Artikel ini melihat mount namespace dan merupakan yang ketiga dalam seri Namespace Linux. Dalam artikel pertama, saya memberikan pengantar tentang tujuh ruang nama yang paling umum digunakan, meletakkan dasar untuk pekerjaan langsung yang dimulai di artikel ruang nama pengguna. Tujuan saya adalah untuk membangun beberapa pengetahuan mendasar tentang bagaimana dasar-dasar wadah Linux bekerja. Jika Anda tertarik dengan bagaimana Linux mengontrol sumber daya pada suatu sistem, lihat seri CGroup, yang saya tulis sebelumnya. Mudah-mudahan, pada saat Anda selesai dengan pekerjaan langsung namespaces, saya dapat mengikat CGroups dan namespaces bersama-sama dengan cara yang berarti, melengkapi gambar untuk Anda.
Namun, untuk saat ini, artikel ini memeriksa namespace mount dan bagaimana hal itu dapat membantu Anda lebih memahami isolasi yang dibawa container Linux ke sysadmin dan, dengan ekstensi, platform seperti OpenShift dan Kubernetes.
[ Anda mungkin juga menyukai: Berbagi grup tambahan dengan wadah Podman ]
Ruang nama pemasangan
mount namespace tidak berperilaku seperti yang Anda harapkan setelah membuat namespace pengguna baru. Secara default, jika Anda membuat namespace mount baru dengan unshare -m , pandangan Anda tentang sistem sebagian besar akan tetap tidak berubah dan tidak dibatasi. Itu karena setiap kali Anda membuat namespace mount baru, sebuah salinan titik mount dari namespace induk dibuat di namespace mount baru. Itu berarti bahwa tindakan apa pun yang diambil pada file di dalam namespace mount yang dikonfigurasi dengan buruk akan mempengaruhi tuan rumah.
Beberapa langkah penyiapan untuk memasang ruang nama
Jadi apa gunanya mount namespace? Untuk membantu mendemonstrasikannya, saya menggunakan tarball Alpine Linux.
Singkatnya, unduh, hapus tar, dan pindahkan ke direktori baru, memberikan izin direktori tingkat atas untuk pengguna yang tidak memiliki hak istimewa:
[root@localhost ~] export CONTAINER_ROOT_FOLDER=/container_practice
[root@localhost ~] mkdir -p ${CONTAINER_ROOT_FOLDER}/fakeroot
[root@localhost ~] cd ${CONTAINER_ROOT_FOLDER}
[root@localhost ~] wget https://dl-cdn.alpinelinux.org/alpine/v3.13/releases/x86_64/alpine-minirootfs-3.13.1-x86_64.tar.gz
[root@localhost ~] tar xvf alpine-minirootfs-3.13.1-x86_64.tar.gz -C fakeroot
[root@localhost ~] chown container-user. -R ${CONTAINER_ROOT_FOLDER}/fakeroot
fakeroot direktori harus dimiliki oleh pengguna container-user karena setelah Anda membuat ruang nama pengguna baru, root pengguna di namespace baru akan dipetakan ke kontainer-pengguna di luar ruang nama. Ini berarti bahwa proses di dalam namespace baru akan berpikir bahwa ia memiliki kemampuan yang diperlukan untuk memodifikasi file-nya. Namun, izin sistem file host akan mencegah pengguna penampung akun dari mengubah file Alpine dari tarball (yang memiliki root sebagai pemilik).
Jadi apa yang terjadi jika Anda memulai namespace mount baru?
PS1='\u@new-mnt$ ' unshare -Umr Sekarang setelah Anda berada di dalam namespace baru, Anda mungkin tidak berharap untuk melihat titik pemasangan asli dari host. Namun, ini tidak terjadi:
root@new-mnt$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/cs-root 36G 5.2G 31G 15% /
tmpfs 737M 0 737M 0% /sys/fs/cgroup
devtmpfs 720M 0 720M 0% /dev
tmpfs 737M 0 737M 0% /dev/shm
tmpfs 737M 8.6M 728M 2% /run
tmpfs 148M 0 148M 0% /run/user/0
/dev/vda1 976M 197M 713M 22% /boot
root@new-mnt$ ls /
bin container_practice etc lib media opt root sbin sys usr
boot dev home lib64 mnt proc run srv tmp var
Alasannya adalah karena systemd default untuk secara rekursif berbagi titik pemasangan dengan semua ruang nama baru. Jika Anda memasang tmpfs filesystem di suatu tempat, misalnya, /mnt di dalam namespace mount baru, dapatkah host melihatnya?
