Pendahuluan
Basis data NoSQL memungkinkan kami menyimpan sejumlah besar data dan mengaksesnya setiap saat, dari lokasi dan perangkat apa pun. Namun, sulit untuk memutuskan teknik pemodelan data mana yang paling sesuai dengan kebutuhan Anda. Untungnya, ada teknik pemodelan data untuk setiap kasus penggunaan.
Dalam tutorial ini kita akan membahas semua teknik pemodelan data NoSQL yang berbeda yang dapat Anda gunakan saat membangun database NoSQL Anda.

Apa itu Model Data NoSQL?
NoSQL atau 'Not Only SQL' adalah model data yang sangat berbeda dari ekspektasi SQL tradisional.
Perbedaan utama adalah bahwa NoSQL tidak menggunakan teknik pemodelan data relasional dan menekankan desain yang fleksibel. Kurangnya persyaratan untuk skema membuat merancang proses yang lebih sederhana dan lebih murah. Itu tidak berarti bahwa Anda tidak dapat menggunakan skema sama sekali, tetapi desain skema sangat fleksibel.
Fitur lain yang berguna dari model data NoSQL adalah model tersebut dibuat untuk efisiensi dan kecepatan tinggi dalam hal membuat hingga jutaan kueri per detik. Ini dicapai dengan memiliki semua data yang terkandung dalam satu tabel, sehingga GABUNG dan referensi silang tidak terlalu berat kinerjanya.
NoSQL juga unik karena dapat diskalakan secara horizontal , dibandingkan dengan SQL yang hanya dapat diskalakan secara vertikal. Dengan NoSQL Anda cukup menggunakan pecahan lain, yang murah, daripada membeli lebih banyak perangkat keras, yang tidak.
Empat Jenis Database NoSQL
Secara umum, ada empat jenis database NoSQL, dengan lusinan model data berdasarkan mereka:
Toko Nilai Kunci
Dibuat khusus untuk persyaratan kinerja tinggi, dan mungkin salah satu model data yang paling umum, penyimpanan nilai kunci menggunakan nilai kunci dengan pointer untuk menyimpan data.
Pointer ini unik dan terhubung langsung ke sepotong informasi, yang bisa berupa apa saja yang Anda inginkan. Anda bahkan dapat menggunakan string kosong sebagai kunci nilai jika Anda mau, meskipun ada batas atas seberapa besar nilai bergantung pada database.
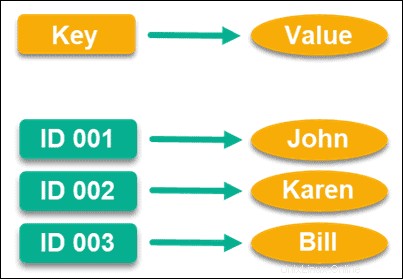
Yang cukup menarik, Amazonlah yang awalnya membantu meluncurkan model data ini, dan mereka menggunakannya untuk DynamoDB. Mengingat bahwa mereka adalah salah satu pasar online terbesar di dunia, Anda dapat melihat seberapa tinggi kinerja model data ini.
Toko Berbasis Dokumen
Dengan SQL, XML dan JSON cenderung terikat bersama, yang memperlambat kueri dan menghambat keseluruhan proses. Karena NoSQL tidak menggunakan model relasional, ia tidak perlu melakukan itu, di situlah toko berbasis dokumen masuk.
Semua data disimpan dalam satu tabel, jadi tidak perlu referensi silang dan alih-alih menyimpan informasi dalam tabel, data disimpan dalam dokumen. Meskipun ini sangat mirip dengan penyimpanan nilai kunci, dan terkadang dapat dianggap di bawah payungnya, perbedaannya adalah bahwa NoSQL berbasis dokumen umumnya memiliki beberapa bentuk pengkodean, seperti XML.
