Membuat plot statistik dengan Python bisa merepotkan, terutama jika Anda membuatnya secara manual. Namun dengan bantuan perpustakaan visualisasi data Seaborn Python, Anda dapat menyederhanakan pekerjaan Anda dan membuat plot yang indah dengan cepat dan dengan lebih sedikit baris kode.
Dengan Seaborn, membuat plot statistik yang indah untuk data Anda adalah hal yang mudah. Panduan ini akan menunjukkan kepada Anda cara menggunakan perpustakaan yang hebat ini melalui contoh nyata.
Prasyarat
Tutorial ini akan menjadi demonstrasi langsung. Jika Anda ingin mengikuti, pastikan Anda memiliki yang berikut:
- Komputer Windows atau Linux dengan Python dan Anaconda terinstal. Tutorial ini akan menggunakan Anaconda 2021.11 dengan Python 3.9 pada PC Windows 10.
Apa itu Perpustakaan Python Seaborn?
Pustaka Seaborn Python adalah pustaka visualisasi data Python yang dibangun di atas pustaka Matplotlib. Seaborn menawarkan seperangkat alat tingkat tinggi yang kaya untuk membuat bagan dan plot statistik. Kapasitas Seaborn untuk berintegrasi dengan objek Pandas Dataframe memungkinkan Anda memvisualisasikan data dengan cepat.
DataFrame mewakili data tabular, seperti yang akan Anda temukan di tabel, spreadsheet, atau file CSV nilai yang dipisahkan koma.
Seaborn bekerja dengan Pandas DataFrames dan mengonversi data menjadi kode yang dapat dipahami Matplotlib.
Meskipun ada banyak plot berkualitas tinggi yang tersedia, Anda akan belajar dalam tutorial ini tentang tiga keluarga plot bawaan Seaborn yang paling umum untuk membantu Anda memulai.
- Plot relasional.
- Plot distribusi.
- Plot Kategoris.
Seaborn menyertakan lebih banyak plot, dan tutorial ini tidak dapat mencakup semuanya. Dokumentasi API Seaborn dan tutorialnya adalah titik awal yang sangat baik untuk mengenal semua jenis plot Seaborn yang berbeda.
Menyiapkan Lingkungan JupyterLab dan Seaborn Python Baru
Sebelum memulai perjalanan Seaborn, Anda harus menyiapkan lingkungan Jupyter Lab terlebih dahulu. Selain itu, untuk konsistensi dengan contoh, Anda akan mengerjakan kumpulan data tertentu bersama dengan tutorial ini.
JupyterLab adalah aplikasi web yang memungkinkan Anda menggabungkan kode, teks kaya, plot, dan media lainnya ke dalam satu dokumen. Anda juga dapat berbagi buku catatan secara online dengan orang lain atau menggunakannya sebagai dokumen yang dapat dijalankan.
Untuk mulai menyiapkan lingkungan Anda, ikuti langkah-langkah berikut.
1. Buka Anaconda Navigato r di komputer Anda.
sebuah. Di komputer Windows:Klik Mulai —> Anaconda3 —> Anaconda Navigator .
b. Di komputer Linux:Jalankan anaconda-navigator perintah di terminal.
2. Di Anaconda Navigator, cari JupyterLab aplikasi dan klik Luncurkan . Melakukannya akan membuka instance JupyterLab di browser web.

3. Setelah meluncurkan JypyterLab, buka sidebar File Browser dan buat folder baru bernama ATA_Seaborn di bawah profil atau direktori home Anda. Folder baru ini akan menjadi direktori proyek Anda.
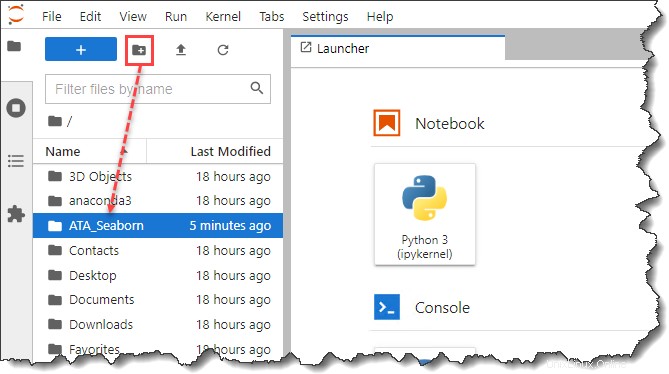
4. Selanjutnya, buka tab browser baru dan unduh Pokemon Himpunan data. Pastikan untuk menyimpan ata_pokemon.csv file ke direktori proyek yang Anda buat, yang dalam contoh ini adalah ATA_Seaborn .
