Pendahuluan
Apache Spark adalah kerangka kerja yang digunakan dalam lingkungan komputasi cluster untuk menganalisis data besar . Platform ini menjadi sangat populer karena kemudahan penggunaannya dan kecepatan pemrosesan data yang ditingkatkan dibandingkan Hadoop.
Apache Spark mampu mendistribusikan beban kerja di sekelompok komputer dalam sebuah cluster untuk memproses kumpulan data yang besar secara lebih efektif. Mesin sumber terbuka . ini mendukung beragam bahasa pemrograman. Ini termasuk Java, Scala, Python, dan R.
Dalam tutorial ini, Anda akan mempelajari cara menginstal Spark di mesin Ubuntu . Panduan ini akan menunjukkan kepada Anda cara memulai server master dan slave dan cara memuat shell Scala dan Python. Ini juga menyediakan perintah Spark yang paling penting.

Prasyarat
- Sistem Ubuntu.
- Akses ke terminal atau baris perintah.
- Pengguna dengan sudo atau root izin.
Instal Paket Diperlukan untuk Spark
Sebelum mengunduh dan mengatur Spark, Anda perlu menginstal dependensi yang diperlukan. Langkah ini termasuk menginstal paket-paket berikut:
- JDK
- Skala
- Git
Buka jendela terminal dan jalankan perintah berikut untuk menginstal ketiga paket sekaligus:
sudo apt install default-jdk scala git -yAnda akan melihat paket mana yang akan diinstal.
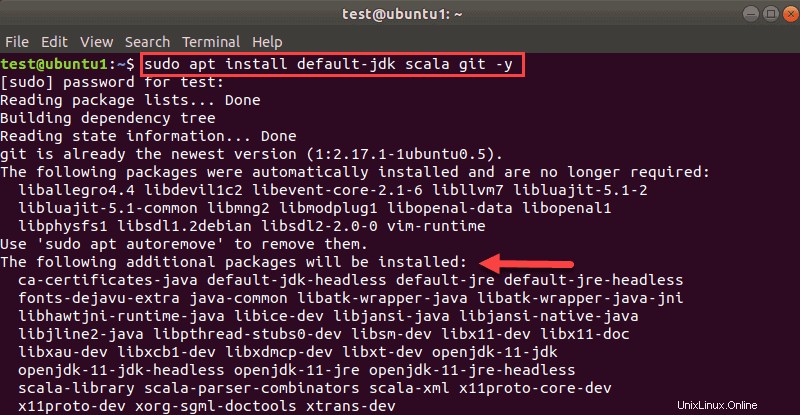
Setelah proses selesai, verifikasi dependensi yang diinstal dengan menjalankan perintah berikut:
java -version; javac -version; scala -version; git --version
Output akan mencetak versi jika instalasi berhasil diselesaikan untuk semua paket.
Unduh dan Siapkan Spark di Ubuntu
Sekarang, Anda perlu mengunduh versi Spark yang Anda inginkan membentuk situs web mereka. Kami akan menggunakan Spark 3.0.1 dengan Hadoop 2.7 karena ini adalah versi terbaru pada saat artikel ini ditulis.
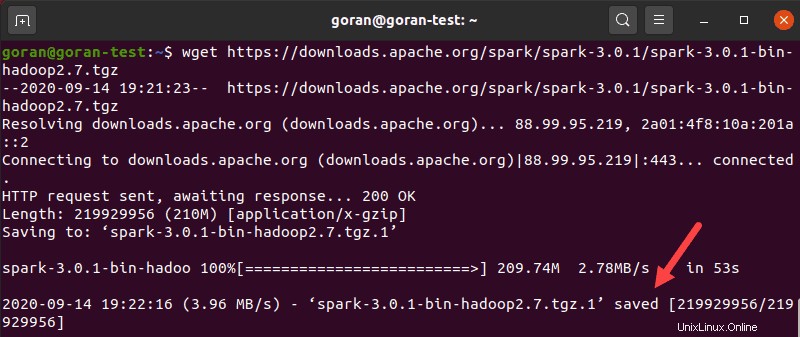
Gunakan wget perintah dan tautan langsung untuk mengunduh arsip Spark:
wget https://downloads.apache.org/spark/spark-3.0.1/spark-3.0.1-bin-hadoop2.7.tgzSaat unduhan selesai, Anda akan melihat file disimpan pesan.
