Hadoop adalah kerangka kerja sumber terbuka yang banyak digunakan untuk menangani Bigdata . Sebagian besar Analisis Bigdata/Data proyek sedang dibangun di atas Hadoop Eco-System . Ini terdiri dari dua lapisan, satu untuk Menyimpan Data dan satu lagi untuk Memproses Data .
Penyimpanan akan diurus oleh sistem filenya sendiri yang disebut HDFS (Sistem File Terdistribusi Hadoop ) dan Memproses akan diurus oleh BENANG (Negosiator Sumber Daya Lain ). Mapreduce adalah mesin pemrosesan default dari Hadoop Eco-System .
Artikel ini menjelaskan proses untuk menginstal Pseudonode pemasangan Hadoop , tempat semua daemon (JVM ) akan menjalankan Single Node Kluster di CentOS 7 .
Ini terutama untuk pemula untuk belajar Hadoop. Dalam waktu nyata, Hadoop akan dipasang sebagai cluster multinode di mana data akan didistribusikan di antara server sebagai blok dan pekerjaan akan dijalankan secara paralel.
Prasyarat
- Penginstalan minimal server CentOS 7.
- Rilis Java v1.8.
- Rilis stabil Hadoop 2.x.
Di halaman ini
- Cara Menginstal Java di CentOS 7
- Mengatur Login Tanpa Kata Sandi di CentOS 7
- Cara Memasang Hadoop Single Node di CentOS 7
- Cara Mengonfigurasi Hadoop di CentOS 7
- Memformat Sistem File HDFS melalui NameNode
Menginstal Java di CentOS 7
1. Hadoop adalah Eko-Sistem yang terdiri dari Java . Kami membutuhkan Java diinstal di sistem kami secara wajib untuk menginstal Hadoop .
# yum install java-1.8.0-openjdk
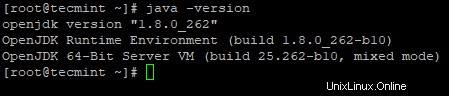
2. Selanjutnya, verifikasi versi Java yang diinstal pada sistem.
# java -versi
Konfigurasi Login Tanpa Kata Sandi di CentOS 7
Kita perlu mengonfigurasi ssh di mesin kita, Hadoop akan mengelola node dengan menggunakan SSH . Node master menggunakan SSH koneksi untuk menghubungkan node slave dan melakukan operasi seperti start dan stop.
Kita perlu mengatur ssh tanpa kata sandi sehingga master dapat berkomunikasi dengan budak menggunakan ssh tanpa kata sandi. Jika tidak, untuk setiap pembentukan koneksi, perlu memasukkan kata sandi.
