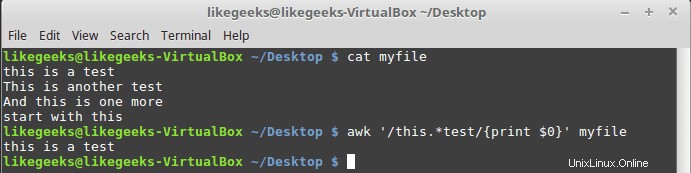
Tidak peduli berapa banyak kata di antara kata "ini" dan "ujian", baris mana pun yang cocok, akan dicetak.
Anda dapat menggunakan karakter asterisk dengan kelas karakter.
$ echo "st" | awk '/s[ae]*t/{print $0}' $ echo "sat" | awk '/s[ae]*t/{print $0}' $ echo "set" | awk '/s[ae]*t/{print $0}'
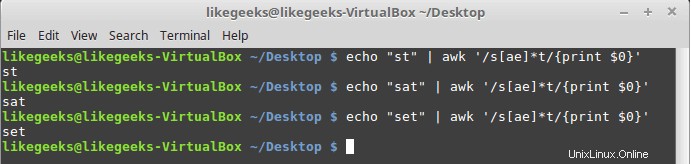
Ketiga contoh cocok karena tanda bintang berarti jika Anda menemukan nol kali atau lebih karakter “a” atau “e”, cetaklah.
Ekspresi reguler yang diperluas
Berikut ini adalah beberapa pola yang dimiliki oleh Posix ERE:
Tanda tanya
Tanda tanya berarti karakter sebelumnya bisa ada sekali atau tidak sama sekali.
$ echo "tet" | awk '/tes?t/{print $0}' $ echo "test" | awk '/tes?t/{print $0}' $ echo "test" | awk '/tes?t/{print $0}'
Kita dapat menggunakan tanda tanya dalam kombinasi dengan kelas karakter:
$ echo "tst" | awk '/t[ae]?st/{print $0}' $ echo "test" | awk '/t[ae]?st/{print $0}' $ echo "tast" | awk '/t[ae]?st/{print $0}' $ echo "taest" | awk '/t[ae]?st/{print $0}' $ echo "test" | awk '/t[ae]?st/{print $0}'
Jika salah satu item kelas karakter ada, pencocokan pola akan lolos. Jika tidak, polanya akan gagal.
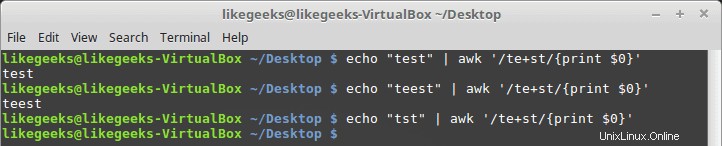
Tanda plus
Tanda plus berarti bahwa karakter sebelum tanda plus harus ada satu kali atau lebih, tetapi harus ada setidaknya satu kali.
$ echo "test" | awk '/te+st/{print $0}' $ echo "test" | awk '/te+st/{print $0}' $ echo "tst" | awk '/te+st/{print $0}'
Jika karakter "e" tidak ditemukan, itu gagal.
Anda dapat menggunakannya dengan kelas karakter seperti ini:
$ echo "tst" | awk '/t[ae]+st/{print $0}' $ echo "test" | awk '/t[ae]+st/{print $0}' $ echo "teast" | awk '/t[ae]+st/{print $0}' $ echo "teeast" | awk '/t[ae]+st/{print $0}'
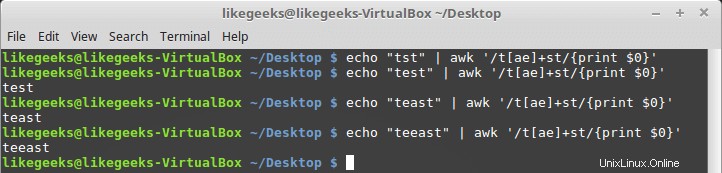
jika ada karakter dari kelas karakter, itu berhasil.
Kurung kurawal
Kurung kurawal memungkinkan Anda menentukan jumlah keberadaan suatu pola, pola ini memiliki dua format:
n:Regex muncul tepat n kali.
n,m:Ekspresi reguler muncul setidaknya n kali, tetapi tidak lebih dari m kali.
$ echo "tst" | awk '/te{1}st/{print $0}' $ echo "test" | awk '/te{1}st/{print $0}'

Di awk versi lama, Anda harus menggunakan opsi –re-interval untuk perintah awk agar membaca kurung kurawal, tetapi di versi yang lebih baru, Anda tidak memerlukannya.
$ echo "tst" | awk '/te{1,2}st/{print $0}' $ echo "test" | awk '/te{1,2}st/{print $0}' $ echo "test" | awk '/te{1,2}st/{print $0}' $ echo "teeest" | awk '/te{1,2}st/{print $0}'