5. Kembali ke JupyterLab, klik dua kali ATA_Seaborn map. Anda sekarang akan melihat ata_pokemon.csv di bawah folder itu.
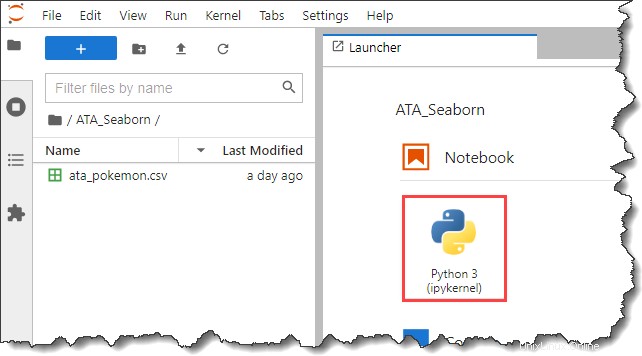
6. Sekarang, klik Python 3 tombol di bawah Buku Catatan bagian di Peluncur tab untuk membuat buku catatan baru.
7. Sekarang, klik buku catatan baru Untitled.ipynb dan tekan F2 untuk mengganti nama file. Ubah nama file menjadi ata_pokemon.ipynb .

8. Selanjutnya, tambahkan judul ke buku catatan Anda. Langkah ini opsional tetapi disarankan untuk membuat proyek Anda lebih mudah dikenali.
Di bilah alat buku catatan Anda, klik menu tarik-turun yang bertuliskan Kode dan klik Penurunan harga.
9. Masukkan teks, "# Pokemon Data Visualization", di dalam sel penurunan harga dan tekan tombol Shift + Enter.
Pemilihan jenis sel secara otomatis berubah menjadi Kode, dan notebook akan memiliki judul Visualisasi Data Pokemon di atas.
10. Terakhir, simpan pekerjaan Anda dengan menekan tombol Ctrl + S.
Pastikan Anda sering menyimpan pekerjaan. Anda harus sering menyimpan pekerjaan Anda untuk menghindari kehilangan apa pun jika ada masalah dengan koneksi internet. Setiap kali Anda membuat perubahan, tekan
CTRL+Suntuk menyimpan kemajuan Anda. Anda juga dapat mengeklik tombol Simpan di bilah alat.
Mengimpor Perpustakaan Panda dan Python Seaborn
Kode Python biasanya dimulai dengan mengimpor perpustakaan yang diperlukan. Dan dalam proyek ini, Anda akan bekerja dengan perpustakaan Pandas dan Seaborn Python.
Untuk mengimpor Pandas dan Seaborn, salin kode di bawah ini dan tempelkan ke sel perintah di notebook Anda.
Ingat ini — untuk menjalankan kode atau perintah di sel perintah, tekan tombol Shift + Enter.
# import Seaborn libraries
import seaborn as sns
# import Pandas libraries
import pandas as pdSelanjutnya, jalankan perintah di bawah ini untuk menerapkan estetika tema default Seaborn ke plot yang akan Anda buat.
sns.set_theme()
Seaborn memiliki lima tema bawaan yang tersedia. Mereka adalah darkgrid (default), whitegrid , dark , white , dan ticks .
Mengimpor Kumpulan Data Contoh
Sekarang setelah Anda menyiapkan lingkungan JupyterLab, mari impor data dari kumpulan data ke lingkungan Jupyter Anda.
1. Jalankan pd.read_csv() perintah dalam sel untuk mengimpor data. Nama file kumpulan data harus berada di dalam tanda kurung untuk menunjukkan file yang akan diimpor diapit dalam tanda kutip ganda.
Perintah di bawah ini akan mengimpor ata_pokemon.csv dan simpan dataset ke pokemon variabel.
pokemon = pd.read_csv("ata_pokemon.csv")
2. Jalankan pokemon.head() perintah untuk mempratinjau lima baris pertama dari kumpulan data yang diimpor.
pokemon.head()Anda akan mendapatkan output berikut.
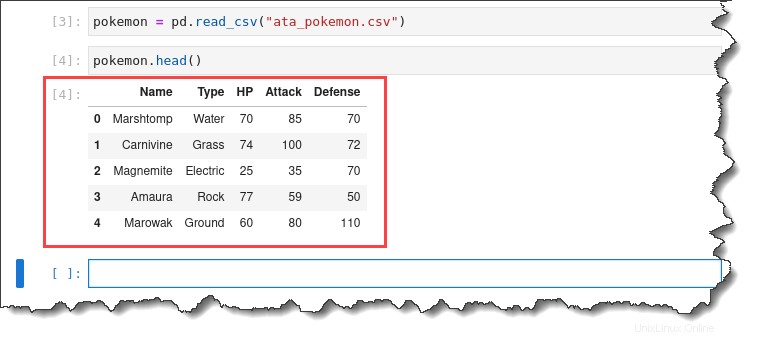
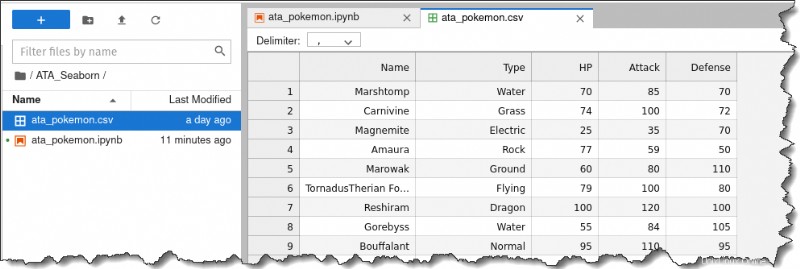
3. Klik dua kali pada ata_pokemon.csv file di sebelah kiri untuk memeriksa setiap baris individu. Anda akan mendapatkan output berikut.
