Apache Spark adalah kerangka kerja komputasi sumber terbuka untuk data analitik skala tinggi dan pemrosesan pembelajaran mesin. Ini mendukung berbagai bahasa pilihan seperti scala, R, Python, dan Java. Ini menyediakan alat tingkat tinggi untuk streaming percikan, GraphX untuk pemrosesan grafik, SQL, MLLib.
Pada artikel ini, Anda akan mengetahui cara menginstal dan mengkonfigurasi Apache Spark di ubuntu. Untuk mendemonstrasikan aliran dalam artikel ini saya telah menggunakan sistem versi Ubuntu 20.04 LTS. Sebelum menginstal Apache Spark, Anda harus menginstal Scala serta scala di sistem Anda.
Menginstal Scala
Jika Anda belum menginstal Java dan Scala, Anda dapat mengikuti proses berikut untuk menginstalnya.
Untuk Java, kami akan menginstal open JDK 8 atau Anda dapat menginstal versi pilihan Anda.
$ sudo apt update
$ sudo apt install openjdk-8-jdk
Jika Anda perlu memverifikasi instalasi java, Anda dapat menjalankan perintah berikut.
$ java -version

Adapun Scala, scala adalah bahasa pemrograman berorientasi objek dan fungsional yang menggabungkannya menjadi satu ringkas. Scala kompatibel dengan runtime javascript serta JVM yang memberi Anda akses mudah ke ekosistem perpustakaan besar yang membantu dalam membangun sistem kinerja tinggi. Jalankan perintah apt berikut untuk menginstal scala.
$ sudo apt update
$ sudo apt install scala
Sekarang, periksa versi untuk memverifikasi penginstalan.
$ scala -version

