Scrapy adalah perangkat lunak sumber terbuka yang digunakan untuk mengekstrak data dari situs web. Kerangka kerja Scrapy dikembangkan dengan Python dan melakukan pekerjaan perayapan dengan cara yang cepat, sederhana, dan dapat diperluas. Kami telah membuat Mesin Virtual (VM) dalam kotak virtual dan Ubuntu 14.04 LTS terinstal di dalamnya.
Instal Scrapy
Scrapy bergantung pada Python, pustaka pengembangan, dan perangkat lunak pip. Versi terbaru Python sudah diinstal sebelumnya di Ubuntu. Jadi kita harus menginstal library pengembang pip dan python sebelum menginstal Scrapy.
Pip adalah pengganti easy_install untuk pengindeks paket python. Ini digunakan untuk instalasi dan pengelolaan paket Python.
Untuk menginstal paket pip, jalankan:
$ sudo apt-get install python-pip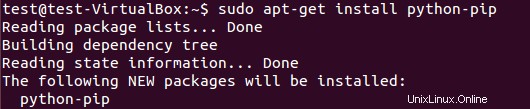
Kita harus menginstal pustaka pengembangan python dengan menggunakan perintah berikut. Jika paket ini tidak diinstal, maka penginstalan kerangka scrapy akan menghasilkan kesalahan tentang file header python.h.
$ sudo apt-get install python-dev
Kerangka kerja tergores dapat diinstal baik dari paket deb atau kode sumber. Namun, kami telah menginstal paket deb menggunakan pip (pengelola paket Python).
$ sudo pip install scrapy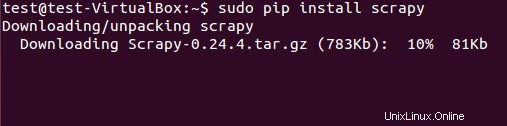
Penginstalan scrapy yang berhasil membutuhkan waktu.

Ekstraksi data menggunakan kerangka Scrapy
(Tutorial Dasar)
Kami akan menggunakan Scrapy untuk mengekstraksi item nama toko (yang menyediakan Kartu) dari situs web fatwallet.com. Pertama-tama, kami membuat proyek scrapy baru “store_name” menggunakan perintah berikut.
$ sudo scrapy startproject store_name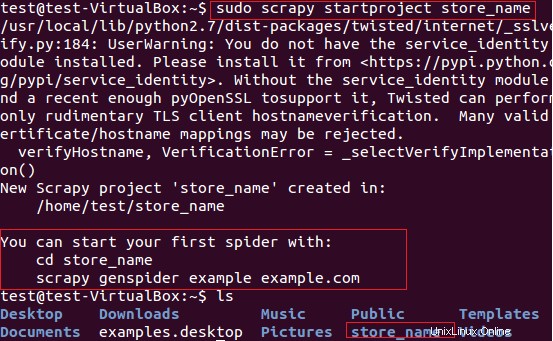
Perintah di atas membuat direktori dengan judul "store_name" di jalur saat ini. Direktori utama proyek ini berisi file/folder yang ditunjukkan pada Gambar 6.
$ sudo ls –lR store_name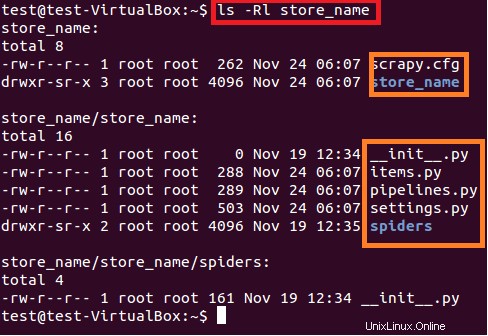
Deskripsi singkat dari setiap file/folder diberikan di bawah ini:
- scrapy.cfg adalah file konfigurasi proyek
- store_name/ adalah direktori lain di dalam direktori utama. Direktori ini berisi kode python proyek.
- store_name/items.py berisi item-item yang akan diekstraksi oleh spider.
- store_name/pipelines.py adalah file pipeline.
- Setelan proyek store_name ada di file store_name/settings.py.
- dan direktori store_name/spiders/, berisi spider untuk perayapan
Karena kami tertarik untuk mengekstrak nama toko Kartu dari situs fatwallet.com, maka kami memperbarui isi file seperti yang ditunjukkan di bawah ini.
import scrapy
class StoreNameItem(scrapy.Item):
name = scrapy.Field() # extract the names of Cards storeSetelah ini, kita harus menulis spider baru di bawah direktori store_name/spiders/ proyek. Spider adalah kelas python yang terdiri dari atribut wajib berikut:
Nama laba-laba (nama )
- Memulai url laba-laba untuk perayapan (start_urls)
Dan metode parse yang terdiri dari regex untuk ekstraksi item yang diinginkan dari respons halaman. Metode penguraian adalah bagian penting dari laba-laba.
Kami membuat spider "store_name.py" di bawah direktori store_name/spiders/ dan menambahkan kode python berikut untuk ekstraksi nama toko dari situs fatwallet.com. Output dari spider ditulis dalam file (StoreName.txt ).
from scrapy.selector import Selector
from scrapy.spider import BaseSpider
from scrapy.http import Request
from scrapy.http import FormRequest
import re
class StoreNameItem(BaseSpider):
name = "storename"
allowed_domains = ["fatwallet.com"]
start_urls = ["http://fatwallet.com/cash-back-shopping/"]
def parse(self,response):
output = open('StoreName.txt','w')
resp = Selector(response)
tags = resp.xpath('//tr[@class="storeListRow"]|\
//tr[@class="storeListRow even"]|\
//tr[@class="storeListRow even last"]|\
//tr[@class="storeListRow last"]').extract()
for i in tags:
i = i.encode('utf-8', 'ignore').strip()
store_name = ''
if re.search(r"class=\"storeListStoreName\">.*?<",i,re.I|re.S):
store_name = re.search(r"class=\"storeListStoreName\">.*?<",i,re.I|re.S).group()
store_name = re.search(r">.*?<",store_name,re.I|re.S).group()
store_name = re.sub(r'>',"",re.sub(r'<',"",store_name,re.I))
store_name = re.sub(r'&',"&",re.sub(r'&',"&",store_name,re.I))
#print store_name
output.write(store_name+""+"\n")
CATATAN:Tujuan dari tutorial ini hanya untuk memahami Kerangka Kerja Scrapy