Seperti yang Anda lihat, kumpulan data ini cukup nyaman untuk digunakan karena daftar setiap pengamatan menurut baris, dan semua informasi numerik ada di kolom terpisah.
Sekarang, mari ajukan beberapa pertanyaan tentang kumpulan data untuk membantu analisis.
- Apa hubungan antara Serangan dan HP?
- Bagaimana distribusi Serangan?
- Apa hubungan antara Serangan dan Tipe?
- Bagaimana distribusi Attack untuk setiap Type?
- Berapa rata-rata, atau rata-rata, Serangan untuk setiap Jenis?
- Dan berapa jumlah Pokemon untuk setiap Jenis?
Perhatikan bahwa banyak dari pertanyaan ini berfokus pada hubungan data numerik dan kategoris. Data kategoris berarti data non-numerik, yang, dalam kumpulan data sampel ini, adalah Jenis Pokemon.
Tidak seperti Matplotlib, yang dioptimalkan untuk membuat plot dengan data numerik yang ketat, Anda dapat menggunakan Seaborn untuk menganalisis data yang memiliki data kategorikal dan numerik.
Membuat Plot Hubungan
Jadi, Anda telah mengimpor kumpulan data. Apa berikutnya? Sekarang Anda akan menggunakan data yang diimpor dan menghasilkan plot statistik darinya. Mari kita mulai dengan membuat plot relasional atau hubungan untuk menemukan hubungan antara HP dan Serang data.
Plot hubungan praktis saat mengidentifikasi kemungkinan hubungan antara variabel dalam kumpulan data Anda. Seaborn memiliki dua plot untuk memetakan hubungan:plot sebar dan plot garis.
Memplot garis
Membuat plot garis mengharuskan Anda untuk memanggil Seaborn Python lineplot() fungsi. Fungsi ini membutuhkan tiga parameter — data= , x=' , dan y=' ‘.
Salin perintah di bawah ini dan jalankan di sel perintah Jupyter Anda. Perintah ini menggunakan pokemon objek sebagai sumber data yang sebelumnya Anda impor, HP data kolom untuk sumbu x, dan Attack data untuk sumbu y.
sns.lineplot(data=pokemon, x='HP', y='Attack')Seperti yang Anda lihat di bawah, plot garis tidak berfungsi dengan baik untuk menunjukkan kepada Anda informasi yang dapat Anda analisis dengan cepat. Plot garis lebih baik dalam menampilkan sumbu x yang mengikuti variabel kontinu seperti waktu.
Dalam contoh ini, Anda sedang merencanakan sebuah variabel diskrit HP. Jadi yang terjadi adalah plot garisnya menyebar ke mana-mana. Dan lebih sulit untuk menyimpulkan tren.
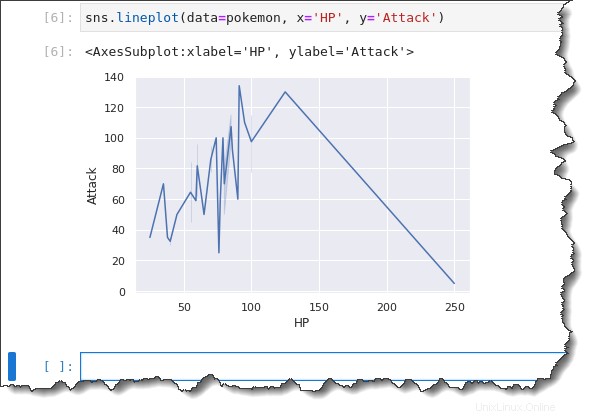
Plot Menyebar
Bagian dari analisis data eksplorasi adalah mencoba berbagai hal untuk melihat apa yang bekerja dengan baik. Dan dengan melakukannya, Anda akan belajar bahwa beberapa plot dapat menunjukkan wawasan yang lebih baik daripada yang lain.
Lalu, apa yang membuat plot hubungan lebih baik daripada plot garis? — Plot sebar.
Untuk membuat plot sebar, panggil fungsi sebar, sns.scatterplot , dan berikan tiga parameter: data=pokemon , x=HP , dan y=Attack .
Jalankan perintah berikut untuk membuat scatterplot untuk dataset pokemon.
sns.scatterplot(data=pokemon, x='HP', y='Attack')Seperti yang Anda lihat pada hasil di bawah, plot sebar menunjukkan kepada Anda bahwa mungkin ada korelasi positif umum antara HP (sumbu x) dan Serangan (sumbu y), dengan satu outlier.
Umumnya, saat HP meningkat, Serangan juga meningkat. Pokemon dengan poin kesehatan yang lebih besar cenderung lebih kuat.