Menginstal Apache Spark
Tidak ada repositori apt resmi untuk menginstal Apache-spark tetapi Anda dapat mengkompilasi biner terlebih dahulu dari situs resmi. Gunakan perintah dan tautan wget berikut untuk mengunduh file biner.
$ wget https://downloads.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
Sekarang, ekstrak file biner yang diunduh menggunakan perintah tar berikut.
$ tar -xzvf spark-3.1.2-bin-hadoop3.2.tgz
Terakhir, pindahkan file spark yang telah diekstrak ke direktori /opt.
$ sudo mv spark-3.1.2-bin-hadoop3.2 /opt/spark
Menyiapkan Variabel Lingkungan
Variabel jalur Anda untuk percikan di .profil Anda dalam file yang diperlukan untuk mengatur agar perintah bekerja tanpa jalur yang lengkap, Anda dapat melakukannya dengan menggunakan perintah gema atau melakukannya secara manual menggunakan editor teks yang lebih disukai. Untuk cara yang lebih mudah, jalankan perintah echo berikut.
$ echo "export SPARK_HOME=/opt/spark" >> ~/.profile
$ echo "export PATH=$PATH:/opt/spark/bin:/opt/spark/sbin" >> ~/.profile
$ echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profile
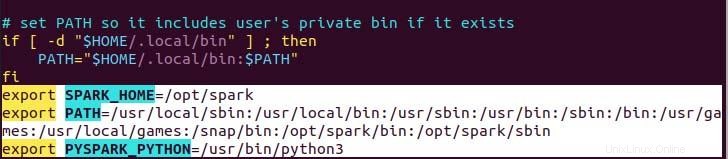
Seperti yang Anda lihat, variabel path ditambahkan di bagian bawah file .profile menggunakan echo dengan operasi>>.
Sekarang, jalankan perintah berikut untuk menerapkan perubahan variabel lingkungan baru.
$ source ~/.profile
Menerapkan Apache Spark
Sekarang, kami telah menyiapkan semua yang kami dapat menjalankan layanan master serta layanan pekerja menggunakan perintah berikut.
$ start-master.sh
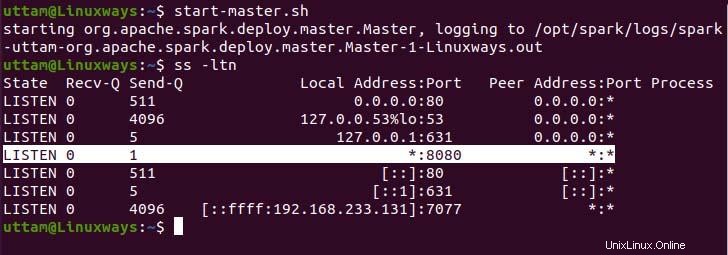
Seperti yang Anda lihat, layanan spark master kami berjalan pada port 8080. Jika Anda menelusuri localhost pada port 8080 yang merupakan port default spark. Anda mungkin menemukan jenis antarmuka pengguna berikut saat menelusuri URL. Anda mungkin tidak menemukan prosesor pekerja yang berjalan hanya dengan memulai layanan master. Saat Anda memulai layanan pekerja, Anda akan menemukan simpul baru yang terdaftar seperti pada contoh berikut.
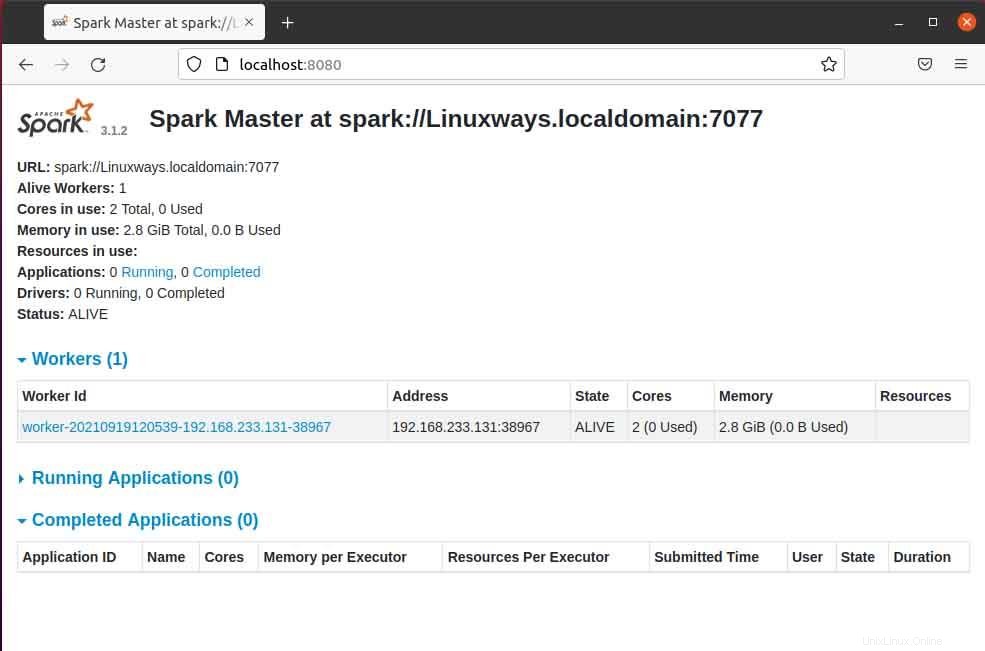
Saat Anda membuka halaman master di browser maka Anda dapat melihat spark master spark://HOST:PORT URL yang digunakan untuk menghubungkan layanan pekerja melalui host ini. Untuk host saya saat ini, url master percikan saya adalah spark://Linuxways.localdomain:7077 jadi Anda perlu menjalankan perintah dengan cara berikut untuk memulai proses pekerja.
$ start-workers.sh <spark-master-url>
Untuk menjalankan perintah berikut untuk menjalankan layanan pekerja.
$ start-workers.sh spark://Linuxways.localdomain:7077

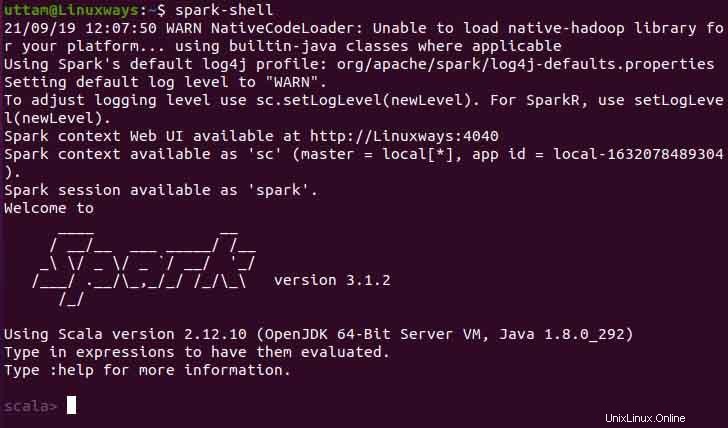
Anda juga dapat menggunakan spark-shell dengan menjalankan perintah berikut.
$ spark-shell
Kesimpulan
Saya harap dari artikel ini Anda mempelajari cara menginstal dan mengkonfigurasi apache spark di ubuntu. Dalam artikel ini, saya berusaha membuat prosesnya sedapat mungkin dimengerti.