root@new-mnt$ mount -t tmpfs tmpfs /mnt
root@new-mnt$ findmnt |grep mnt
└─/mnt tmpfs tmpfs rw,relatime,seclabel,uid=1000,gid=1000 Tuan rumah, bagaimanapun, tidak melihat ini:
[root@localhost ~]# findmnt |grep mnt Jadi setidaknya, Anda tahu bahwa namespace mount berfungsi dengan benar. Ini adalah saat yang tepat untuk mengambil jalan memutar kecil untuk membahas penyebaran titik pemasangan. Saya meringkas secara singkat, tetapi jika Anda tertarik untuk memahami lebih lanjut, lihat artikel LWN Michael Kerrisk serta halaman manual untuk mount namespace. Saya biasanya tidak terlalu bergantung pada halaman manual karena saya sering menemukan bahwa mereka tidak mudah dicerna. Namun, dalam kasus ini, mereka penuh dengan contoh dan (kebanyakan) dalam bahasa Inggris yang sederhana.
Teori titik mount
Mount menyebar secara default karena fitur di kernel yang disebut subtree bersama . Ini memungkinkan setiap titik pemasangan memiliki jenis propagasinya sendiri yang terkait dengannya. Metadata ini menentukan apakah mount baru di bawah jalur tertentu disebarkan ke titik mount lainnya. Contoh yang diberikan di halaman manual adalah disk optik. Jika disk optik Anda secara otomatis dipasang di bawah /cdrom , konten hanya akan terlihat di ruang nama lain jika jenis propagasi yang sesuai disetel.
Grup rekan dan status pemasangan
Dokumentasi kernel mengatakan bahwa "peer group didefinisikan sebagai sekelompok vfsmount yang menyebarkan peristiwa satu sama lain." Peristiwa adalah hal-hal seperti memasang jaringan berbagi atau melepas perangkat optik. Mengapa ini penting, Anda tanya? Nah, jika menyangkut ruang nama pemasangan, grup rekan sering menjadi faktor penentu apakah tunggangan terlihat dan dapat berinteraksi dengannya atau tidak. Status pemasangan menentukan apakah anggota dalam kelompok sebaya dapat menerima acara tersebut. Menurut dokumentasi kernel yang sama, ada lima status pemasangan:
- dibagikan - Sebuah mount milik peer group. Setiap perubahan yang terjadi akan menyebar ke seluruh anggota kelompok sebaya.
- budak - Propagasi satu arah. Titik pemasangan master akan menyebarkan peristiwa ke budak, tetapi master tidak akan melihat tindakan apa pun yang dilakukan budak.
- berbagi dan menjadi budak - Menunjukkan bahwa mount point memiliki master, tetapi juga memiliki peer group sendiri. Master tidak akan diberi tahu tentang perubahan pada titik pemasangan, tetapi setiap anggota grup sebaya di hilir akan diberitahu.
- pribadi - Tidak menerima atau meneruskan acara propagasi apa pun.
- tidak dapat diikat - Tidak menerima atau meneruskan acara propagasi apa pun dan tidak bisa menjadi pengikat terpasang.
Penting untuk dicatat bahwa status titik pemasangan adalah per titik pemasangan . Artinya, jika Anda memiliki / dan /boot , misalnya, Anda harus menerapkan status yang diinginkan secara terpisah ke setiap titik pemasangan.
Jika Anda bertanya-tanya tentang container, sebagian besar mesin container menggunakan status pemasangan pribadi saat memasang volume di dalam container. Jangan terlalu khawatir tentang ini untuk saat ini. Saya hanya ingin memberikan beberapa konteks. Jika Anda ingin mencoba beberapa skenario pemasangan tertentu, lihat halaman manual karena contohnya cukup bagus.
Membuat namespace mount kami
Jika Anda menggunakan bahasa pemrograman seperti Go atau C, Anda dapat menggunakan panggilan kernel sistem mentah untuk membuat lingkungan yang sesuai untuk namespace baru Anda. Namun, karena maksud di balik ini adalah untuk membantu Anda memahami cara berinteraksi dengan container yang sudah ada, Anda harus melakukan beberapa tipuan bash untuk membuat namespace mount baru Anda ke status yang diinginkan.
Pertama, buat namespace mount baru sebagai pengguna biasa:
unshare -Urm
Setelah Anda berada di dalam namespace, lihat findmnt dari perangkat mapper, yang berisi sistem file root (untuk singkatnya, saya menghapus sebagian besar opsi mount dari output):
findmnt |grep mapper
/ /dev/mapper/cs-root xfs rw,relatime,[...] Hanya ada satu mount point yang memiliki root device mapper. Ini penting karena salah satu hal yang harus Anda lakukan adalah mengikat perangkat mapper ke direktori Alpine:
export CONTAINER_ROOT_FOLDER=/container_practice
mount --bind ${CONTAINER_ROOT_FOLDER}/fakeroot ${CONTAINER_ROOT_FOLDER}/fakeroot
cd ${CONTAINER_ROOT_FOLDER}/fakeroot
Ini karena Anda menggunakan utilitas bernama pivot_root untuk melakukan chroot -seperti tindakan. pivot_root membutuhkan dua argumen:new_root dan old_root (terkadang disebut sebagai put_old ). pivot_root memindahkan sistem file root dari proses saat ini ke direktori put_old dan membuat new_root sistem file root baru.