Sekarang, ekstrak arsip yang disimpan menggunakan tar:
tar xvf spark-*Biarkan proses selesai. Outputnya menunjukkan file yang sedang dibongkar dari arsip.
Terakhir, pindahkan direktori yang belum dibongkar spark-3.0.1-bin-hadoop2.7 ke opt/spark direktori.
Gunakan mv perintah untuk melakukannya:
sudo mv spark-3.0.1-bin-hadoop2.7 /opt/sparkTerminal tidak mengembalikan respons jika berhasil memindahkan direktori. Jika Anda salah mengetik nama, Anda akan mendapatkan pesan yang mirip dengan:
mv: cannot stat 'spark-3.0.1-bin-hadoop2.7': No such file or directory.Konfigurasikan Lingkungan Spark
Sebelum memulai server master, Anda perlu mengonfigurasi variabel lingkungan. Ada beberapa jalur beranda Spark yang perlu Anda tambahkan ke profil pengguna.
Gunakan echo perintah untuk menambahkan tiga baris ini ke .profile :
echo "export SPARK_HOME=/opt/spark" >> ~/.profile
echo "export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin" >> ~/.profile
echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profileAnda juga dapat menambahkan jalur ekspor dengan mengedit .profil file di editor pilihan Anda, seperti nano atau vim.
Misalnya, untuk menggunakan nano, masukkan:
nano .profileSaat profil dimuat, gulir ke bagian bawah file.
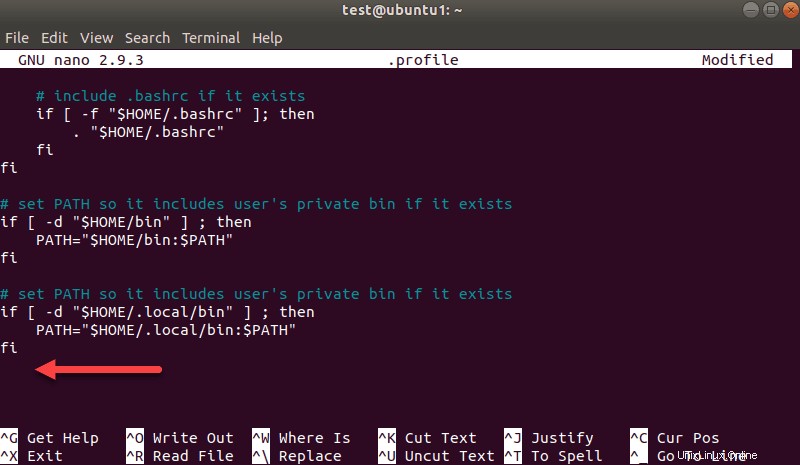
Kemudian, tambahkan tiga baris ini:
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export PYSPARK_PYTHON=/usr/bin/python3Keluar dan simpan perubahan saat diminta.
Setelah Anda selesai menambahkan jalur, muat .profile file di baris perintah dengan mengetik:
source ~/.profileMulai Server Master Spark Mandiri
Sekarang setelah Anda selesai mengonfigurasi lingkungan Anda untuk Spark, Anda dapat memulai server master.
Di terminal, ketik:
start-master.shUntuk melihat antarmuka pengguna Spark Web, buka browser web dan masukkan alamat IP localhost pada port 8080.
http://127.0.0.1:8080/Laman menunjukkan URL Spark . Anda , informasi status untuk pekerja, pemanfaatan sumber daya perangkat keras, dll.
