Pendahuluan
phoenixNAP Bare Metal Cloud menampilkan antarmuka API RESTful yang memungkinkan pengembang mengotomatiskan pembuatan server bare metal.
Untuk mendemonstrasikan kemampuan sistem, artikel ini menjelaskan dan memberikan contoh kode Python tentang cara memanfaatkan BMC API untuk mengotomatiskan penyediaan kluster Spark di Bare Metal Cloud .

Prasyarat
- akun phoenixNAP Bare Metal Cloud
- Token akses OAuth
Cara Mengotomatiskan Penerapan Spark Cluster
Petunjuk di bawah ini berlaku untuk lingkungan Bare Metal Cloud phoenixNAP. Contoh kode Python yang ditemukan di artikel ini mungkin tidak berfungsi di lingkungan lain.
Langkah-langkah yang diperlukan untuk menerapkan dan mengakses kluster Apache Spark:
1. Buat token akses.
2. Buat server Bare Metal Cloud yang menjalankan OS Ubuntu.
3. Terapkan cluster Apache Spark pada instance server yang dibuat.
4. Akses dasbor Apache Spark dengan mengikuti tautan yang dibuat.
Artikel ini menyoroti subset segmen kode Python yang memanfaatkan Bare Metal Cloud API dan perintah shell untuk menyelesaikan langkah-langkah yang diuraikan di atas.
Langkah 1:Dapatkan Token Akses
Sebelum mengirim permintaan ke BMC API, Anda harus mendapatkan token akses OAuth menggunakan client_id dan rahasia_klien terdaftar di Portal BMC.
Untuk mempelajari lebih lanjut tentang cara mendaftar client_id dan client_secret, lihat panduan Memulai Cepat Bare Metal Cloud API.
Di bawah ini adalah fungsi Python yang menghasilkan token akses untuk API:
def get_access_token(client_id: str, client_secret: str) -> str:
"""Retrieves an access token from BMC auth by using the client ID and the
client Secret."""
credentials = "%s:%s" % (client_id, client_secret)
basic_auth = standard_b64encode(credentials.encode("utf-8"))
response = requests.post(' https://api.phoenixnap.com/bmc/v0/servers',
headers={
'Content-Type': 'application/x-www-form-urlencoded',
'Authorization': 'Basic %s' % basic_auth.decode("utf-8")},
data={'grant_type': 'client_credentials'})
if response.status_code != 200:
raise Exception('Error: {}. {}'.format(response.status_code, response.json()))
return response.json()['access_token']
Langkah 2:Buat Instance Server Bare Metal
Gunakan panggilan POST/server REST API untuk membuat instance server bare metal. Untuk setiap permintaan POST/server, tentukan parameter yang diperlukan, seperti lokasi pusat data, jenis server, OS, dll.
Di bawah ini adalah fungsi Python yang membuat panggilan ke BMC API untuk membuat server bare metal.
def __do_create_server(session, server):
response = session.post('https://api.phoenixnap.com/bmc/v0/servers'),
data=json.dumps(server))
if response.status_code != 200:
print("Error creating server: {}".format(json.dumps(response.json())))
else:
print("{}".format(json.dumps(response.json())))
return response.json()
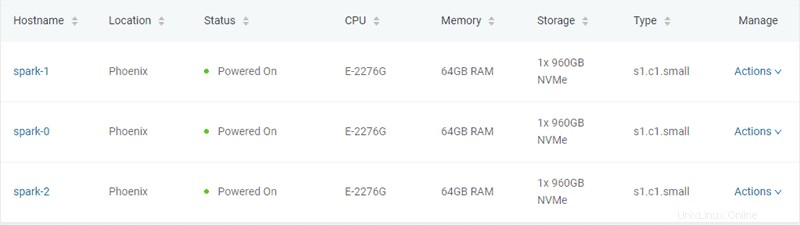
Dalam contoh ini, tiga server bare metal tipe "s1.c1.small" dibuat, seperti yang ditentukan dalam file server-settings.conf.
{
"ssh-key" : "ssh-rsa xxxxxx== username",
"servers_quantity" : 3,
"type" : "s1.c1.small",
"hostname" : "spark",
"description" : "spark",
"public" : True,
"location" : "PHX",
"os" : "ubuntu/bionic"
}
Output yang diharapkan dari skrip Python yang menghasilkan token dan menyediakan server adalah sebagai berikut:
Retrieving token
Successfully retrieved API token
Creating servers...
{
"id": "5ee9c1b84a9ca71ea6b9b766",
"status": "creating",
"hostname": "spark-1",
"description": "spark-1",
"os": "ubuntu/bionic",
"type": "s1.c1. small ",
"location": "PHX",
"cpu": "E-2276G",
"ram": "128GB RAM",
"storage": "2x 960GB NVMe",
"privateIpAddresses": [
"10.0.0.11"
],
"publicIpAddresses": [
"131.153.143.250",
"131.153.143.251",
"131.153.143.252",
"131.153.143.253",
"131.153.143.254"
]
}
Server created, provisioning spark-1...
{
"id": "5ee9c1b84a9ca71ea6b9b767",
"status": "creating",
"hostname": "spark-0",
"description": "spark-0",
"os": "ubuntu/bionic",
"type": "s1.c1.small",
"location": "PHX",
"cpu": "E-2276G",
"ram": "128GB RAM",
"storage": "2x 960GB NVMe",
"privateIpAddresses": [
"10.0.0.12"
],
"publicIpAddresses": [
"131.153.143.50",
"131.153.143.51",
"131.153.143.52",
"131.153.143.53",
"131.153.143.54"
]
}
Server created, provisioning spark-0...