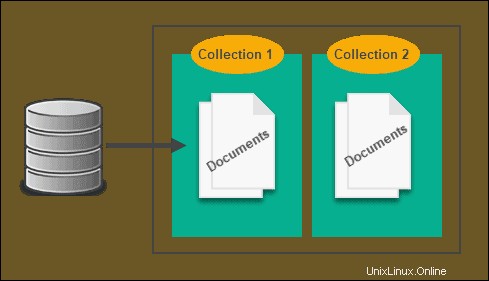
Ada database NoSQL khusus XML yang menggunakan penyimpanan dokumen. Faktanya, CD Strider menggunakan MongoDB sebagai penyimpanan cadangan.
Toko Berbasis Kolom
Jenis model data ini menyimpan informasi dalam kolom, bukan dalam baris yang lebih biasa dengan SQL. Data disimpan dalam kolom, yang dikelompokkan ke dalam keluarga, dan keluarga ini selanjutnya dikelompokkan ke dalam lebih banyak kolom. Ini pada dasarnya menciptakan model data nestling kolom yang hampir tak terbatas.
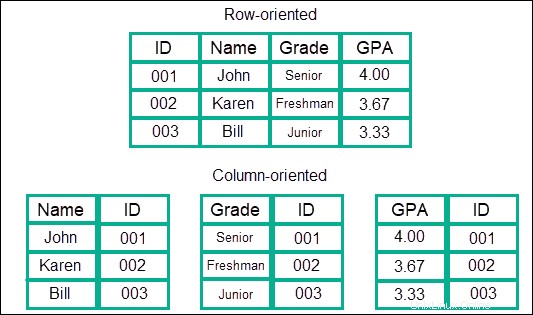
Manfaatnya adalah ia menawarkan kecepatan yang sangat cepat dibandingkan dengan model lain atau NoSQL dalam hal pencarian. Data diperlakukan sebagai satu entri berkelanjutan, dan oleh karena itu tidak perlu melompati baris atau area berbeda tempat informasi disimpan.
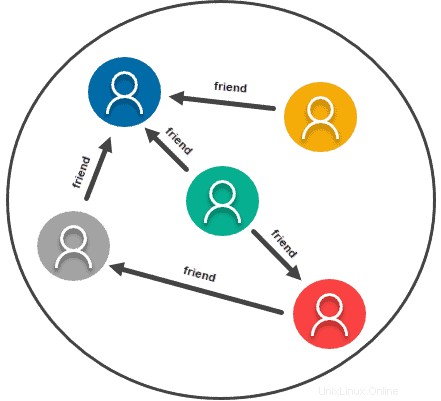
Toko Berbasis Grafik
Grafik atau model data jaringan pada dasarnya memperlakukan hubungan antara dua bagian informasi sama pentingnya dengan informasi itu sendiri. Dengan demikian, jenis model data ini benar-benar dibuat untuk informasi apa pun yang biasanya Anda wakili pada grafik. Ini menggunakan hubungan dan node, dengan data menjadi informasi itu sendiri, dan hubungan terbentuk antara node.
Bagaimana Data Disimpan di NoSQL?
Penyimpanan data NoSQL bergantung pada jenis database yang Anda gunakan. Karena NoSQL tidak memerlukan skema, tidak ada cetak biru tentang bagaimana data harus disimpan, dan oleh karena itu bervariasi antar database.
Secara umum, ada dua cara fungsi penyimpanan data NoSQL:
- Di disk menggunakan B-Trees , dengan bagian atasnya berada secara permanen di RAM.
- Dalam memori di mana semuanya ada di RAM menggunakan RB-Trees dan apa pun yang disimpan di disk hanyalah tambahan.
Desain Skema untuk NoSQL
Karena database NoSQL tidak benar-benar memiliki struktur yang ditetapkan, pengembangan dan desain skema cenderung berfokus pada model data fisik. Itu berarti berkembang untuk lingkungan yang besar dan luas secara horizontal, sesuatu yang menjadi keunggulan NoSQL. Oleh karena itu, kebiasaan dan masalah khusus yang terkait dengan skalabilitas berada di garis depan.
Dengan demikian, langkah pertama adalah menentukan kebutuhan bisnis, karena mengoptimalkan akses data adalah suatu keharusan, dan hanya dapat dicapai dengan mengetahui apa yang inginkan bisnis. hubungannya dengan data. Desain skema Anda harus melengkapi alur kerja yang terkait dengan kasus penggunaan Anda.
