Sarang adalah Data Warehouse model di Hadoop Eko-Sistem. Itu dapat berfungsi sebagai alat ETL di atas Hadoop . Mengaktifkan Ketersediaan Tinggi (HA) di Hive tidak sama seperti yang kami lakukan di Layanan Master seperti Namenode dan Resource Manager.
Kegagalan otomatis tidak akan terjadi di Hive (Hiveserver2 ). Jika ada Hiveserver2 (HS2 ) gagal, menjalankan tugas pada HS2 yang gagal itu akan gagal. Kami perlu mengirim ulang tugas agar tugas dapat berjalan di HiveServer2 lain . Jadi, aktifkan HA di HS2 tidak lain adalah, meningkatkan jumlah HS2 komponen di Cluster .
Dalam artikel ini, kita akan melihat langkah-langkah untuk menginstal dan mengaktifkan Ketersediaan Tinggi dari Sarang .
Persyaratan
- Praktik Terbaik untuk Menerapkan Server Hadoop di CentOS/RHEL 7 – Bagian 1
- Menyiapkan Prasyarat Hadoop dan Pengerasan Keamanan – Bagian 2
- Cara Menginstal dan Mengonfigurasi Cloudera Manager di CentOS/RHEL 7 – Bagian 3
- Cara Menginstal CDH dan Mengonfigurasi Penempatan Layanan di CentOS/RHEL 7 – Bagian 4
- Cara Mengatur Ketersediaan Tinggi untuk Namenode – Bagian 5
- Cara Menyiapkan Ketersediaan Tinggi untuk Manajer Sumber Daya – Bagian 6
Mari kita mulai…
Instalasi dan Konfigurasi Hive
1. Masuk ke Manajer Cloudera di URL di bawah dan navigasikan ke Cloudera Manager –> Tambahkan Layanan .
http://13.233.129.39:7180/cmf/home
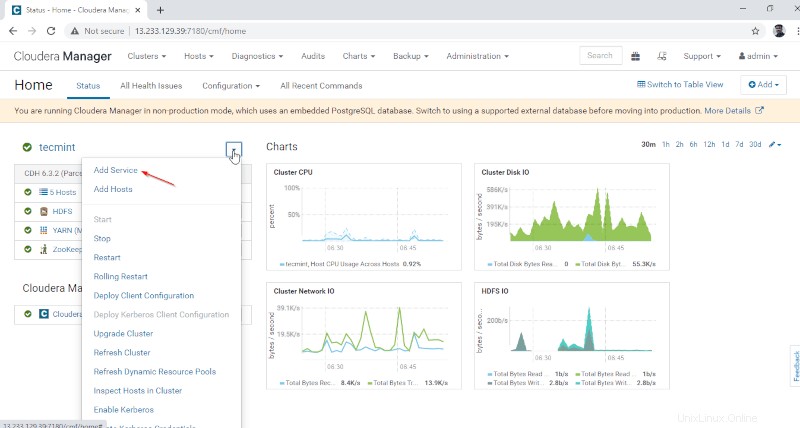
2. Pilih layanan ‘Sarang ‘.
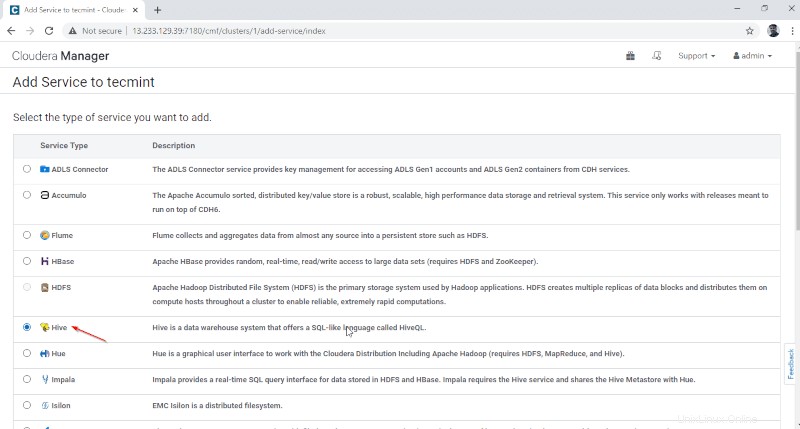
3. Tetapkan layanan pada node.
- Gerbang – Ini adalah layanan klien tempat pengguna dapat mengakses Hive. Biasanya, layanan ini akan ditempatkan di Edge node yang didedikasikan untuk pengguna.
- Hive Metastore – Ini adalah repositori pusat untuk menyimpan Hive Metadata.
- Server WebHCat – Ini adalah API Web untuk HCatalog dan Layanan Hadoop lainnya.
- Hiveserver2 – Ini adalah antarmuka klien untuk eksekusi kueri di Hive.
Setelah memilih server, klik ‘Lanjutkan ' untuk melanjutkan.
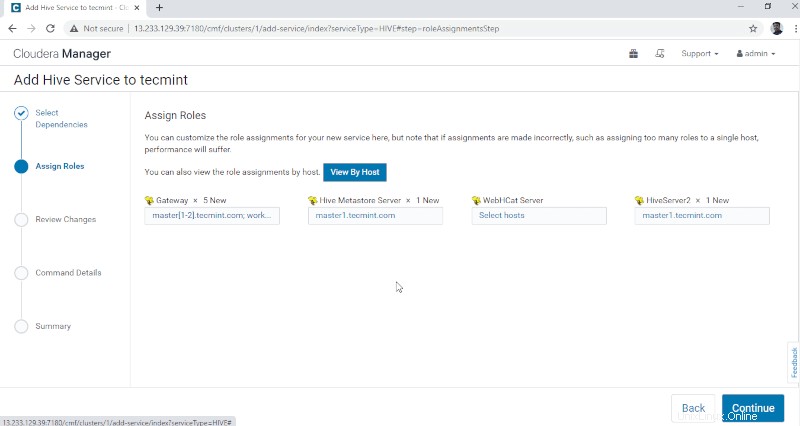
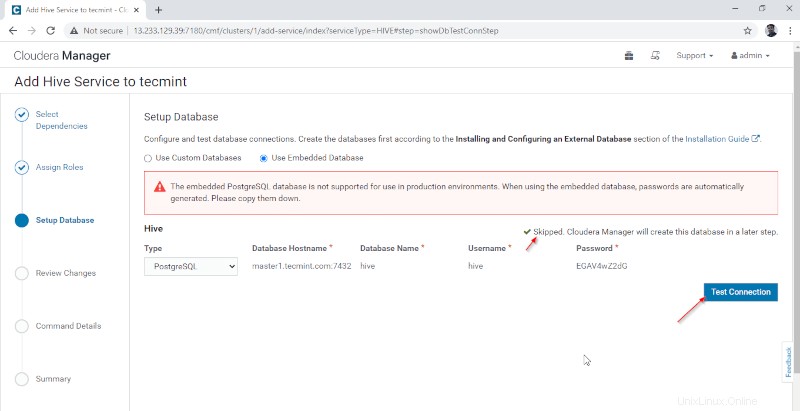
4. Hive Metastore membutuhkan Database yang mendasari untuk menyimpan Metadata. Di sini kita menggunakan PostgreSQL default database yang terintegrasi dengan CDH .
Detail database yang disebutkan di bawah ini akan dimasukkan secara otomatis, ‘Uji Koneksi ' akan dilewati karena database yang disebutkan akan dibuat dengan cepat. Secara real-time, kita perlu membuat Database di database eksternal dan menguji koneksi untuk melangkah lebih jauh. Setelah selesai, silakan klik ‘Lanjutkan '.