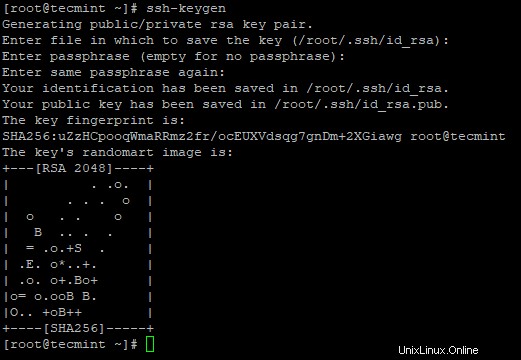
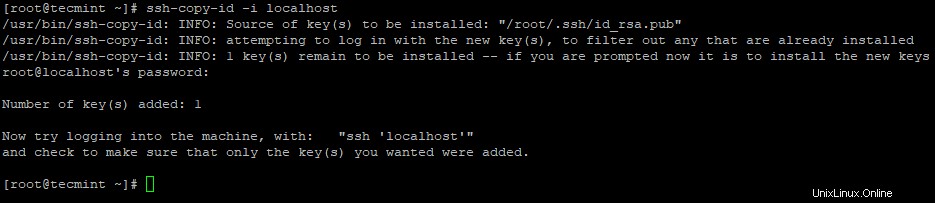
3. Siapkan login SSH tanpa kata sandi menggunakan perintah berikut di server.
# ssh-keygen# ssh-copy-id -i localhost
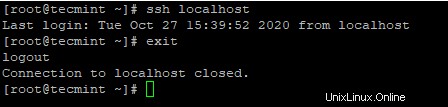
4. Setelah Anda mengkonfigurasi login SSH tanpa kata sandi, coba masuk lagi, Anda akan terhubung tanpa kata sandi.
# ssh localhost
Menginstal Hadoop di CentOS 7
5. Buka situs web Apache Hadoop dan unduh rilis stabil Hadoop menggunakan perintah wget berikut.
# wget https://archive.apache.org/dist/hadoop/core/hadoop-2.10.1/hadoop-2.10.1.tar.gz# tar xvpzf hadoop-2.10.1.tar.gz6. Selanjutnya, tambahkan Hadoop variabel lingkungan di
~/.bashrcfile seperti yang ditunjukkan.HADOOP_PREFIX=/root/hadoop-2.10.1PATH=$PATH:$HADOOP_PREFIX/binexport PATH JAVA_HOME HADOOP_PREFIX7. Setelah menambahkan variabel lingkungan ke
~/.bashrcfile, sumber file dan verifikasi Hadoop dengan menjalankan perintah berikut.# source ~/.bashrc# cd $HADOOP_PREFIX# versi bin/hadoop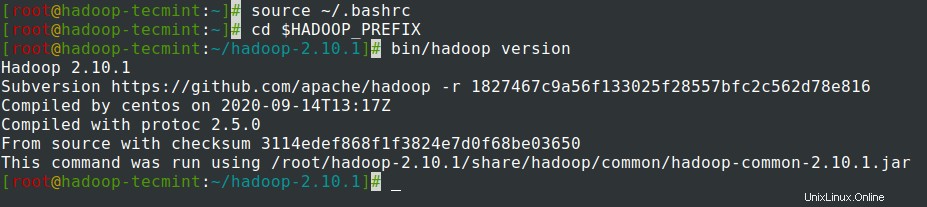
Mengonfigurasi Hadoop di CentOS 7
Kami perlu mengonfigurasi file konfigurasi Hadoop di bawah ini agar sesuai dengan mesin Anda. Di Hadoop, setiap layanan memiliki nomor port sendiri dan direktori sendiri untuk menyimpan data.
- File Konfigurasi Hadoop – core-site.xml, hdfs-site.xml, mapred-site.xml &yarn-site.xml
8. Pertama, kita perlu memperbarui JAVA_HOME dan Hadoop jalur di hadoop-env.sh file seperti yang ditunjukkan.
# cd $HADOOP_PREFIX/etc/hadoop# vi hadoop-env.sh
Masukkan baris berikut di awal file.
ekspor JAVA_HOME=/usr/lib/jvm/java-1.8.0/jreexport HADOOP_PREFIX=/root/hadoop-2.10.1
9. Selanjutnya, ubah core-site.xml berkas.
# cd $HADOOP_PREFIX/etc/hadoop# vi core-site.xml
Rekatkan yang berikut di antara <configuration> tag seperti yang ditunjukkan.
fs.defaultFS hdfs://localhost:9000
10. Buat direktori di bawah ini di bawah tecmint direktori home pengguna, yang akan digunakan untuk NN dan DN penyimpanan.
# mkdir -p /home/tecmint/hdata/# mkdir -p /home/tecmint/hdata/data# mkdir -p /home/tecmint/hdata/name
10. Selanjutnya, ubah hdfs-site.xml berkas.
# cd $HADOOP_PREFIX/etc/hadoop# vi hdfs-site.xml
Rekatkan yang berikut di antara <configuration> tag seperti yang ditunjukkan.
dfs.replication 1 dfs.namenode.name.dir /home/tecmint/ hdata/name dfs .datanode.data.dir home/tecmint/hdata/data
11. Sekali lagi, ubah mapred-site.xml berkas.
# cd $HADOOP_PREFIX/etc/hadoop# cp mapred-site.xml.template mapred-site.xml# vi mapred-site.xml
Rekatkan yang berikut di antara <configuration> tag seperti yang ditunjukkan.
mapreduce.framework.name benang
12. Terakhir, ubah yarn-site.xml berkas.
# cd $HADOOP_PREFIX/etc/hadoop# vi yarn-site.xml
Rekatkan yang berikut di antara <configuration> tag seperti yang ditunjukkan.
yarn.nodemanager.aux-services mareduce_shuffle
Memformat Sistem File HDFS melalui NameNode
13. Sebelum memulai Cluster , kita perlu memformat Hadoop NN di sistem lokal kami di mana telah diinstal. Biasanya akan dilakukan pada tahap awal sebelum memulai cluster pertama kali.
Memformat NN akan menyebabkan hilangnya data di metastore NN, jadi kita harus lebih berhati-hati, jangan memformat NN saat cluster sedang berjalan kecuali jika diperlukan dengan sengaja.
