Scrapy adalah kerangka kerja open source yang dikembangkan dengan Python yang memungkinkan Anda membuat web spider atau crawler untuk mengekstrak informasi dari situs web dengan cepat dan mudah.
Panduan ini menunjukkan cara membuat dan menjalankan web spider dengan Scrapy di server Anda untuk mengekstrak informasi dari halaman web melalui penggunaan teknik yang berbeda.
Pertama, sambungkan ke server Anda melalui koneksi SSH. Jika Anda belum melakukannya, ikuti panduan kami disarankan untuk terhubung secara aman dengan SSH. Untuk server lokal, lanjutkan ke langkah berikutnya dan buka terminal server Anda.
Membuat lingkungan virtual
Sebelum memulai instalasi yang sebenarnya, lanjutkan dengan memperbarui paket sistem:
$ sudo apt-get updateLanjutkan dengan menginstal beberapa dependensi yang diperlukan untuk operasi:
$ sudo apt-get install python-dev python-pip libxml2-dev zlib1g-dev libxslt1-dev libffi-dev libssl-devSetelah penginstalan selesai, Anda dapat mulai mengonfigurasi virtualenv, paket Python yang memungkinkan Anda menginstal paket Python secara terpisah, tanpa mengorbankan perangkat lunak lain. Meskipun bersifat opsional, langkah ini sangat direkomendasikan oleh pengembang Scrapy:
$ sudo pip install virtualenvKemudian, siapkan direktori untuk menginstal lingkungan Scrapy:
$ sudo mkdir /var/scrapy
$ cd /var/scrapyDan inisialisasi lingkungan virtual:
$ sudo virtualenv /var/scrapy
New python executable in /var/scrapy/bin/python
Installing setuptools, pip, wheel...
done.Untuk mengaktifkan lingkungan virtual, jalankan saja perintah berikut:
$ sudo source /var/scrapy/bin/activateAnda dapat keluar kapan saja melalui perintah "nonaktifkan".
Pemasangan Scrapy
Sekarang, instal Scrapy dan buat proyek baru:
$ sudo pip install Scrapy
$ sudo scrapy startproject example
$ cd exampleDalam direktori proyek yang baru dibuat, file akan memiliki struktur berikut:
example/
scrapy.cfg # configuration file
example/ # module of python project
__init__.py
items.py
middlewares.py
pipelines.py
settings.py # project settings
spiders/
__init__.pyMenggunakan shell untuk tujuan pengujian
Scrapy memungkinkan Anda mengunduh konten HTML halaman web dan mengekstrapolasi informasi darinya melalui penggunaan berbagai teknik, seperti pemilih css. Untuk memfasilitasi proses ini, Scrapy menyediakan "shell" untuk menguji ekstraksi informasi secara real time.
Dalam tutorial ini, Anda akan melihat cara menangkap postingan pertama di halaman utama Reddit sosial yang terkenal:
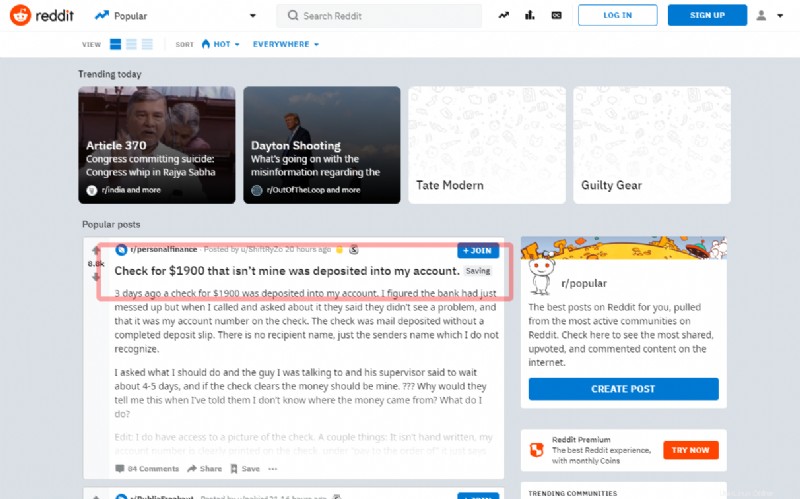
Sebelum melanjutkan ke penulisan sumber, coba ekstrak judul melalui shell:
$ sudo scrapy shell "reddit.com"Dalam beberapa detik, Scrapy akan mengunduh halaman utama. Jadi, masukkan perintah menggunakan objek 'respons'. Seperti, pada contoh berikut, gunakan pemilih "artikel h3 ::teks":, untuk mendapatkan judul posting pertama
>>> response.css('article h3::text')[0].get()Jika pemilih berfungsi dengan baik, judul akan ditampilkan. Kemudian, keluar dari shell:
>>> exit()Untuk membuat spider baru, buat file Python baru di direktori proyek contoh / spiders / reddit.py:
import scrapy
class RedditSpider(scrapy.Spider):
name = "reddit"
def start_requests(self):
yield scrapy.Request(url="https://www.reddit.com/", callback=self.parseHome)
def parseHome(self, response):
headline = response.css('article h3::text')[0].get()
with open( 'popular.list', 'ab' ) as popular_file:
popular_file.write( headline + "\n" )Semua spider mewarisi kelas Spider dari modul Scrapy dan memulai permintaan dengan menggunakan metode start_requests:
yield scrapy.Request(url="https://www.reddit.com/", callback=self.parseHome)Saat Scrapy selesai memuat halaman, Scrapy akan memanggil fungsi callback (self.parseHome).
Memiliki objek respon, konten yang anda minati dapat diambil :
headline = response.css('article h3::text')[0].get()Dan, untuk tujuan demonstrasi, simpan dalam file "popular.list".
Mulai spider yang baru dibuat menggunakan perintah:
$ sudo scrapy crawl redditSetelah selesai, judul yang terakhir diekstrak akan ditemukan di file popular.list:
$ cat popular.listMenjadwalkan Scrapyd
Untuk menjadwalkan eksekusi spider Anda, gunakan layanan yang ditawarkan oleh Scrapy "Scrapy Cloud" (lihat https://scrapinghub.com/scrapy-cloud ) atau instal daemon open source langsung di server Anda .
Pastikan Anda berada di lingkungan virtual yang dibuat sebelumnya dan instal paket scrapyd melalui pip:
$ cd /var/scrapy/
$ sudo source /var/scrapy/bin/activate
$ sudo pip install scrapydSetelah instalasi selesai, siapkan layanan dengan membuat file /etc/systemd/system/scrapyd.service dengan konten berikut:
[Unit]
Description=Scrapy Daemon
[Service]
ExecStart=/var/scrapy/bin/scrapydSimpan file yang baru dibuat dan mulai layanan melalui:
$ sudo systemctl start scrapydSekarang, daemon telah dikonfigurasi dan siap menerima spider baru.
Untuk menyebarkan contoh laba-laba Anda, Anda perlu menggunakan alat, yang disebut 'scrapyd-client', yang disediakan oleh Scrapy. Lanjutkan dengan instalasi melalui pip:
$ sudo pip install scrapyd-clientLanjutkan dengan mengedit file scrapy.cfg dan menyetel data penerapan:
[settings]
default = example.settings
[deploy]
url = http://localhost:6800/
project = exampleSekarang, terapkan hanya dengan menjalankan perintah:
$ sudo scrapyd-deployUntuk menjadwalkan eksekusi spider, panggil saja scrapyd API:
$ sudo curl http://localhost:6800/schedule.json -d project=example -d spider=reddit