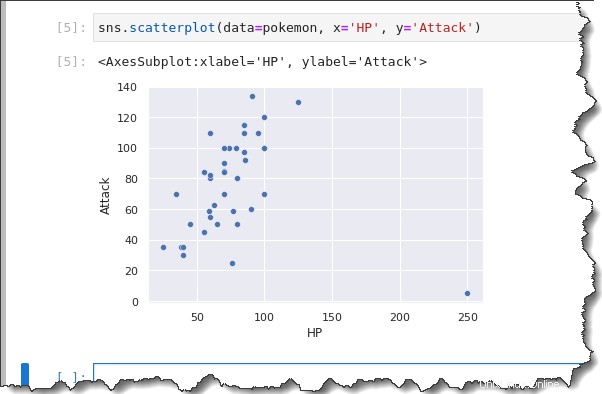
Merencanakan Menyebarkan dengan Legenda
Sementara plot sebar sudah menyajikan visualisasi data yang lebih masuk akal, Anda masih dapat meningkatkan grafik lebih lanjut dengan memecah distribusi tipe dengan legenda.
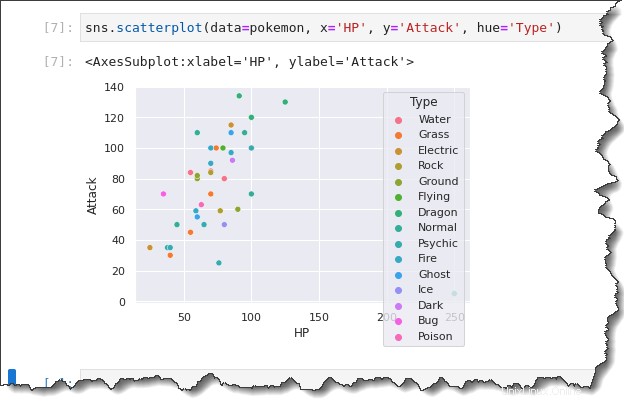
Jalankan sns.scatterplot() berfungsi lagi dalam contoh berikut. Tapi kali ini, tambahkan hue='Type' kata kunci, yang akan membuat legenda yang menunjukkan Jenis Pokemon yang berbeda. Kembali ke tab notebook Jupyter Anda, jalankan perintah di bawah ini.
sns.scatterplot(data=pokemon, x='HP', y='Attack', hue='Type')Perhatikan hasil di bawah ini, scatter plot sekarang memiliki warna yang berbeda. Menganalisis aspek kategoris data Anda sekarang jauh lebih baik karena perbedaan visual yang diberikan legenda.
Apa yang lebih baik adalah Anda masih dapat memecah plot lebih jauh dengan menggunakan sns.relplot() fungsi dengan col=Type dan col_wrap argumen kata kunci.
Jalankan perintah di bawah ini di Jupyter untuk membuat plot untuk setiap Jenis Pokemon dalam format kisi multi-plot.
sns.relplot(data=pokemon, x='HP', y='Attack', hue='Type', col='Type', col_wrap=3)Melihat hasil di bawah ini, Anda dapat menyimpulkan bahwa HP dan Attack umumnya berkorelasi positif. Pokemon dengan HP lebih banyak cenderung lebih kuat.
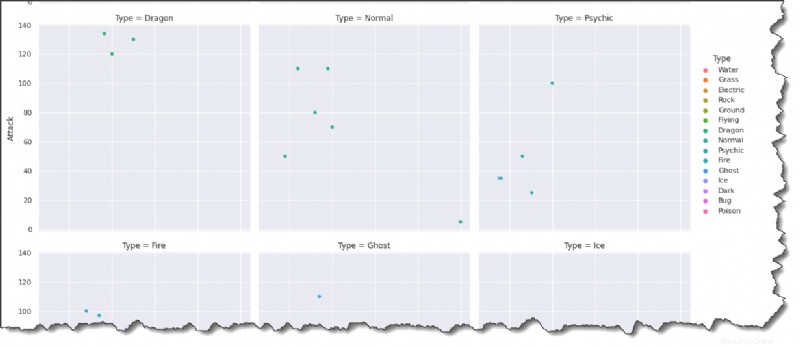
Setujukah Anda bahwa menambahkan warna dan legenda membuat plot menjadi lebih menarik?
Membuat Plot Distribusi
Pada bagian sebelumnya, Anda telah membuat scatterplot. Kali ini, mari kita gunakan plot distribusi untuk mendapatkan insight tentang distribusi Attack dan HP untuk setiap Tipe Pokemon.
Plot Histogram
Anda dapat menggunakan histogram untuk memvisualisasikan distribusi variabel. Dalam kumpulan data sampel Anda, variabelnya adalah Serangan Pokemon.
Untuk membuat plot histogram, jalankan sns.histplot() fungsi di bawah. Fungsi ini membutuhkan dua parameter:data=pokemon dan x='Attack' . Salin perintah di bawah ini dan jalankan di Jupyter.
sns.histplot(data=pokemon, x='Attack')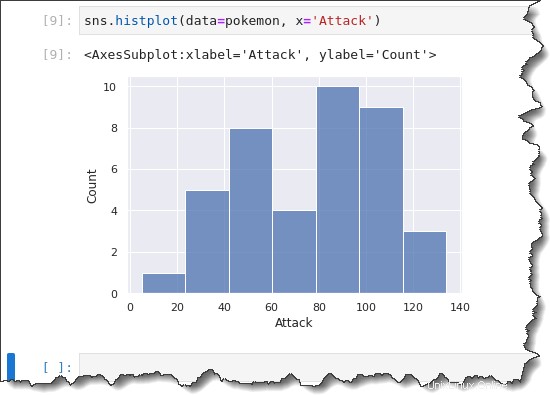
Saat membuat histogram, Seaborn secara otomatis memilih ukuran nampan yang optimal untuk Anda. Anda mungkin ingin mengubah ukuran nampan untuk mengamati distribusi data dalam bentuk pengelompokan yang berbeda.