# cd $HADOOP_PREFIX# bin/hadoop namenode -format
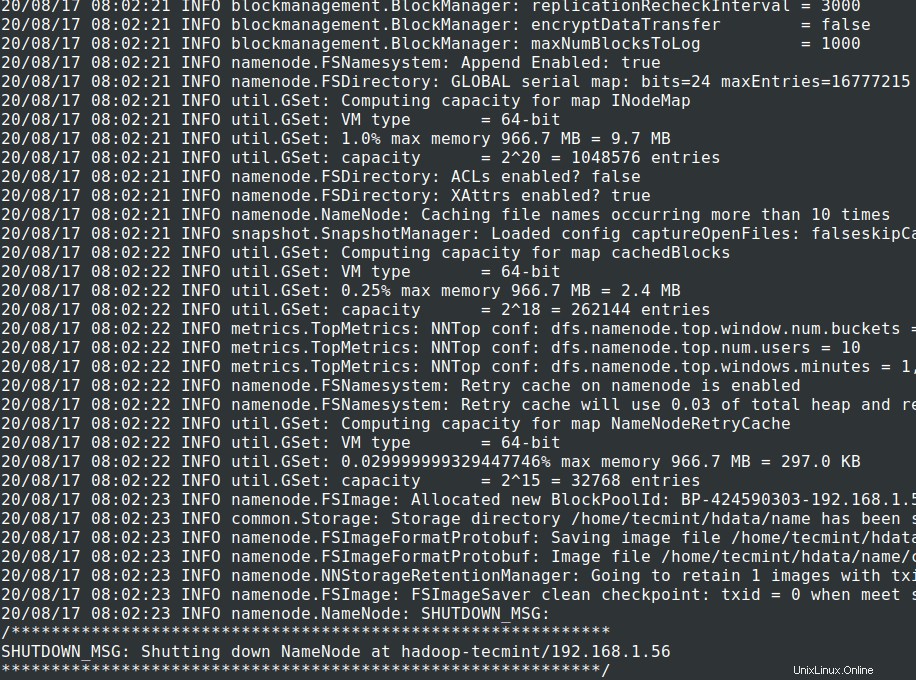
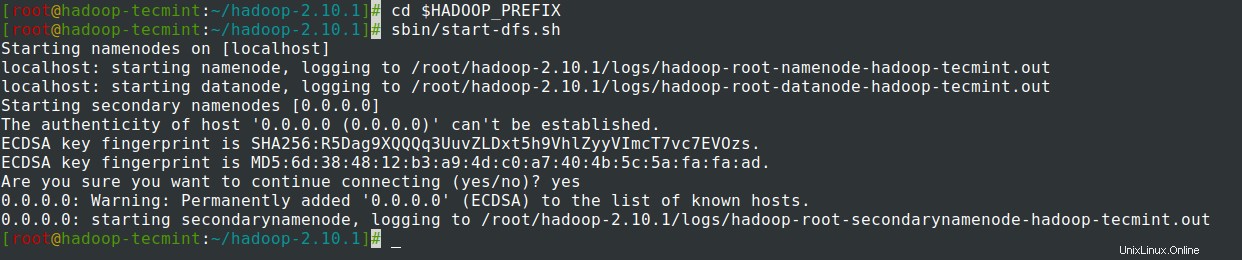
14. Mulai NameNode daemon dan DataNode daemon:(port 50070 ).
# cd $HADOOP_PREFIX# sbin/start-dfs.sh
15. Mulai ResourceManager daemon dan NodeManager daemon:(port 8088 ).
# sbin/start-yarn.sh

16. Untuk menghentikan semua layanan.
# sbin/stop-dfs.sh# sbin/stop-dfs.sh
Ringkasan
Ringkasan
Dalam artikel ini, kita telah melalui proses langkah demi langkah untuk menyiapkan Hadoop Pseudonode (Simpul Tunggal ) Kelompok . Jika Anda memiliki pengetahuan dasar tentang Linux dan mengikuti langkah-langkah ini, cluster akan UP dalam 40 menit.
Ini bisa sangat berguna bagi pemula untuk mulai belajar dan berlatih Hadoop atau versi vanilla dari Hadoop dapat digunakan untuk tujuan Pembangunan. Jika kita ingin memiliki cluster real-time, kita memerlukan setidaknya 3 server fisik atau harus menyediakan Cloud untuk memiliki beberapa server.