5. Konfigurasikan Hive Warehouse direktori, /user/hive/warehouse adalah jalur direktori default untuk menyimpan tabel Hive. Klik tombol ‘Lanjutkan '.
6. Instalasi Hive dimulai.
7. Setelah penginstalan selesai, Anda bisa mendapatkan 'Selesai ' status. Klik ‘Lanjutkan ' untuk melangkah lebih jauh.
8. Instalasi dan Konfigurasi Hive berhasil diselesaikan. Klik ‘Selesai ' untuk menyelesaikan prosedur instalasi.
9. Anda dapat melihat Sarang layanan ditambahkan di Cluster melalui Dasbor Cloudera Manager .
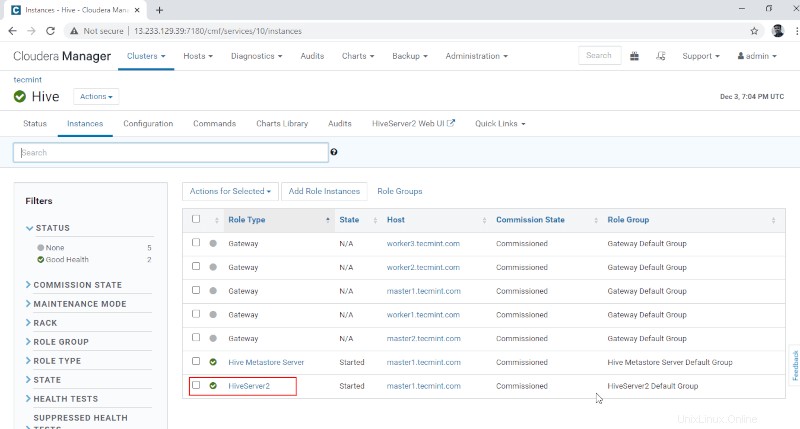
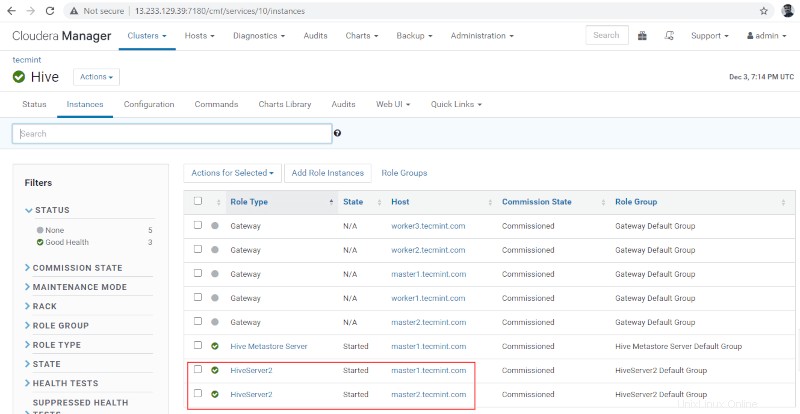
10. Anda dapat melihat Hiveserver2 di Instance dari Sarang . Kami telah menambahkan Hiveserver2 di master1 .
Pengelola Cloudera –> Sarang –> Instance –> Hiveserver2 .
Mengaktifkan Ketersediaan Tinggi di Hive
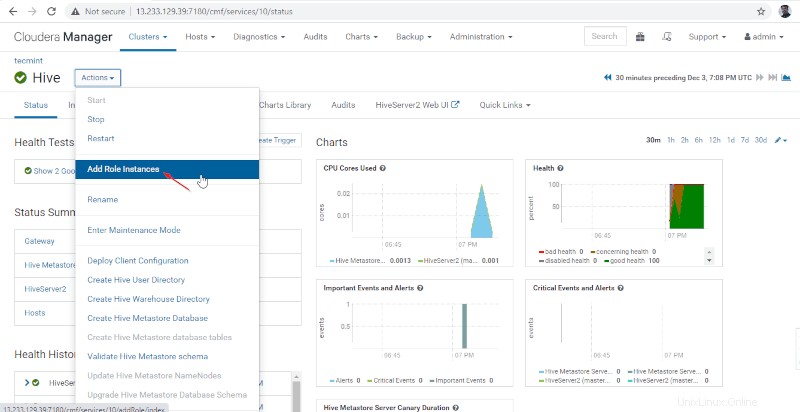
11. Selanjutnya tambahkan peran Hive dengan membuka Cloudera Manager –> Sarang –> Tindakan –> Tambahkan Peran Contoh.
12. Pilih server tempat Anda ingin menempatkan Hiveserver2 tambahan . Anda dapat menambahkan lebih dari dua, tidak ada batasan. Di sini kami menambahkan satu tambahan Hiveserver2 di master2 .