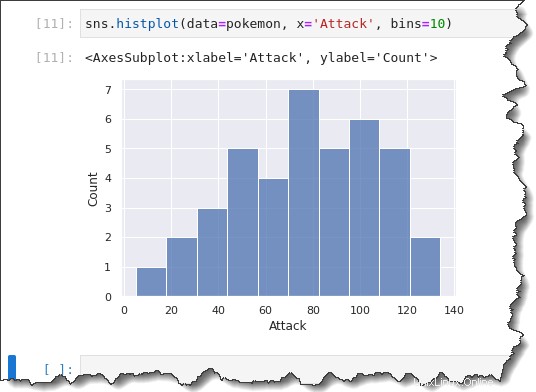
Untuk menentukan ukuran nampan tetap atau kustom, tambahkan bins=x argumen ke perintah di mana x adalah ukuran bin kustom. Jalankan perintah di bawah ini untuk membuat histogram dengan ukuran bin 10.
sns.histplot(data=pokemon, x='Attack', bins=10)Dalam histogram sebelumnya yang Anda buat, Serangan Pokemon tampaknya memiliki distribusi bimodal (dua punuk besar.)
Tetapi ketika Anda melihat ukuran bin Anda 10, pengelompokan dipecah lebih segmental. Anda dapat melihat bahwa ada lebih banyak distribusi unimodal, dengan kemiringan ke kanan.
Plot Estimasi Kepadatan Kernel (KDE)
Cara lain untuk memvisualisasikan distribusi adalah dengan plot estimasi densitas kernel. KDE pada dasarnya seperti histogram tetapi dengan kurva, bukan kolom.
Keuntungan menggunakan plot KDE adalah Anda dapat membuat kesimpulan lebih cepat tentang bagaimana data didistribusikan karena kurva probabilitas, yang menunjukkan fitur seperti tendensi sentral, modalitas, dan kemiringan.
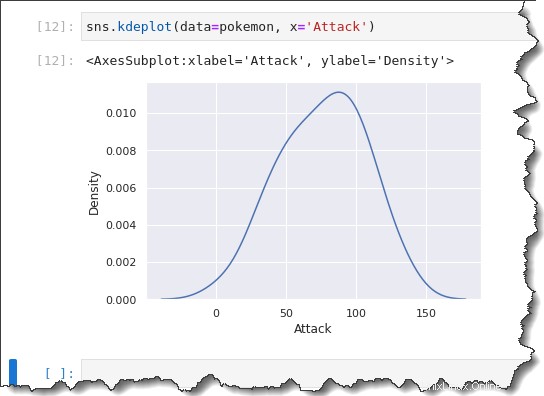
Untuk membuat plot KDE, panggil sns.kdeplot() fungsi dan berikan data=pokemon yang sama , x='Attack' sebagai argumen. Jalankan kode di bawah ini di Jupyter untuk melihat plot KDE beraksi.
sns.kdeplot(data=pokemon, x='Attack')Seperti yang Anda lihat di bawah, plot KDE mirip dengan histogram dengan ukuran bin 10.
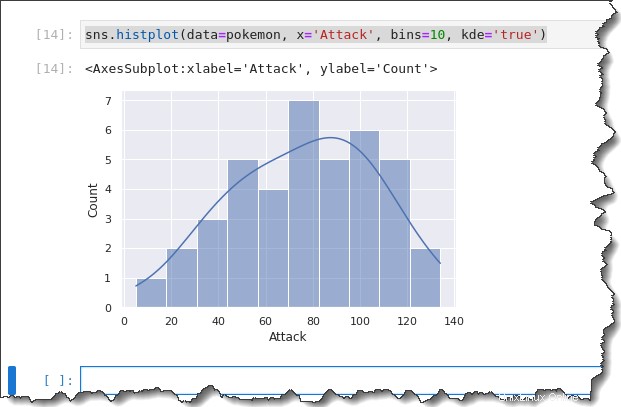
Karena histogram dan KDE serupa, mengapa tidak menggunakannya bersama-sama? Seaborn memungkinkan Anda melapisi KDE pada histogram dengan menambahkan kata kunci kde='true' argumen ke perintah sebelumnya, seperti yang Anda lihat di bawah.
sns.histplot(data=pokemon, x='Attack', bins=10, kde='true')Anda akan mendapatkan output berikut. Menurut histogram di bawah, sebagian besar Pokemon memiliki titik Serangan yang didistribusikan antara 50 dan 120. Bukankah itu penyebaran yang bagus!