Dalam contoh ini, jika karakter "e" ada satu atau dua kali, itu berhasil; jika tidak, gagal.
Anda dapat menggunakannya dengan kelas karakter seperti ini:
$ echo "tst" | awk '/t[ae]{1,2}st/{print $0}' $ echo "test" | awk '/t[ae]{1,2}st/{print $0}' $ echo "test" | awk '/t[ae]{1,2}st/{print $0}' $ echo "teeast" | awk '/t[ae]{1,2}st/{print $0}'
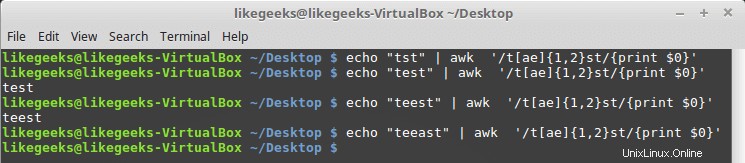
Jika ada satu atau dua contoh huruf "a" atau "e", polanya lolos; jika tidak, gagal.
Simbol pipa
Simbol pipa membuat OR logis antara 2 pola. Jika salah satu pola ada, itu berhasil; jika tidak, gagal, ini contohnya:
$ echo "Testing regex" | awk '/regex|regular expressions/{print $0}' $ echo "Testing regex" | awk '/regex|regular expressions/{print $0}' $ echo "This is something else" | awk '/regex|regular expressions/{print $0}'
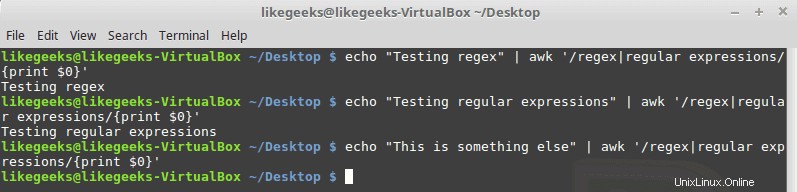
Jangan ketik spasi di antara pola dan simbol pipa.
Mengelompokkan ekspresi
Anda dapat mengelompokkan ekspresi sehingga mesin regex akan menganggapnya sebagai satu kesatuan.
$ echo "Like" | awk '/Like(Geeks)?/{print $0}' $ echo "LikeGeeks" | awk '/Like(Geeks)?/{print $0}'
Pengelompokan "Geeks" membuat mesin regex memperlakukannya sebagai satu kesatuan, jadi jika "LikeGeeks" atau kata "Suka" ada, itu berhasil.
Contoh praktis
Kami melihat beberapa demonstrasi sederhana menggunakan pola ekspresi reguler. Saatnya untuk menerapkannya, hanya untuk berlatih.
Menghitung file direktori
Mari kita lihat skrip bash yang menghitung file yang dapat dieksekusi dalam folder dari variabel lingkungan PATH.
$ echo $PATH
Untuk mendapatkan daftar direktori, Anda harus mengganti setiap titik dua dengan spasi.
$ echo $PATH | sed 's/:/ /g'
Sekarang mari kita ulangi setiap direktori menggunakan for loop seperti ini:
mypath=$(echo $PATH | sed 's/:/ /g') for directory in $mypath; do done
Hebat!!
Anda bisa mendapatkan file di setiap direktori menggunakan perintah ls dan menyimpannya dalam variabel.
#!/bin/bash path_dir=$(echo $PATH | sed 's/:/ /g') total=0 for folder in $path_dir; do files=$(ls $folder) for file in $files; do total=$(($total + 1)) done echo "$folder - $total" total=0 done
Anda mungkin melihat beberapa direktori tidak ada, tidak masalah dengan ini, tidak apa-apa.
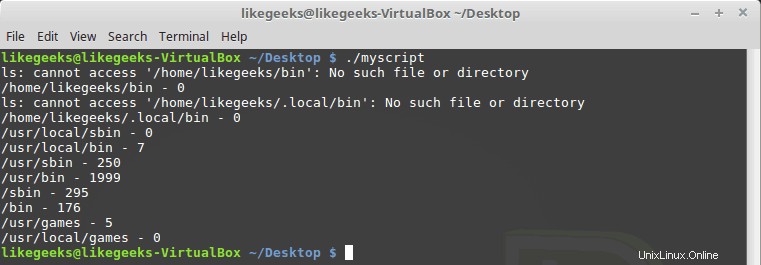
Dingin!! Inilah kekuatan regex—beberapa baris kode ini menghitung semua file di semua direktori. Tentu saja, ada perintah Linux untuk melakukannya dengan sangat mudah, tetapi di sini kita membahas cara menggunakan regex pada sesuatu yang dapat Anda gunakan. Anda dapat menemukan beberapa ide yang lebih berguna.
Memvalidasi alamat email
Ada banyak sekali situs web yang menawarkan pola regex siap pakai untuk semuanya, termasuk email, nomor telepon, dan banyak lagi, ini berguna, tetapi kami ingin memahami cara kerjanya.
contoh@unixlinux.online
Nama pengguna dapat menggunakan karakter alfanumerik apa pun yang dikombinasikan dengan titik, tanda hubung, tanda tambah, garis bawah.
Nama host dapat menggunakan karakter alfanumerik apa pun yang dikombinasikan dengan titik dan garis bawah.
Untuk nama pengguna, pola berikut cocok untuk semua nama pengguna:
^([a-zA-Z0-9_\-\.\+]+)@
Tanda plus berarti satu karakter atau lebih harus ada diikuti dengan tanda @.
Maka pola hostname harus seperti ini:
([a-zA-Z0-9_\-\.]+)
Ada aturan khusus untuk TLD atau domain tingkat atas, dan aturan tersebut tidak boleh kurang dari 2 dan maksimal lima karakter. Berikut ini adalah pola regex untuk domain tingkat atas.
\.([a-zA-Z]{2,5})$ Sekarang kita gabungkan semuanya:
^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$ Mari kita uji ekspresi reguler itu dengan email:
$ echo "example@unixlinux.online" | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/{print $0}' $ echo "example@unixlinux.online" | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/{print $0}'

Luar biasa!!
Ini hanyalah awal dari dunia regex yang tidak pernah berakhir. Saya harap Anda memahami muntahan ASCII ini dan menggunakannya secara lebih profesional.
Saya harap Anda menyukai postingan ini.
Terima kasih.