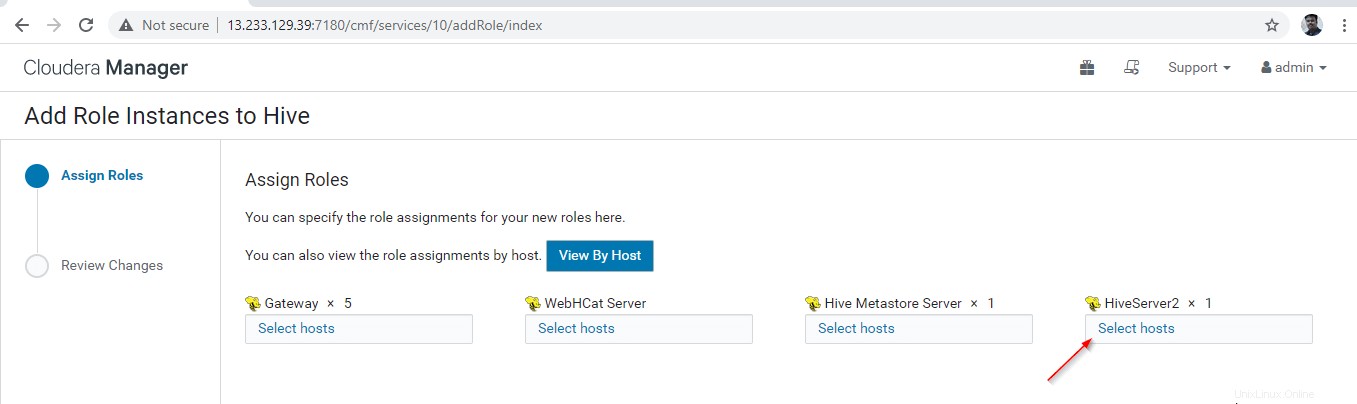
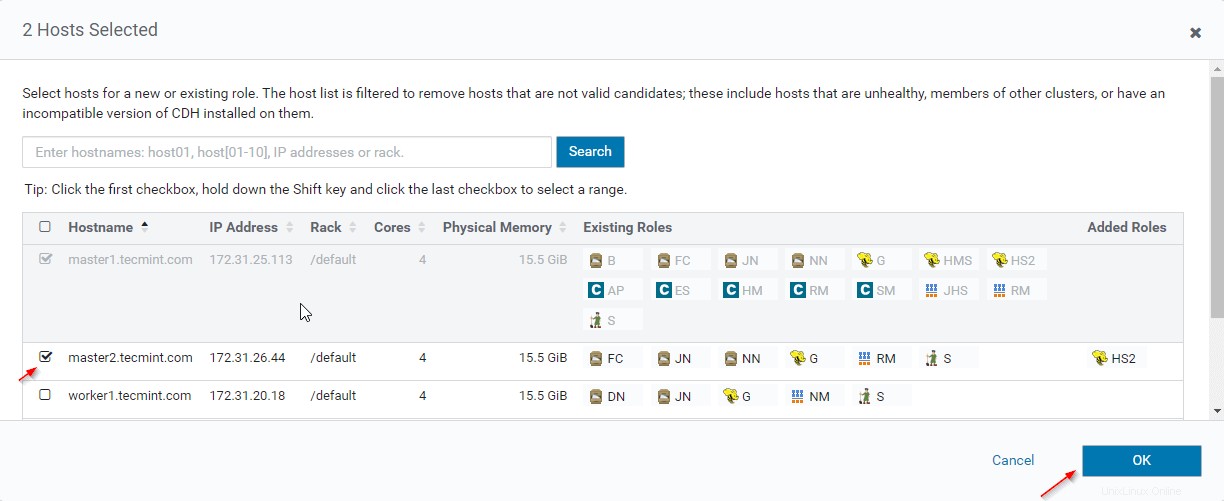
13. Setelah memilih server, klik ‘Lanjutkan '.
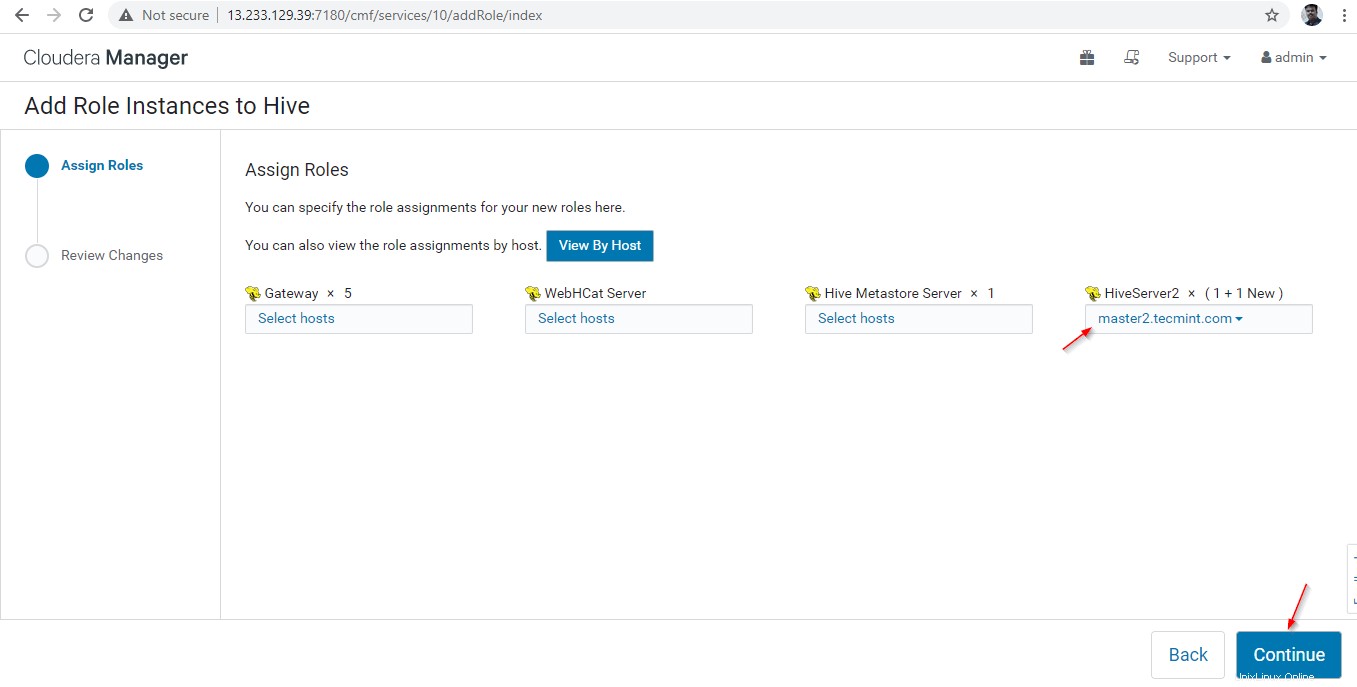
14. Sebuah Hiverserver2 akan ditambahkan ke Contoh Sarang , Anda harus memulainya dengan membuka Cloudera Manager –> Sarang –> Instance –> (Pilih Hiveserver2 ditambahkan baru) -> Tindakan untuk Terpilih –> Mulai .