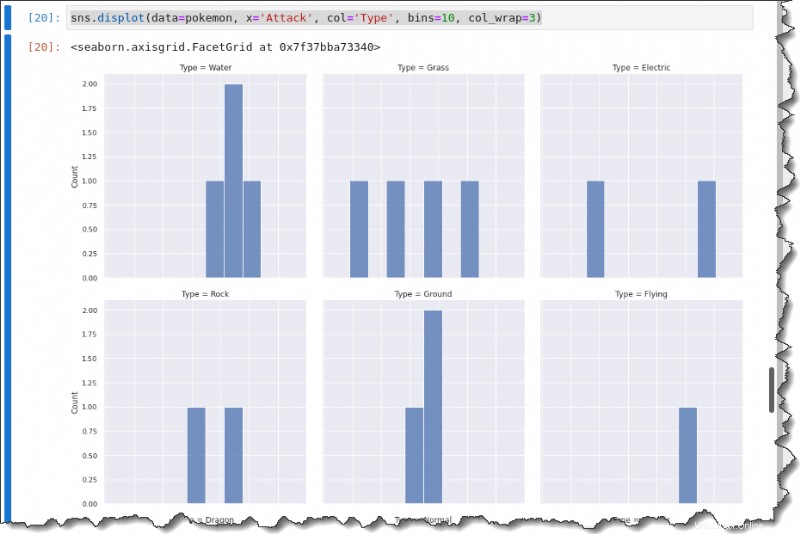
Untuk memecah setiap distribusi serangan berdasarkan Jenis, panggil displot() fungsi dengan col kata kunci di bawah ini untuk membuat plot multi-kisi yang menunjukkan setiap Jenis.
sns.displot(data=pokemon, x='Attack', col='Type', bins=10, col_wrap=3)Anda akan mendapatkan output berikut.
Membuat Plot Kategoris
Membuat histogram terpisah berdasarkan kategori tipe itu bagus. Namun, histogram mungkin tidak memberikan gambaran yang jelas untuk Anda. Jadi, mari gunakan beberapa plot kategoris Seaborn untuk membantu Anda menganalisis data serangan lebih lanjut berdasarkan jenis Pokemon.
Strip Plotting
Dalam plot pencar dan histogram sebelumnya, Anda mencoba memvisualisasikan data Serangan menurut variabel kategori (Type ). Kali ini kamu akan membuat strip plot, yaitu rangkaian scatter plot yang dikelompokkan berdasarkan kategorinya.
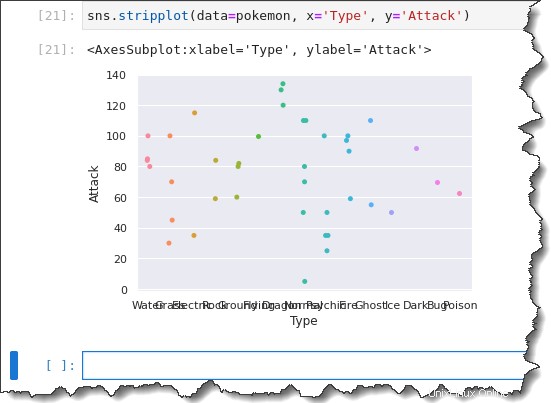
Untuk membuat plot strip kategoris, panggil sns.stripplot() fungsi dan berikan tiga argumen:data=pokemon , x='Type' , dan y='Attack' . Jalankan kode di bawah ini di Jupyter untuk menghasilkan plot strip kategoris.
sns.stripplot(data=pokemon, x='Type', y='Attack')Sekarang Anda memiliki plot strip dengan semua pengamatan yang dikelompokkan berdasarkan Type. Tapi perhatikan bagaimana label sumbu-x disatukan? Tidak terlalu membantu, kan?
Untuk memperbaiki label sumbu x, Anda harus menggunakan fungsi lain yang disebut catplot() .
Di sel perintah notebook Jupyter Anda, jalankan sns.catplot() fungsi dan berikan lima argumenkind='strip' , data=pokemon , x='Type' , y='Attack' , danaspect=2 , seperti yang ditunjukkan di bawah ini.
sns.catplot(kind='strip', data=pokemon, x='Type', y='Attack', aspect=2)Kali ini, pot yang dihasilkan menampilkan label sumbu x dengan lebar penuh, membuat analisis Anda lebih nyaman.
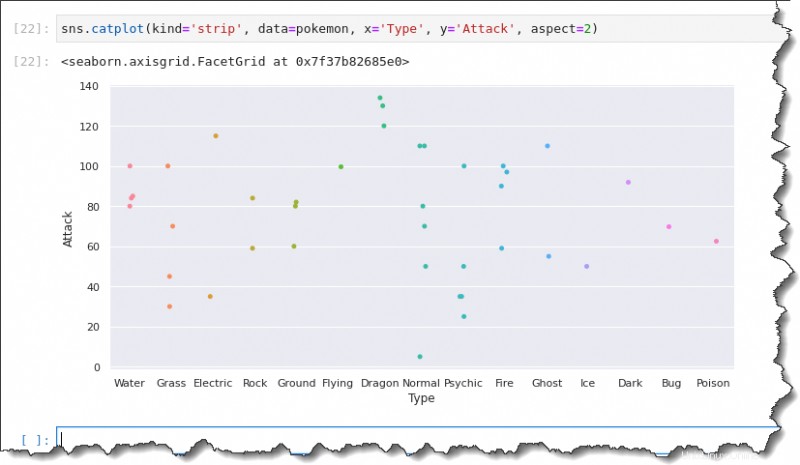
Perencanaan Kotak
catplot() function memiliki subfamili plot lain yang akan membantu Anda memvisualisasikan distribusi data dengan variabel kategoris. Salah satunya adalah plot kotak.