PENTING :Catatan tentang chroot . chroot sering dianggap memiliki manfaat keamanan ekstra. Sampai batas tertentu, ini benar, karena dibutuhkan lebih banyak keahlian untuk membebaskan diri darinya. chroot yang dibangun dengan hati-hati bisa sangat aman. Namun, chroot tidak mengubah atau membatasi kemampuan Linux yang saya singgung di artikel namespace sebelumnya. Juga tidak membatasi panggilan sistem ke kernel. Ini berarti bahwa penyerang yang cukup terampil berpotensi lolos dari chroot yang belum dipikirkan dengan baik. Mount dan ruang nama pengguna membantu memecahkan masalah ini.
Jika Anda menggunakan pivot_root tanpa pengikatan mount, perintah merespons dengan:
pivot_root: failed to change root from `.' to `old_root/': Invalid argument
Untuk beralih ke sistem file root Alpine, pertama, buat direktori untuk old_root dan kemudian putar ke sistem file root (Alpine) yang dimaksud. Karena sistem file root Alpine Linux tidak memiliki symlink untuk /bin dan /sbin , Anda harus menambahkannya ke jalur Anda dan akhirnya, melepas old_root :
mkdir old_root
pivot_root . old_root
PATH=/bin:/sbin:$PATH
umount -l /old_root
Anda sekarang memiliki lingkungan yang bagus di mana pengguna dan pasang namespaces bekerja sama untuk menyediakan lapisan isolasi dari host. Anda tidak lagi memiliki akses ke biner di host. Coba keluarkan findmnt perintah yang Anda gunakan sebelumnya:
root@new-mnt$ findmnt
-bash: findmnt: command not found Anda juga dapat melihat sistem file root atau mencoba melihat apa yang terpasang:
root@new-mnt$ ls -l /
total 12
drwxr-xr-x 2 root root 4096 Jan 28 21:51 bin
drwxr-xr-x 2 root root 18 Feb 17 22:53 dev
drwxr-xr-x 15 root root 4096 Jan 28 21:51 etc
drwxr-xr-x 2 root root 6 Jan 28 21:51 home
drwxr-xr-x 7 root root 247 Jan 28 21:51 lib
drwxr-xr-x 5 root root 44 Jan 28 21:51 media
drwxr-xr-x 2 root root 6 Jan 28 21:51 mnt
drwxrwxr-x 2 root root 6 Feb 17 23:09 old_root
drwxr-xr-x 2 root root 6 Jan 28 21:51 opt
drwxr-xr-x 2 root root 6 Jan 28 21:51 proc
drwxr-xr-x 2 root root 6 Feb 17 22:53 put_old
drwx------ 2 root root 27 Feb 17 22:53 root
drwxr-xr-x 2 root root 6 Jan 28 21:51 run
drwxr-xr-x 2 root root 4096 Jan 28 21:51 sbin
drwxr-xr-x 2 root root 6 Jan 28 21:51 srv
drwxr-xr-x 2 root root 6 Jan 28 21:51 sys
drwxrwxrwt 2 root root 6 Feb 19 16:38 tmp
drwxr-xr-x 7 root root 66 Jan 28 21:51 usr
drwxr-xr-x 12 root root 137 Jan 28 21:51 var
root@new-mnt$ mount
mount: no /proc/mounts
Menariknya, tidak ada proc sistem file dipasang secara default. Coba pasang:
root@new-mnt$ mount -t proc proc /proc
mount: permission denied (are you root?)