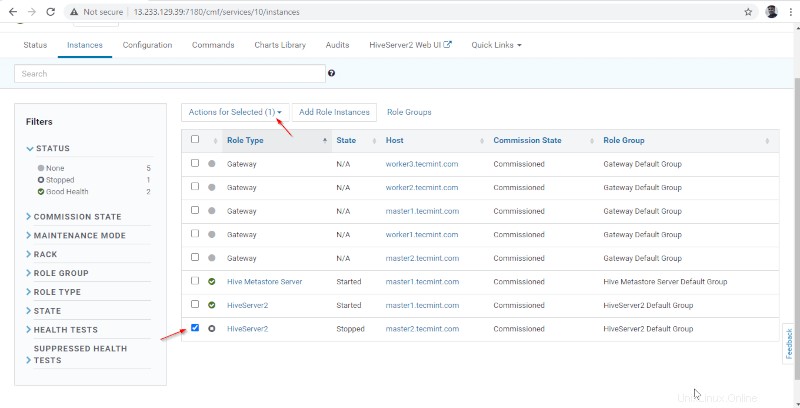
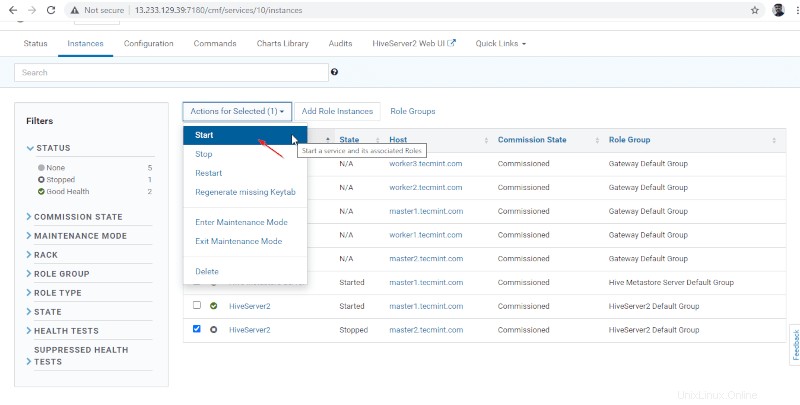
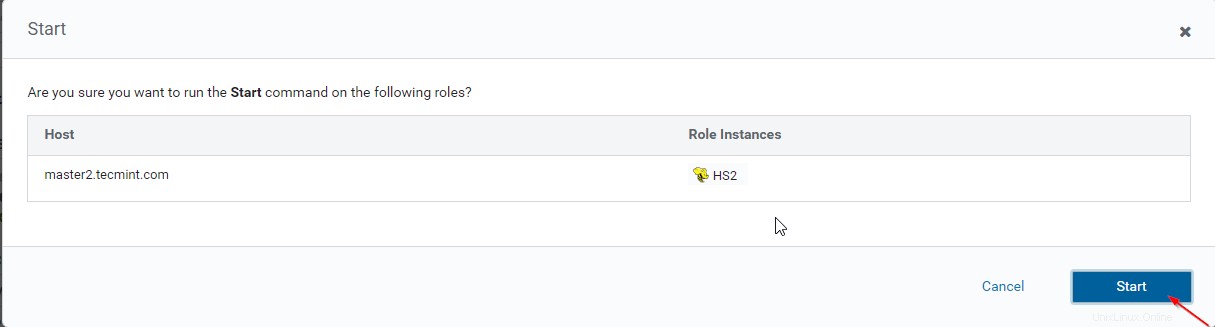
15. Sekali Hiveserver2 dimulai pada master2 , Anda akan mendapatkan status 'Selesai '. Klik Tutup .
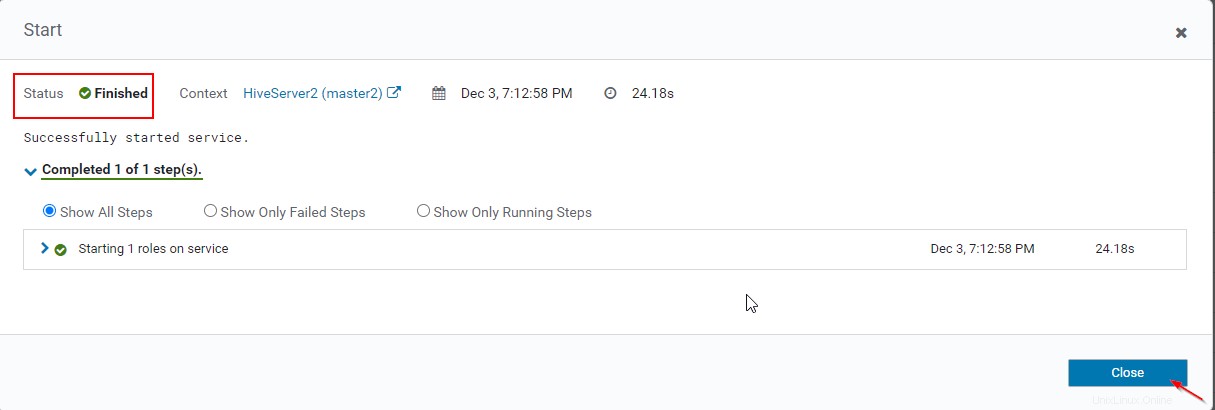
16. Anda dapat melihat, baik Hiveserver2s sedang berjalan.
Memverifikasi Ketersediaan Hive
Kami dapat menghubungkan Hiveserver2 melalui langsung yang merupakan klien tipis dan baris perintah. Ini menggunakan driver JDBC untuk membuat koneksi.
17. Masuk ke Server tempat Hive Gateway sedang berjalan.
[[email protected] ~]$ beeline

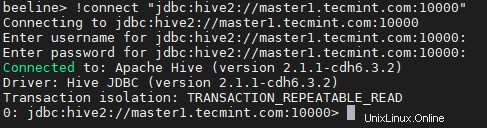
18. Masukkan JDBC string koneksi untuk menghubungkan Hiveserver2 . Dalam hubungan ini, string kami menyebutkan Hiverserver2 (master2 ) dengan nomor port default 10000 . String koneksi ini hanya akan terhubung ke Hiveserver2 yang berjalan di master2 .
beeline> !connect "jdbc:hive2://master1.tecmint.com:10000"
19. Jalankan kueri sampel.
0: jdbc:hive2://master1.tecmint.com:10000> show databases;
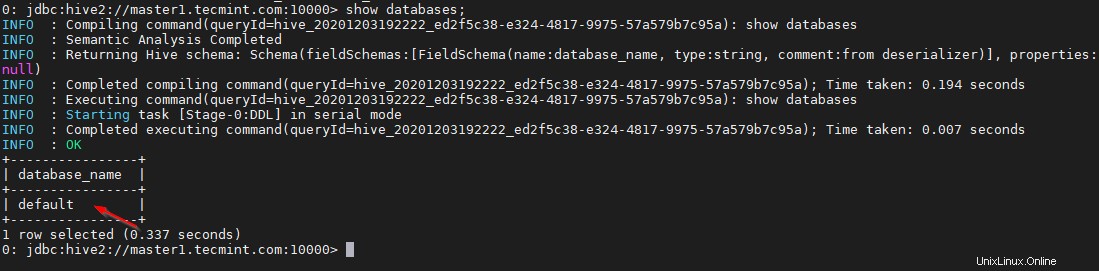
Ini adalah database default yang disertakan.
20. Gunakan perintah di bawah ini untuk mengakhiri sesi Hive.
0: jdbc:hive2://master1.tecmint.com:10000> !quit

21. Anda dapat menggunakan cara yang sama untuk menghubungkan Hiveserver2 berjalan di master2 .
beeline> !connect "jdbc:hive2://master2.tecmint.com:10000"
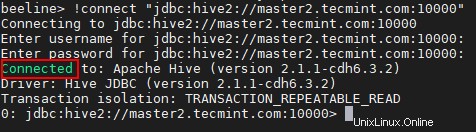
23. Kami dapat menghubungkan Hiveserver2 di Penemuan Penjaga Kebun Binatang mode. Dalam metode ini, kita tidak perlu menyebutkan Hiveserver2 di string koneksi sebagai gantinya kami menggunakan Zookeeper untuk menemukan Hiveserver2 . yang tersedia .
Di sini kita dapat menggunakan penyeimbang beban pihak ketiga untuk menyeimbangkan beban di antara Hiverserver2 yang tersedia . Konfigurasi di bawah ini diperlukan untuk mengaktifkan Mode Penemuan Penjaga Kebun Binatang dengan membuka Pengelola Cloudera –> Sarang –> Konfigurasi .
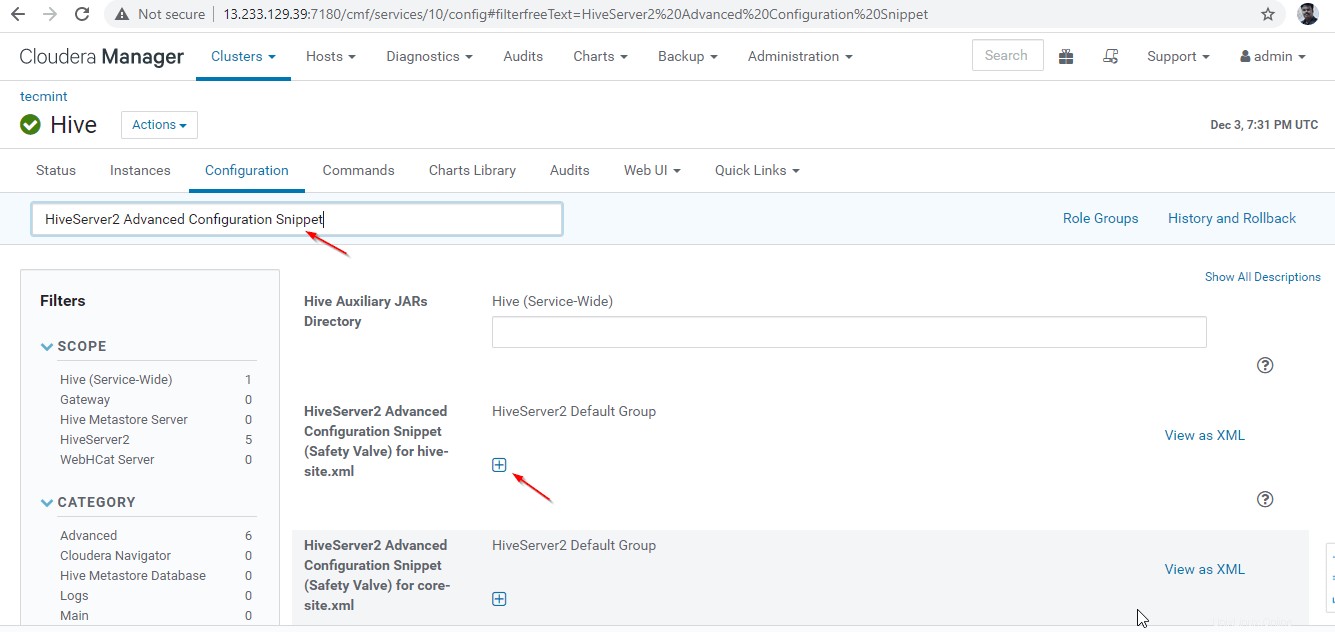
24. Selanjutnya, cari properti “HiveServer2 Advanced Configuration Snippet ” dan klik + simbol untuk menambahkan properti di bawah ini.