Untuk membuat plot kotak, jalankan sns.catplot() fungsi dengan argumen berikut:data=pokemon , kind='box' , x='Type' , y='Attack' , dan aspect=2 .
aspect argumen mengontrol jarak antara label sumbu x. Nilai yang lebih tinggi berarti penyebaran yang lebih luas.
sns.catplot(data=pokemon, kind='box', x='Type', y='Attack', aspect=2)
Output ini memberi Anda ringkasan penyebaran data. Menggunakan catplot() fungsi, Anda bisa mendapatkan penyebaran data untuk setiap Jenis Pokemon di satu plot.
Perhatikan bahwa spidol berlian hitam mewakili outlier. Alih-alih plot kotak, garis di tengah berarti hanya ada satu pengamatan untuk Jenis Pokemon tersebut.
Anda memiliki ringkasan lima angka untuk masing-masing plot kotak dan kumis ini. Garis di tengah kotak mewakili nilai median atau kecenderungan pusat titik Serangannya.
Anda juga memiliki kuartil pertama dan ketiga serta kumis, yang mewakili nilai maksimum dan minimum.
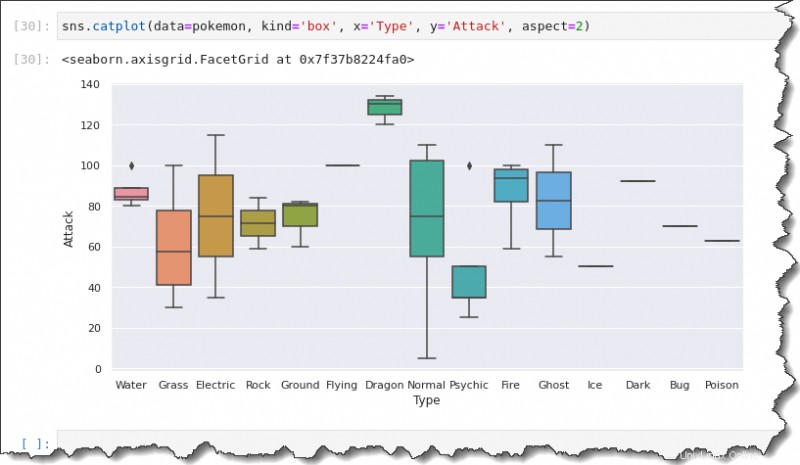
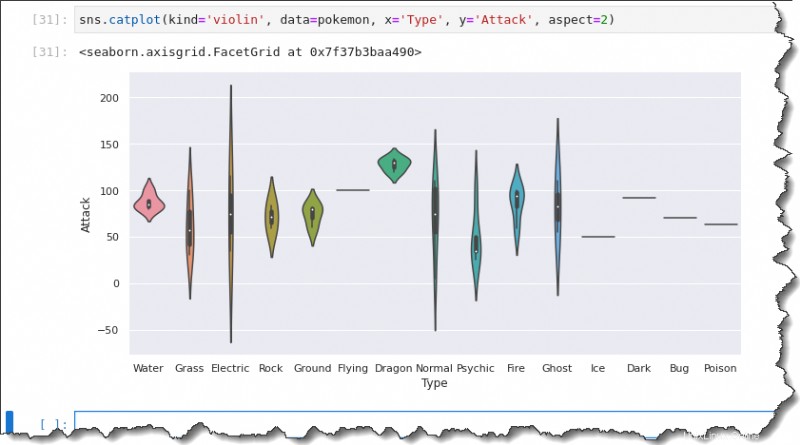
Merencanakan Biola
Cara lain untuk memvisualisasikan distribusi adalah dengan menggunakan plot biola. Plot biola seperti plot kotak dan campuran KDE. Plot biola analog dengan plot kotak.
Untuk membuat plot biola, ganti kind nilai ke violin , sedangkan sisanya sama seperti saat Anda menjalankan perintah box plotting. Jalankan kode di bawah ini untuk membuat plot biola.
sns.catplot(kind='violin', data=pokemon, x='Type', y='Attack', aspect=2)Hasilnya, Anda dapat melihat bahwa plot biola mencakup kuartil median, kuartil pertama, dan kuartil ketiga. Plot biola memberikan ringkasan serupa dari data yang tersebar ke plot kotak.
Meninjau kembali pertanyaan:Bagaimana distribusi Attack untuk setiap jenis Pokemon?
Plot kotak menunjukkan titik Serangan minimum terletak antara 0 dan 10, sedangkan maksimumnya mencapai 110.
Titik Serangan rata-rata untuk Pokemon Tipe Normal terlihat sekitar 75. Kuartil pertama dan ketiga terlihat berada di sekitar 55 dan 105.