{
"id": "5ee9c1b84a9ca71ea6b9b768",
"status": "creating",
"hostname": "spark-2",
"description": "spark-2",
"os": "ubuntu/bionic",
"type": "s1.c1. small ",
"location": "PHX",
"cpu": "E-2276G",
"ram": "128GB RAM",
"storage": "2x 960GB NVMe",
"privateIpAddresses": [
"10.0.0.13"
],
"publicIpAddresses": [
"131.153.142.234",
"131.153.142.235",
"131.153.142.236",
"131.153.142.237",
"131.153.142.238"
]
}
Server created, provisioning spark-2...
Waiting for servers to be provisioned... Setelah membuat tiga server bare metal, skrip berkomunikasi dengan BMC API untuk memeriksa status server hingga penyediaan selesai dan server dihidupkan.
Langkah 3:Sediakan Apache Spark Cluster
Setelah server disediakan, skrip Python membuat koneksi SSH menggunakan alamat IP publik server. Selanjutnya, skrip menginstal Spark di server Ubuntu. Itu termasuk memasang JDK , Skala , Git dan Percikan di semua server.
Untuk memulai proses, jalankan all_hosts.sh file di semua server. Script menyediakan petunjuk pengunduhan dan penginstalan serta konfigurasi lingkungan yang diperlukan untuk mempersiapkan cluster untuk digunakan.
Apache Spark menyertakan skrip yang mengonfigurasi server sebagai node master dan pekerja. Satu-satunya kendala dalam mengonfigurasi node pekerja adalah sudah memiliki node master yang dikonfigurasi. Server pertama yang disediakan ditetapkan sebagai node Spark Master.
Fungsi Python berikut melakukan tugas itu:
def wait_server_ready(function_scheduler, server_data):
json_server = bmc_api.get_server(REQUEST, server_data['id'])
if json_server['status'] == "creating":
main_scheduler.enter(2, 1, wait_server_ready, (function_scheduler, server_data))
elif json_server['status'] == "powered-on" and not data['has_a_master_server']:
server_data['status'] = json_server['status']
server_data['master'] = True
server_data['joined'] = True
data['has_a_master_server'] = True
data['master_ip'] = json_server['publicIpAddresses'][0]
data['master_hostname'] = json_server['hostname']
print("ASSIGNED MASTER SERVER: {}".format(data['master_hostname']))Jalankan master_host.sh file untuk mengkonfigurasi server pertama sebagai node Master. Lihat di bawah konten master_host.sh berkas:
#!/bin/bash
echo "Setting up master node"
/opt/spark/sbin/start-master.shSetelah node master ditetapkan dan dikonfigurasi, dua node lainnya ditambahkan ke kluster Spark.
Lihat di bawah konten worker_host.sh berkas:
#!/bin/bash
echo "Setting up master node on /etc/hosts"
echo "$1 $2 $2" | sudo tee -a /etc/hosts
echo "Starting worker node"
echo "Joining worker node to the cluster"
/opt/spark/sbin/start-slave.sh spark://$2:7077
Penyediaan cluster Apache Spark selesai. Di bawah ini adalah output yang diharapkan dari skrip Python:
ASSIGNED MASTER SERVER: spark-2
Running all_host.sh script on spark-2 (Public IP: 131.153.142.234)
Setting up /etc/hosts
Installing jdk, scala and git
Downloading spark-2.4.5
Unzipping spark-2.4.5
Setting up environment variables
Running master_host.sh script on spark-2 (Public IP: 131.153.142.234)
Setting up master node
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-ubuntu-org.apache.spark.deploy.master.Master-1-spark-2.out
Master host installed
Running all_host.sh script on spark-0 (Public IP: 131.153.143.170)
Setting up /etc/hosts
Installing jdk, scala and git
Downloading spark-2.4.5
Unzipping spark-2.4.5
Setting up environment variables
Running all_host.sh script on spark-1 (Public IP: 131.153.143.50)
Setting up /etc/hosts
Installing jdk, scala and git
Downloading spark-2.4.5
Unzipping spark-2.4.5
Setting up environment variables
Running slave_host.sh script on spark-0 (Public IP: 131.153.143.170)
Setting up master node on /etc/hosts
10.0.0.12 spark-2 spark-2
Starting worker node
Joining worker node to the cluster
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-ubuntu-org.apache.spark.deploy.worker.Worker-1-spark-0.out
Running slave_host.sh script on spark-1 (Public IP: 131.153.143.50)
Setting up master node on /etc/hosts
10.0.0.12 spark-2 spark-2
Starting worker node
Joining worker node to the cluster
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-ubuntu-org.apache.spark.deploy.worker.Worker-1-spark-1.out
Setup servers done
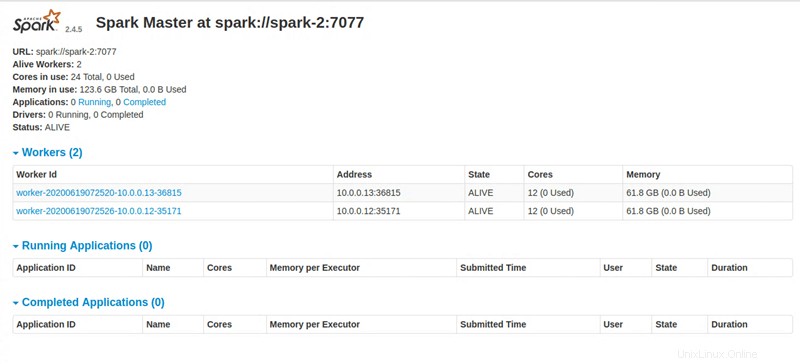
Master node UI: http://131.153.142.234:8080
Langkah 4:Akses Dasbor Apache Spark
Setelah menjalankan semua instruksi, skrip Python menyediakan tautan untuk mengakses dasbor Apache Spark.