Name : hive.server2.support.dynamic.service.discovery Value : true Description : <any description>
25. Setelah memasuki properti, klik ‘Simpan Perubahan '.
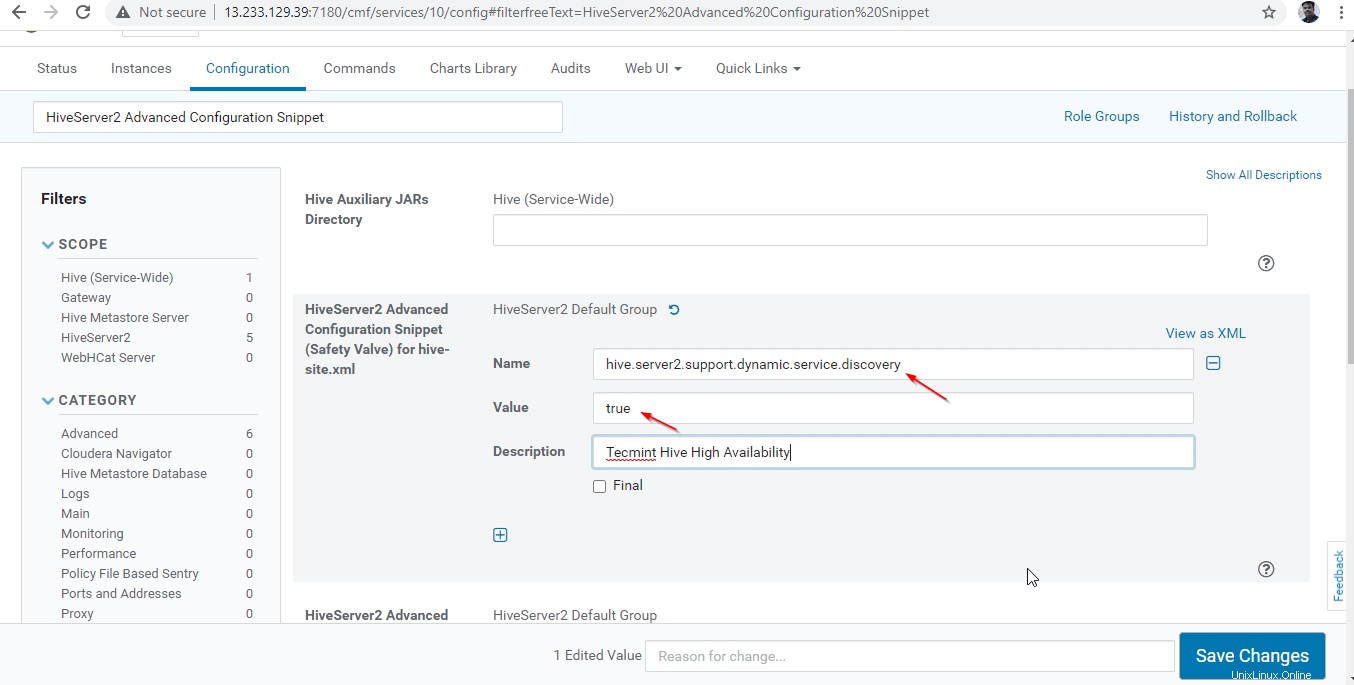
26. Saat kami membuat perubahan pada Konfigurasi, perlu memulai ulang layanan yang terpengaruh dengan mengklik Simbol Warna Oranye untuk memulai kembali layanan.