root@new-mnt$ whoami
root
Karena proc adalah jenis mount khusus yang terkait dengan namespace PID yang tidak dapat Anda mount meskipun Anda berada di mount namespace Anda sendiri. Ini kembali ke pewarisan kemampuan yang saya bahas sebelumnya. Saya akan mengambil diskusi ini di artikel berikutnya ketika saya membahas namespace PID. Namun, sebagai pengingat tentang pewarisan, lihat diagram di bawah ini:
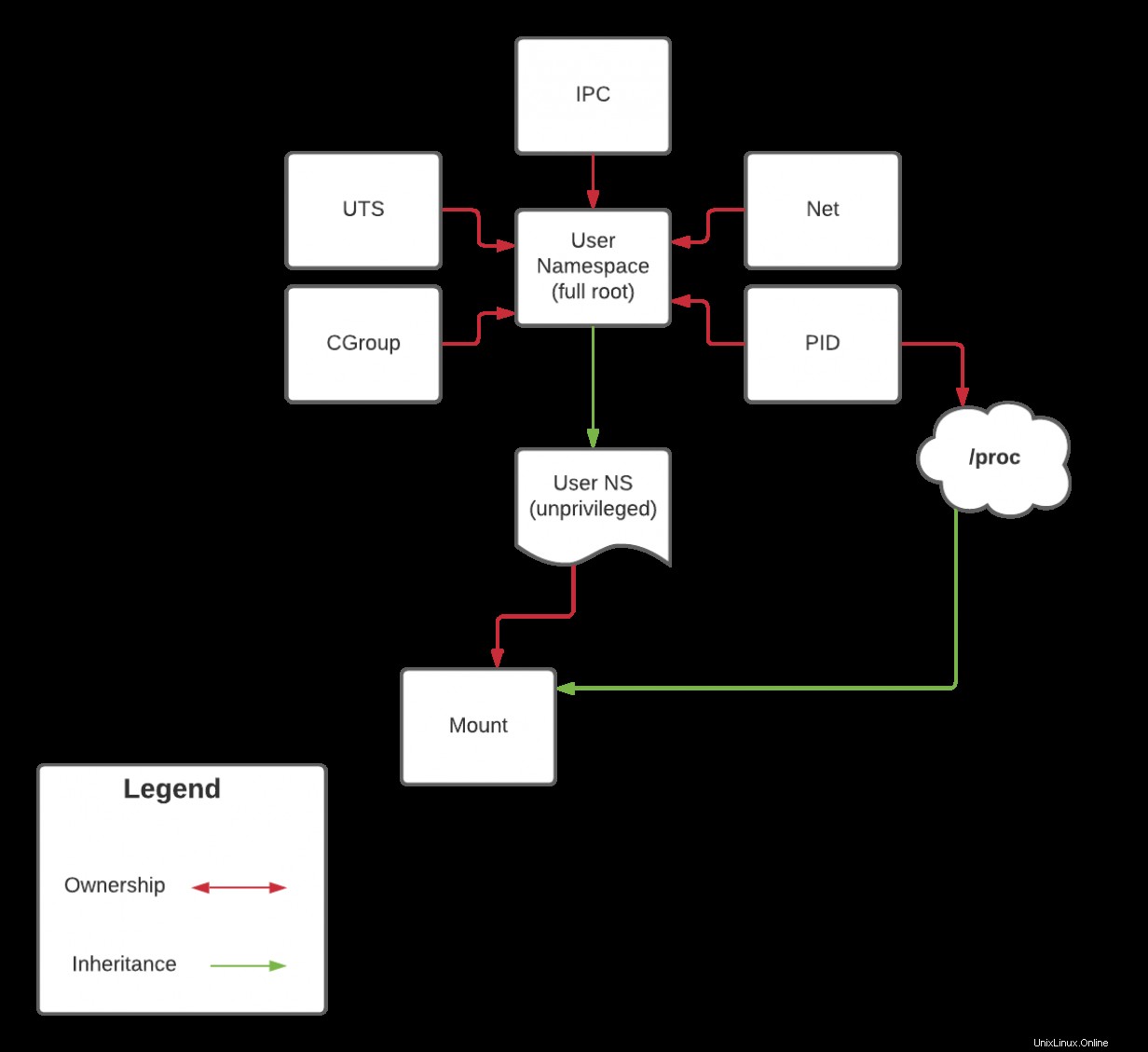
Pada artikel berikutnya, saya akan mengulangi diagram ini, tetapi jika Anda telah mengikuti sejak awal, Anda harus dapat membuat beberapa kesimpulan sebelum itu.
[ Panduan pemilik API:7 praktik terbaik program API yang efektif ]
Menutup
Dalam artikel ini, saya membahas beberapa teori yang lebih dalam seputar mount namespace. Saya membahas kelompok rekan dan bagaimana mereka berhubungan dengan status pemasangan yang diterapkan ke setiap titik pemasangan pada suatu sistem. Untuk bagian langsung, Anda mengunduh sistem file minimal Alpine Linux dan kemudian mempelajari cara menggunakan ruang nama pengguna dan memasang untuk menciptakan lingkungan yang sangat mirip dengan chroot kecuali berpotensi lebih aman.
Untuk saat ini, uji sistem file pemasangan di dalam dan di luar namespace baru Anda. Coba buat titik pemasangan baru yang menggunakan bersama , pribadi , dan budak status gunung. Di artikel berikutnya, saya akan menggunakan namespace PID untuk terus membangun kontainer primitif guna mendapatkan akses ke proc sistem file dan isolasi proses.