Ada beberapa cara untuk memilih kunci utama, dan pada akhirnya itu tergantung pada pengguna itu sendiri. Meskipun demikian, beberapa data mungkin menyarankan skema yang lebih efisien, terutama dalam hal seberapa sering data tersebut ditanyakan.
Teknik Pemodelan Data NoSQL
Semua teknik pemodelan data NoSQL dikelompokkan menjadi tiga kelompok besar:
- Teknik konseptual
- Teknik pemodelan umum
- Teknik pemodelan hierarki
Di bawah ini, kita akan membahas secara singkat semua teknik pemodelan data NoSQL.
Teknik Konseptual
Ada tiga teknik konseptual untuk pemodelan data NoSQL:
- Denormalisasi . Denormalisasi adalah teknik yang cukup umum dan memerlukan penyalinan data ke dalam beberapa tabel atau formulir untuk menyederhanakannya. Dengan denormalisasi, kelompokkan semua data yang perlu ditanyakan dengan mudah di satu tempat. Tentu saja, ini berarti bahwa volume data meningkat untuk parameter yang berbeda, yang meningkatkan volume data secara signifikan.
- Agregat . Hal ini memungkinkan pengguna untuk membentuk entitas bersarang dengan struktur internal yang kompleks, serta memvariasikan struktur khusus mereka. Pada akhirnya, agregasi mengurangi bergabung dengan meminimalkan hubungan satu-ke-satu.
Sebagian besar model data NoSQL memiliki beberapa bentuk teknik skema lunak ini. Misalnya, grafik dan database penyimpanan nilai kunci memiliki nilai yang dapat berupa format apa pun, karena model data tersebut tidak menempatkan batasan pada nilai. Demikian pula, contoh lain seperti BigTable memiliki agregasi melalui kolom dan kelompok kolom. - Sisi Aplikasi Bergabung. NoSQL biasanya tidak mendukung penggabungan, karena database NoSQL berorientasi pada pertanyaan di mana penggabungan dilakukan selama waktu desain. Ini dibandingkan dengan database relasional yang dilakukan pada waktu eksekusi kueri. Tentu saja, ini cenderung menghasilkan penalti kinerja dan terkadang tidak dapat dihindari.
Teknik Pemodelan Umum
Ada lima teknik umum untuk pemodelan data NoSQL:
- Kunci yang Dapat Dihitung . Untuk sebagian besar, nilai kunci yang tidak berurutan sangat berguna, karena entri dapat dipartisi melalui beberapa server khusus hanya dengan melakukan hashing kunci. Meskipun demikian, menambahkan beberapa bentuk fungsi penyortiran melalui kunci yang diurutkan berguna, meskipun dapat menambah sedikit lebih banyak kerumitan dan peningkatan kinerja.
- Pengurangan Dimensi . Sistem informasi geografis cenderung menggunakan R-Tree indeks dan perlu diperbarui di tempat, yang bisa mahal jika berurusan dengan volume data yang besar. Pendekatan tradisional lainnya adalah meratakan struktur 2D menjadi daftar polos, seperti yang dilakukan dengan Geohash.
Dengan pengurangan dimensi, Anda dapat memetakan data multidimensi ke nilai kunci sederhana atau bahkan model non-multidimensi.
Gunakan reduksi dimensi untuk memetakan data multidimensi ke model Nilai Kunci atau ke model non-multidimensi lainnya. - Tabel Indeks. Dengan tabel indeks, manfaatkan indeks di toko yang belum tentu mendukungnya secara internal. Bertujuan untuk membuat dan kemudian memelihara tabel unik dengan kunci yang mengikuti pola akses tertentu. Misalnya, tabel master untuk menyimpan akun pengguna untuk diakses berdasarkan ID pengguna.
- Indeks Kunci Gabungan . Meskipun merupakan teknik umum, kunci komposit sangat berguna saat kunci yang dipesan digunakan. Jika Anda mengambilnya dan menggabungkannya dengan kunci sekunder, Anda dapat membuat indeks multidimensi yang sangat mirip dengan teknik Pengurangan Dimensi yang disebutkan di atas.