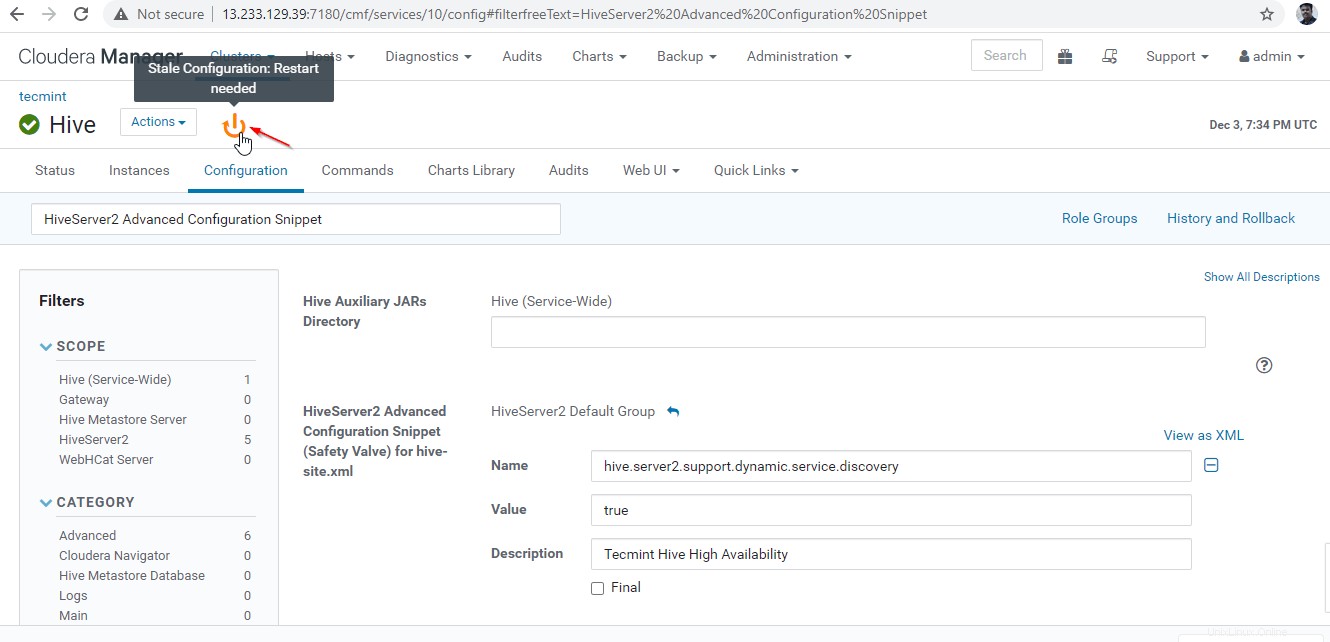
27. Klik ‘Mulai Ulang Lama ' layanan.
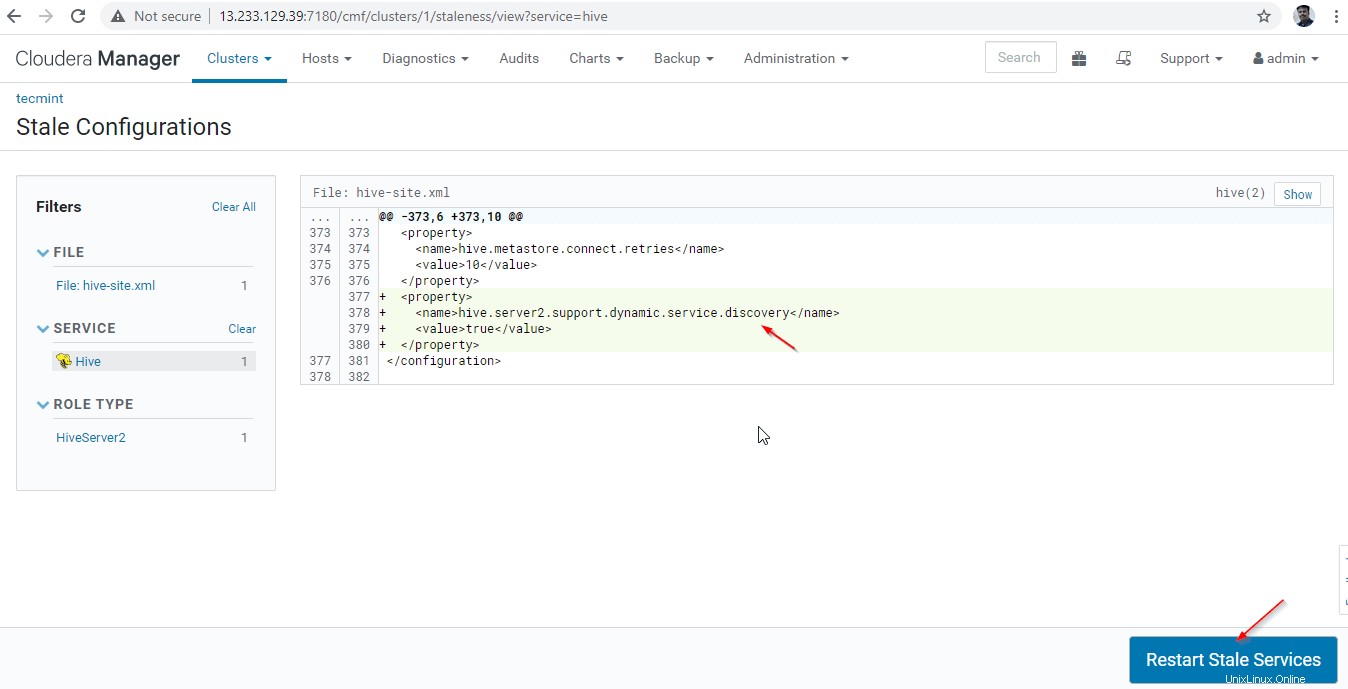
28. Ada dua pilihan yang tersedia. Jika cluster dalam produksi langsung, kita perlu memilih restart bergulir untuk meminimalkan pemadaman. Karena kami baru menginstal, kami dapat memilih opsi kedua 'Menerapkan Ulang Konfigurasi Klien ’, dan klik ‘Mulai Ulang Sekarang '.
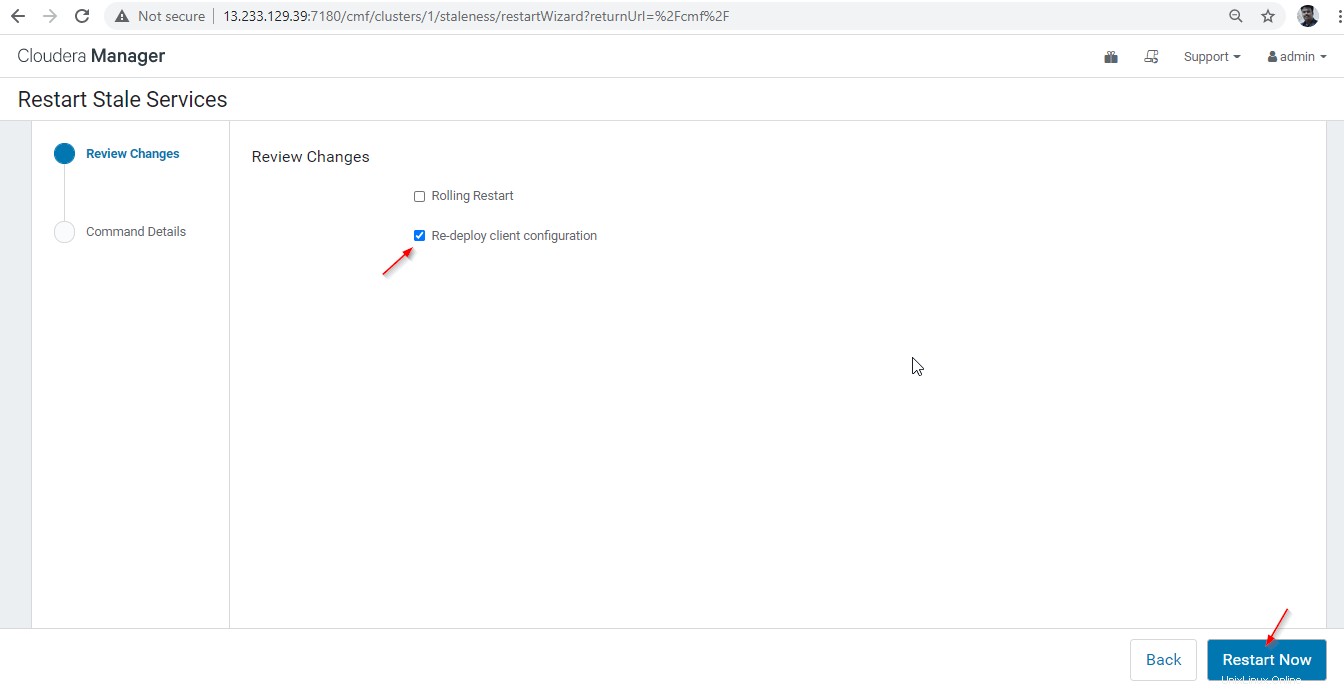
29. Setelah restart berhasil diselesaikan, Anda akan mendapatkan status 'Selesai '. Klik ‘Selesai ' untuk menyelesaikan prosesnya.
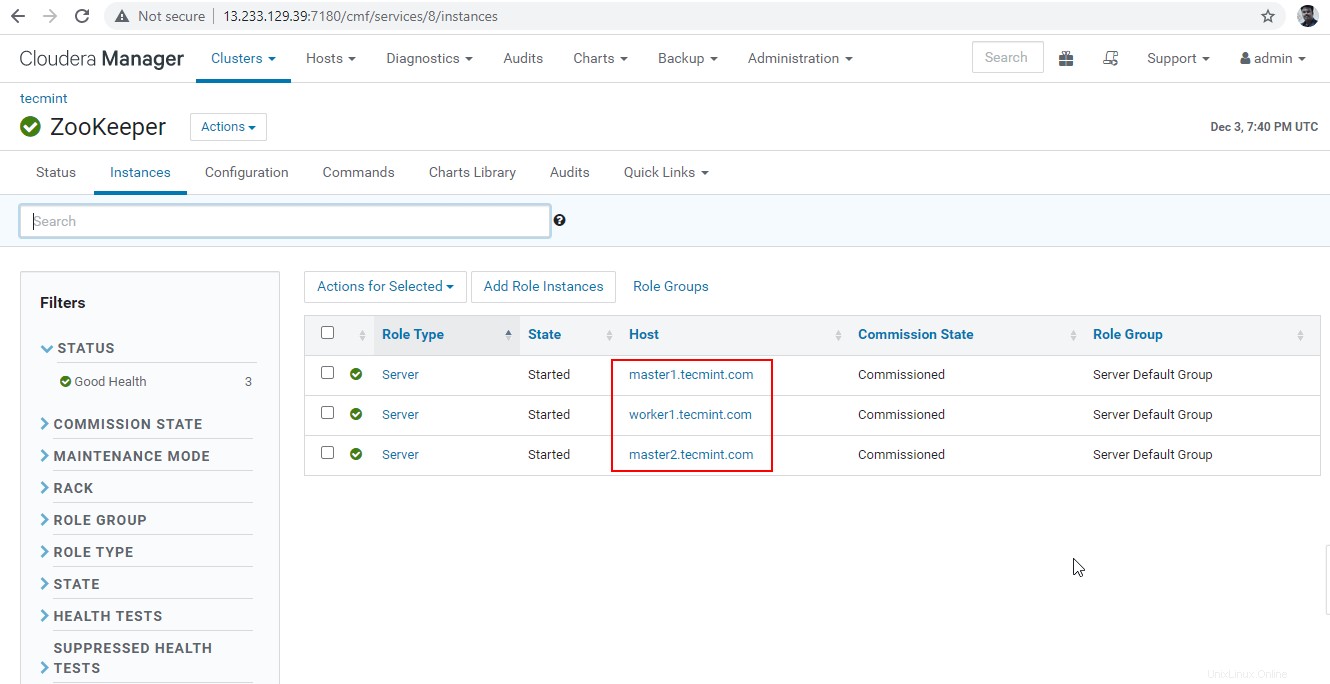
30. Sekarang kita akan menghubungkan Hiveserver2 menggunakan Penemuan Penjaga Kebun Binatang mode. Di JDBC koneksi, string yang kita butuhkan untuk menggunakan Zookeeper server dengan nomor portnya 2081 . Kumpulkan server Zookeeper dengan membuka Cloudera Manager –> Penjaga Kebun Binatang –> Instance -> (Catat nama server).