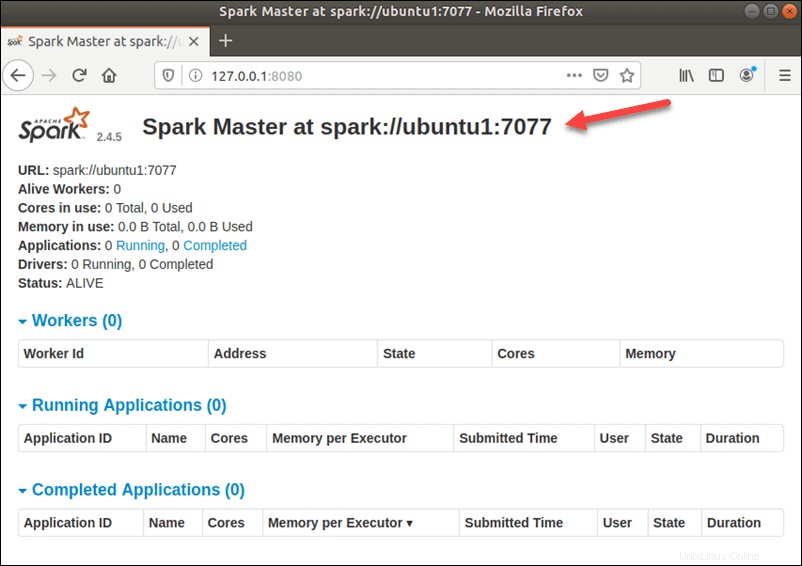
URL untuk Spark Master adalah nama perangkat Anda pada port 8080. Dalam kasus kami, ini adalah ubuntu1:8080 . Jadi, ada tiga cara yang mungkin untuk memuat UI Web Spark Master:
- 127.0.0.1:8080
- localhost:8080
- namaperangkat :8080
Mulai Spark Slave Server (Mulai Proses Pekerja)
Dalam konfigurasi server tunggal dan mandiri ini, kita akan memulai satu server budak bersama dengan server master.
Untuk melakukannya, jalankan perintah berikut dalam format ini:
start-slave.sh spark://master:port
master dalam perintah dapat berupa IP atau nama host.
Dalam kasus kami ini adalah ubuntu1 :
start-slave.sh spark://ubuntu1:7077
Sekarang pekerja sudah aktif dan berjalan, jika Anda memuat ulang UI Web Spark Master, Anda akan melihatnya di daftar:
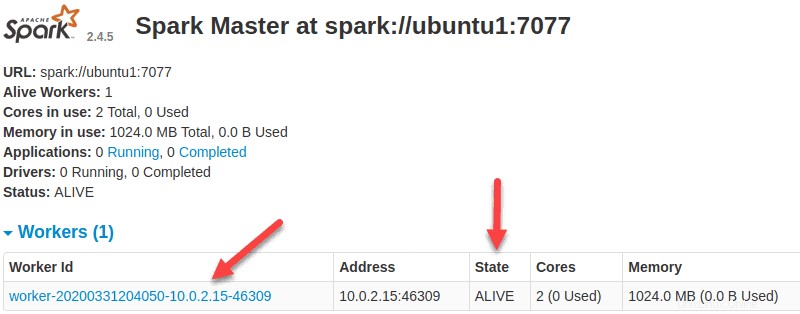
Tentukan Alokasi Sumber Daya untuk Pekerja
Pengaturan default saat memulai pekerja di mesin adalah menggunakan semua inti CPU yang tersedia. Anda dapat menentukan jumlah inti dengan meneruskan -c tandai ke start-slave perintah.
Misalnya, untuk memulai pekerja dan menetapkan hanya satu inti CPU untuk itu, masukkan perintah ini:
start-slave.sh -c 1 spark://ubuntu1:7077Muat ulang UI Web Spark Master untuk mengonfirmasi konfigurasi pekerja.