- Penelusuran Terbalik – Agregasi Langsung. Konsep di balik teknik ini adalah menggunakan indeks yang memenuhi serangkaian kriteria tertentu, tetapi kemudian menggabungkan data tersebut dengan pemindaian penuh atau beberapa bentuk representasi asli.
Ini lebih merupakan pola pemrosesan data daripada pemodelan data, namun model data pasti terpengaruh dengan menggunakan jenis pola pemrosesan ini. Mempertimbangkan bahwa pengambilan catatan secara acak yang diperlukan untuk teknik ini tidak efisien. Gunakan pemrosesan kueri dalam kelompok untuk mengurangi masalah ini.
Teknik Pemodelan Hirarki
Ada tujuh teknik pemodelan hierarki untuk data NoSQL:
- Agregasi Pohon. Agregasi pohon pada dasarnya memodelkan data sebagai satu dokumen. Ini bisa sangat efisien jika menyangkut catatan apa pun yang selalu diakses sekaligus, seperti utas Twitter atau pos Reddit. Tentu saja, masalahnya kemudian adalah akses acak ke setiap entri individu tidak efisien.
- Daftar Ketetanggaan. Ini adalah teknik langsung di mana node dimodelkan sebagai catatan independen dari array dengan nenek moyang langsung. Itu cara yang rumit untuk mengatakan bahwa itu memungkinkan Anda untuk mencari node oleh orang tua atau anak-anak mereka. Sama seperti agregasi pohon, ini juga cukup tidak efisien untuk mengambil seluruh subpohon untuk setiap simpul yang diberikan.
- Jalur Terwujud. Teknik ini adalah semacam denormalisasi dan digunakan untuk menghindari traversal rekursif dalam struktur pohon. Terutama, kami ingin mengatributkan parent atau children ke setiap node, yang membantu kami menentukan pendahulu atau turunan dari node tanpa mengkhawatirkan traversal. Kebetulan, kami dapat menyimpan jalur yang terwujud sebagai ID, baik sebagai set atau string tunggal.
- Set Bersarang . Teknik standar untuk struktur seperti pohon dalam database relasional, ini juga berlaku untuk NoSQL dan database nilai kunci atau dokumen. Tujuannya adalah untuk menyimpan daun pohon sebagai larik dan kemudian memetakan setiap simpul non-daun ke rentang daun menggunakan indeks awal/akhir.
Memodelkannya dengan cara ini adalah cara yang efisien untuk menangani data yang tidak dapat diubah karena hanya membutuhkan sedikit memori, dan tidak harus menggunakan traversal. Meskipun demikian, pembaruan itu mahal karena memerlukan pembaruan indeks. - Perataan Dokumen Bersarang:Nama Bidang Bernomor. Sebagian besar mesin pencari cenderung bekerja dengan dokumen yang merupakan daftar bidang dan nilai yang datar, daripada sesuatu dengan struktur internal yang kompleks. Dengan demikian, teknik pemodelan data ini mencoba memetakan struktur kompleks ini ke dokumen biasa, misalnya, memetakan dokumen dengan struktur hierarkis, kesulitan umum yang mungkin Anda temui.
Tentu saja, jenis pekerjaan ini sulit dan tidak mudah terukur, terutama karena struktur bersarang meningkat. - Perataan Dokumen Bersarang:Kueri Kedekatan. Salah satu cara untuk memecahkan masalah potensial dengan teknik pemodelan data Numbered Field Names adalah dengan menggunakan teknik serupa yang disebut Kueri Kedekatan. Ini membatasi jarak antar kata dalam dokumen, yang membantu meningkatkan kinerja dan mengurangi dampak kecepatan kueri.
- Pemrosesan Grafik Batch. Pemrosesan grafik batch adalah teknik yang bagus untuk menjelajahi hubungan ke atas atau ke bawah untuk sebuah node, dalam beberapa langkah. Ini adalah proses yang mahal dan belum tentu berskala sangat baik. Dengan menggunakan Message Passing dan MapReduce kita dapat melakukan pemrosesan grafik jenis ini.