Ini adalah tiga server yang memiliki Zookeeper, 2181 adalah nomor portnya.
master1.tecmint.com:2181 master2.tecmint.com:2181 worker1.tecmint.com:2181
31. Sekarang masuk ke langsung menuju .
[[email protected] ~]$ beeline

32. Masukkan JDBC string koneksi seperti yang disebutkan di bawah ini. Kami harus menyebutkan Mode Penemuan Layanan dan Ruang Nama Penjaga Kebun Binatang . ‘hiveserver2 ' adalah Namespace default dari Hiveserver2.
beeline>!connect "jdbc:hive2://master1.tecmint.com:2181,master2.tecmint.com:2181,worker1.tecmint.com:2181/;serviceDiscoveryMode=zookeeper;zookeeperNamespace=hiveserver2"

33. Sekarang sesi terhubung ke Hiveserver2 berjalan di master1 . Jalankan kueri sampel untuk memvalidasi. Gunakan perintah di bawah ini untuk membuat database.
0: jdbc:hive2://master1.tecmint.com:2181,mast> create database tecmint;

34. Gunakan perintah di bawah ini untuk membuat daftar database.
0: jdbc:hive2://master1.tecmint.com:2181,mast> show databases;
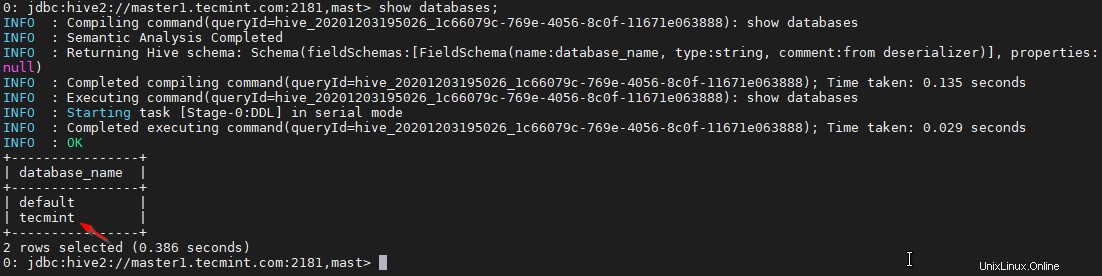
35. Sekarang kami akan memvalidasi Ketersediaan Tinggi dalam Mode Penemuan Penjaga Kebun Binatang . Buka Pengelola Cloudera dan hentikan Hiveserver2 di master1 yang telah kami uji di atas.
Pengelola Cloudera –> Sarang –> Instance –> (pilih Hiveserver2 di master1 ) –> Tindakan untuk yang dipilih –> Berhenti .
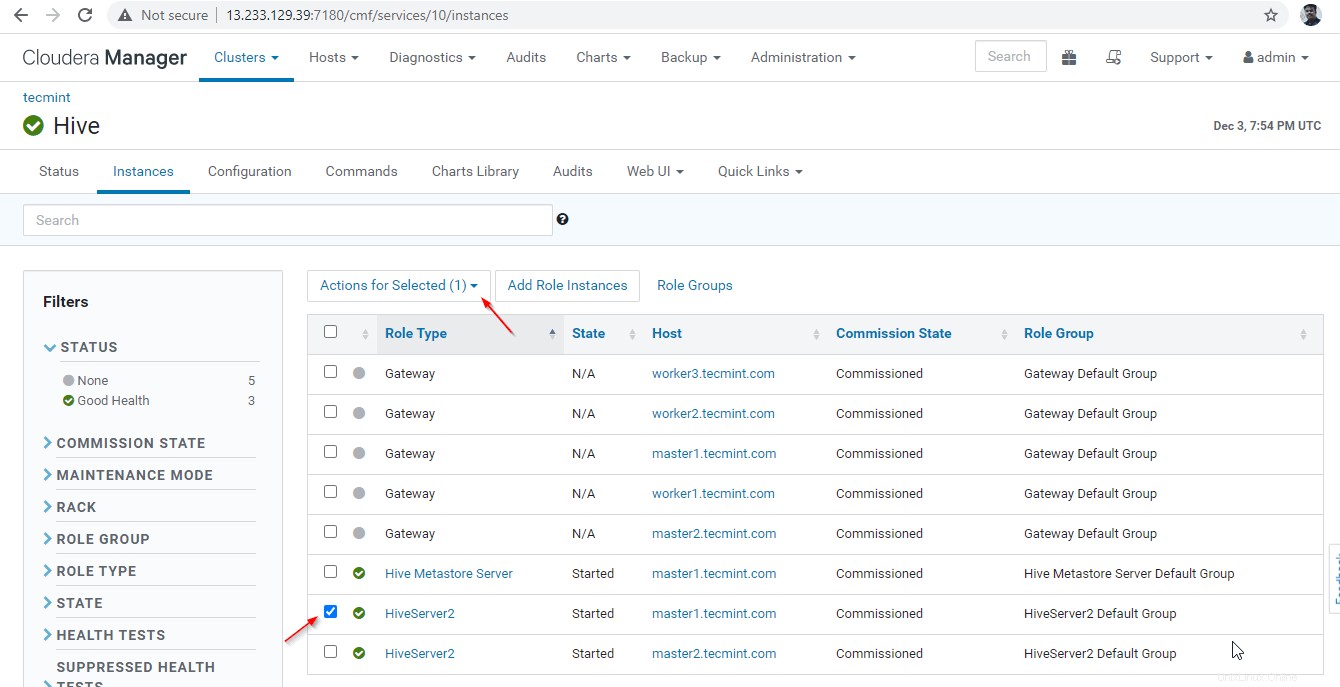
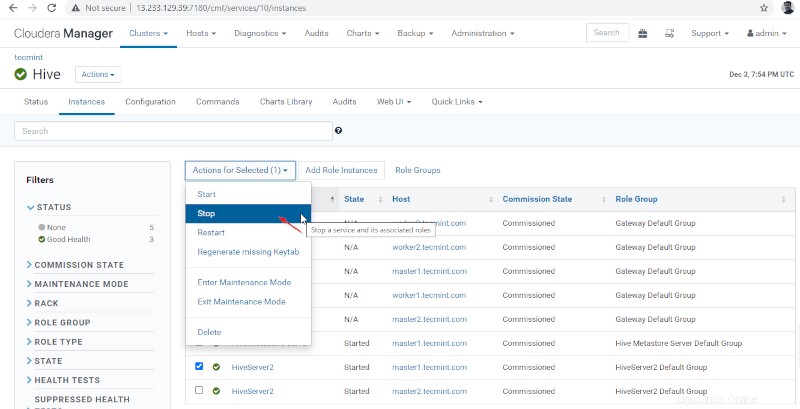
36. Klik tombol ‘Berhenti '. Setelah dihentikan, Anda akan mendapatkan status 'Selesai '. Verifikasi Hiveserver2 di master1 dengan menavigasi ke Hive –> Instance .