Demikian pula, Anda dapat menetapkan jumlah memori tertentu saat memulai pekerja. Pengaturan default adalah menggunakan berapa pun jumlah RAM yang dimiliki mesin Anda, minus 1 GB.
Untuk memulai pekerja dan menetapkan jumlah memori tertentu, tambahkan -m pilihan dan nomor. Untuk gigabyte, gunakan G dan untuk megabita, gunakan M .
Misalnya, untuk memulai pekerja dengan memori 512MB, masukkan perintah ini:
start-slave.sh -m 512M spark://ubuntu1:7077Muat ulang UI Web Spark Master untuk melihat status pekerja dan mengonfirmasi konfigurasi.

Uji Spark Shell
Setelah Anda menyelesaikan konfigurasi dan memulai server master dan slave, uji apakah shell Spark berfungsi.
Muat shell dengan memasukkan:
spark-shellAnda harus mendapatkan layar dengan pemberitahuan dan informasi Spark. Scala adalah antarmuka default, sehingga shell dimuat saat Anda menjalankan spark-shell .
Akhir dari output terlihat seperti ini untuk versi yang kami gunakan saat menulis panduan ini:
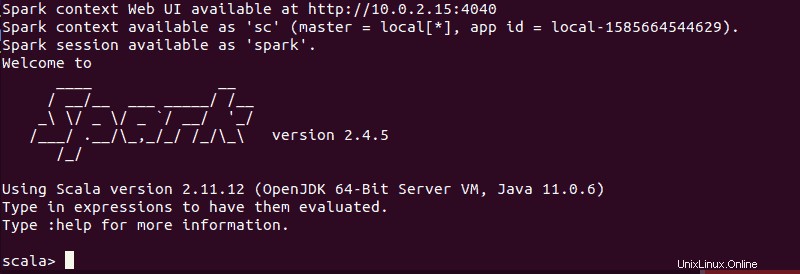
Ketik :q dan tekan Enter untuk keluar dari Scala.
Uji Python di Spark
Jika Anda tidak ingin menggunakan antarmuka Scala default, Anda dapat beralih ke Python.
Pastikan Anda keluar dari Scala dan kemudian jalankan perintah ini:
pysparkOutput yang dihasilkan terlihat mirip dengan yang sebelumnya. Di bagian bawah, Anda akan melihat versi Python.
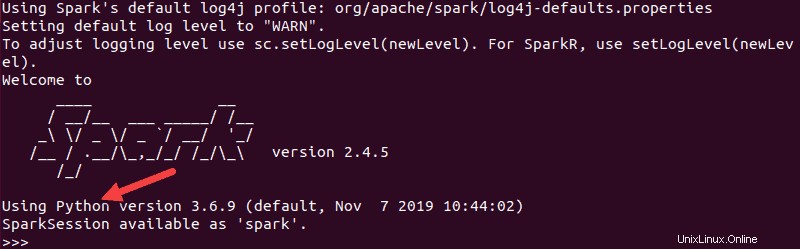
Untuk keluar dari shell ini, ketik quit() dan tekan Enter .
Perintah Dasar untuk Memulai dan Menghentikan Server Master dan Pekerja
Di bawah ini adalah perintah dasar untuk memulai dan menghentikan server master dan pekerja Apache Spark. Karena penyiapan ini hanya untuk satu mesin, skrip yang Anda jalankan default ke localhost.
Untuk memulai seorang ahli server misalnya pada mesin saat ini, jalankan perintah yang kita gunakan sebelumnya dalam panduan:
start-master.shUntuk menghentikan master instance dimulai dengan menjalankan skrip di atas, jalankan:
stop-master.shUntuk menghentikan pekerja yang sedang berlari proses, masukkan perintah ini:
stop-slave.shLaman Spark Master, dalam hal ini, menunjukkan status pekerja sebagai MATI.

Anda dapat memulai master dan server instance dengan menggunakan perintah start-all:
start-all.shDemikian pula, Anda dapat menghentikan semua instance dengan menggunakan perintah berikut:
stop-all.sh