Perencanaan Batang
Plot batang adalah anggota keluarga estimasi kategoris Seaborn yang menunjukkan nilai rata-rata atau rata-rata setiap kategori data.
Untuk membuat plot batang, jalankan sns.catplot() fungsi di Jupyter dan tentukan enam argumen:kind='bar' , data=pokemon , x='Type' , y='Attack' , dan aspect=2 , seperti yang ditunjukkan di bawah ini.
sns.catplot(kind='bar',data=pokemon,x='Type',y='Attack',aspect=2)Garis hitam pada setiap batang adalah bilah kesalahan yang mewakili ketidakpastian, seperti outlier dalam pengamatan. Seperti yang Anda lihat di bawah, nilai rata-ratanya adalah:
- Sekitar 90 untuk Pokemon tipe Air.
- Sekitar 60 untuk Rumput .
- Listrik sekitar 75.
- Batu mungkin 70.
- Tanah dalam 75.
- Dan seterusnya.
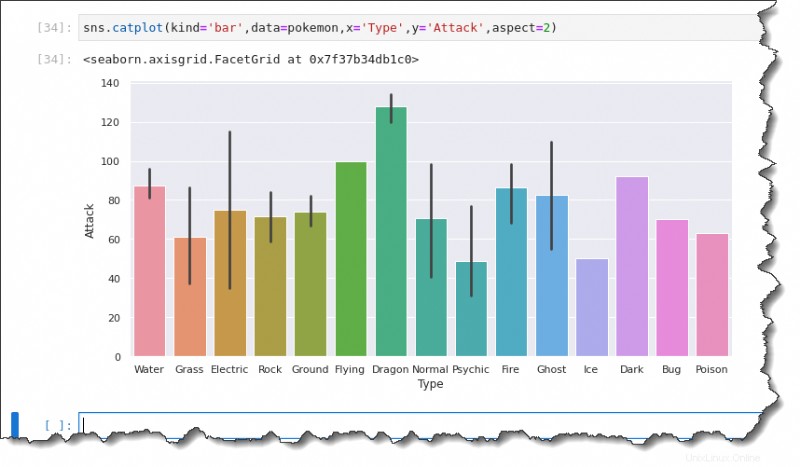
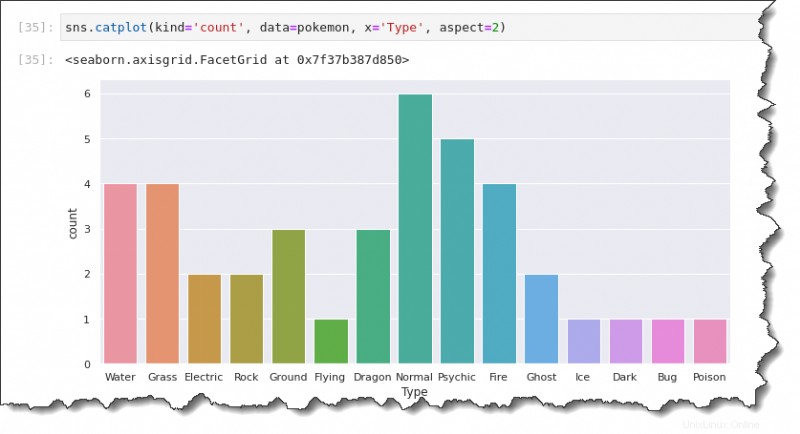
Menghitung Plot
Bagaimana jika Anda ingin memplot jumlah Pokemon alih-alih data rata-rata/rata-rata? Plot hitungan akan memungkinkan Anda melakukannya dengan perpustakaan Seaborn Python.
Untuk menghasilkan plot hitungan, ganti kind nilai dengan count , seperti yang ditunjukkan pada kode di bawah ini. Berbeda dengan plot batang, plot hitungan hanya membutuhkan satu sumbu data. Bergantung pada orientasi plot yang ingin Anda buat, tentukan sumbu x atau sumbu y saja.
Perintah di bawah ini membuat plot hitungan yang menunjukkan variabel tipe pada sumbu x.
sns.catplot(kind='count', data=pokemon, x='Type', aspect=2)Anda akan memiliki plot hitungan yang terlihat seperti di bawah ini. Seperti yang Anda lihat, jenis Pokemon yang paling umum adalah:
- Biasa (6).
- Psikis (5).
- Air (4).
- Rumput (4).
- Dan seterusnya.
Kesimpulan
Dalam tutorial ini, Anda telah belajar cara membuat plot statistik secara terprogram dengan library Seaborn Python. Metode plot mana yang menurut Anda paling sesuai untuk kumpulan data Anda?
Sekarang setelah Anda mengerjakan contoh dan berlatih membuat plot dengan Seaborn, mengapa tidak mulai mengerjakan plot baru sendiri. Mungkin Anda bisa mulai dengan dataset Iris atau mengumpulkan data sampel Anda?
Dan saat Anda melakukannya, cobalah beberapa template bawaan Seaborn dan palet warna juga! Terima kasih telah membaca, dan selamat bersenang-senang!