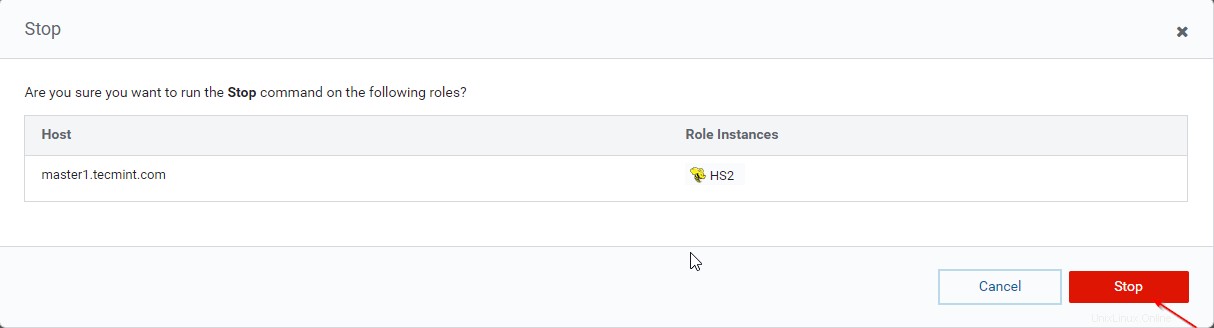
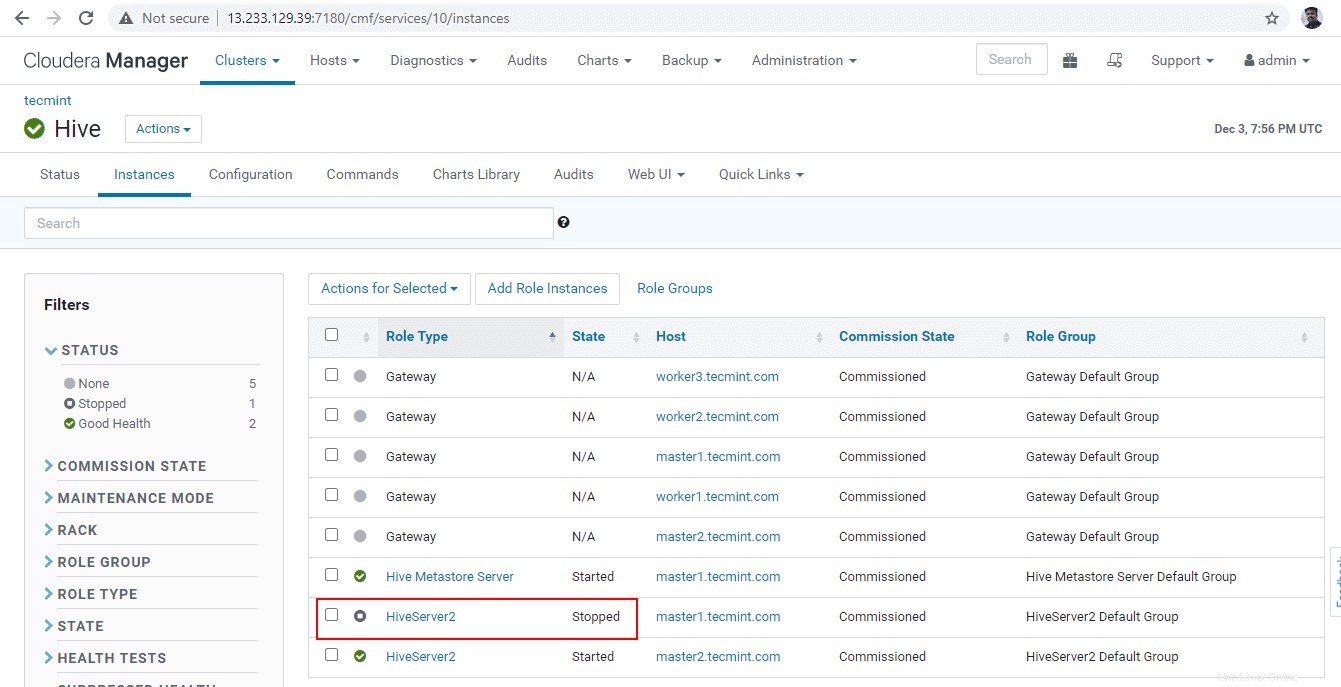
37. Masuk ke langsung menuju dan hubungkan Hiveserver2 menggunakan JDBC yang sama string koneksi dengan Mode Penemuan Penjaga Kebun Binatang seperti yang kita lakukan pada langkah-langkah di atas.
[[email protected] ~]$ beeline beeline>!connect "jdbc:hive2://master1.tecmint.com:2181,master2.tecmint.com:2181,worker1.tecmint.com:2181/;serviceDiscoveryMode=zookeeper;zookeeperNamespace=hiveserver2"

Sekarang Anda akan terhubung ke Hiveserver2 berjalan di master2 .
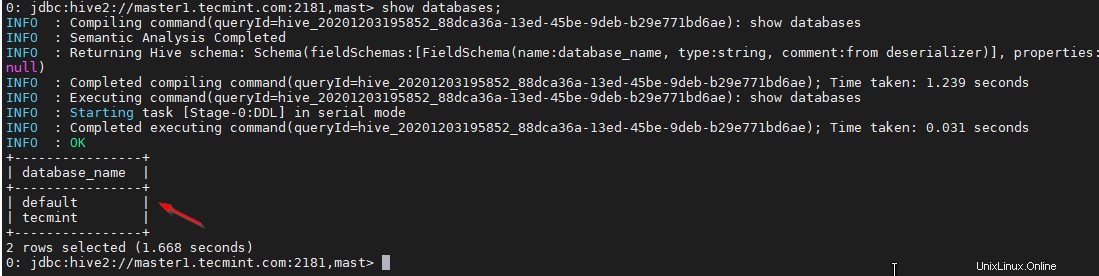
38. Validasi dengan kueri sampel.
0: jdbc:hive2://master1.tecmint.com:2181,mast> show databases;
Kesimpulan
Dalam artikel ini, kami telah melalui langkah-langkah mendetail untuk memiliki Hive Data Warehouse model di Cluster our kami dengan Ketersediaan Tinggi . Dalam lingkungan produksi waktu nyata, lebih dari tiga Hiveserver2 akan ditempatkan dengan Mode Penemuan Penjaga Kebun Binatang diaktifkan.
Di sini, semua Hiveserver2 sedang mendaftar ke Zookeeper di bawah Namespace common yang umum . Pemelihara Kebun Binatang Secara Dinamis menemukan Hiveserver2 . yang tersedia dan menetapkan sesi Hive.