Jika Anda mencari platform analisis data waktu nyata, menurut Jack Wallen Apache Druid sulit dikalahkan. Cari tahu cara mengaktifkan dan menjalankan alat ini, lalu cara memuat data sampel.
Apache Druid adalah database analitik real-time yang dirancang untuk menyalakan analitik irisan dan dadu cepat pada kumpulan data yang sangat besar. Anda dapat dengan mudah menjalankan Apache Druid dari Linux versi desktop – atau server Linux dengan GUI – lalu memuat data untuk mulai mengurai.
Apache Druid menyertakan fitur seperti:
- Penyimpanan berorientasi kolom
- Indeks penelusuran asli
- Streaming dan penyerapan batch
- Skema fleksibel
- Pembagian waktu yang dioptimalkan
- dukungan SQL
- Skalabilitas horizontal
- Pengoperasian yang mudah
Apache Druid adalah opsi bagus untuk kasus penggunaan yang memerlukan penyerapan waktu nyata, kueri cepat, dan waktu aktif tinggi.
Saya akan memandu Anda melalui proses menjalankan Apache Druid di Pop!_OS Linux (meskipun dapat dijalankan di semua distribusi Linux) dan kemudian menunjukkan cara memuat data sampel.
Yang Anda perlukan
Satu-satunya hal yang Anda perlukan untuk membuat ini berfungsi adalah menjalankan instance Linux lengkap dengan lingkungan desktop dan pengguna dengan hak sudo.
Itu dia. Mari kita buat keajaiban database.
Cara menginstal Java 8
Saat ini Apache Druid hanya mendukung Java 8, jadi kami harus memastikan bahwa itu terinstal dan ditetapkan sebagai default. Untuk menginstal Java 8 pada distribusi desktop berbasis Ubuntu, masuk ke mesin, buka jendela terminal, dan jalankan perintah:
sudo apt install openjdk-8-jdk -y
Setelah instalasi selesai, Anda perlu mengatur Java 8 sebagai default. Lakukan dengan perintah:
sudo update-alternatives --config java
Anda akan melihat daftar semua versi Java yang saat ini diinstal pada mesin. Pastikan untuk memilih nomor yang sesuai dengan Java 8.
Sepatah kata tentang layanan Apache Druid
Apa yang akan kami luncurkan adalah instance mikro Apache Druid, yang membutuhkan 4 CPU dan RAM 16GB. Ada 6 konfigurasi layanan yang berbeda untuk Apache Druid, yaitu:
- Nano-Quickstart:1 CPU, RAM 4 GB
- Mikro-Quickstart:4 CPU, RAM 16GB
- Kecil:8 CPU, 64GB RAM
- Sedang:16 CPU, 128GB RAM
- Besar:32 CPU, 256GB RAM
- X-Large:64 CPU, 512GB RAM
Tergantung besar kecilnya data dan kebutuhan Anda. Saat Anda masuk ke kumpulan besar data, disarankan agar Apache Druid digunakan sebagai sebuah cluster. Namun, karena kami baru saja memperkenalkan Apache Druid, instance mikro akan baik-baik saja.
Cakupan pengembang yang harus dibaca
Cara mengunduh dan membongkar Apache Druid
Dengan Java terinstal, saatnya untuk mengunduh dan membongkar Apache Druid. Kembali ke jendela terminal, unduh versi terbaru (pastikan untuk memeriksa halaman unduhan Apache Druid untuk memverifikasi ini adalah rilis terbaru) dengan perintah:
wget https://dlcdn.apache.org/druid/0.22.1/apache-druid-0.22.1-bin.tar.gz
Buka paket file yang diunduh dengan:
tar xvfz apache-druid-0.22.1-bin.tar.gz
Ubah ke direktori yang baru dibuat dengan:
cd apache-druid-0.22.1
Mulai layanan dengan:
./bin/start-micro-quickstart
Layanan Apache Druid akan diluncurkan tanpa masalah. Perhatikan, bahwa Anda tidak akan mendapatkan kembali terminal Anda saat layanan berjalan sampai Anda membatalkannya dengan CTRL + C.
Cara mengakses konsol Apache Druid
Pada mesin yang sama yang menjalankan Apache Druid, buka browser web dan arahkan ke http://localhost:8888 . Sayangnya, Apache Druid diatur sedemikian rupa sehingga Anda tidak dapat menjangkaunya dari mesin jarak jauh, itulah sebabnya kami menginstalnya di mesin desktop.
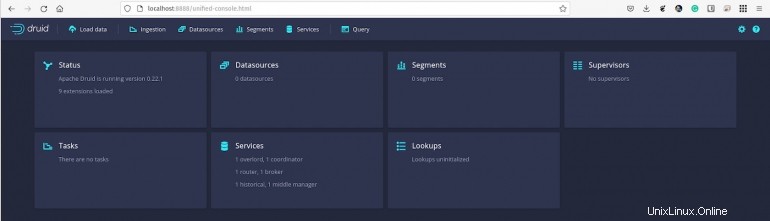
Konsol Apache Druid akan menyambut Anda (Gambar A ).
Gambar A
Cara memuat data
Kami akan memuat sampel data yang telah ditentukan sebelumnya, ditemukan di direktori mulai cepat/tutorial/. Sampelnya disebut wikiticker-2015-09-12-sampled.json.gz.
Gambar B
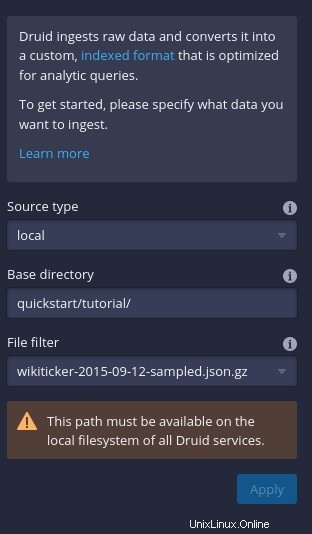
Klik Hubungkan Data (di sisi kanan jendela) lalu, di bilah sisi yang dihasilkan (Gambar C ), ketik quickstart/tutorial sebagai direktori dasar dan wikiticker-2015-09-12-sampled.json.gz di bagian Filter File.
Gambar C
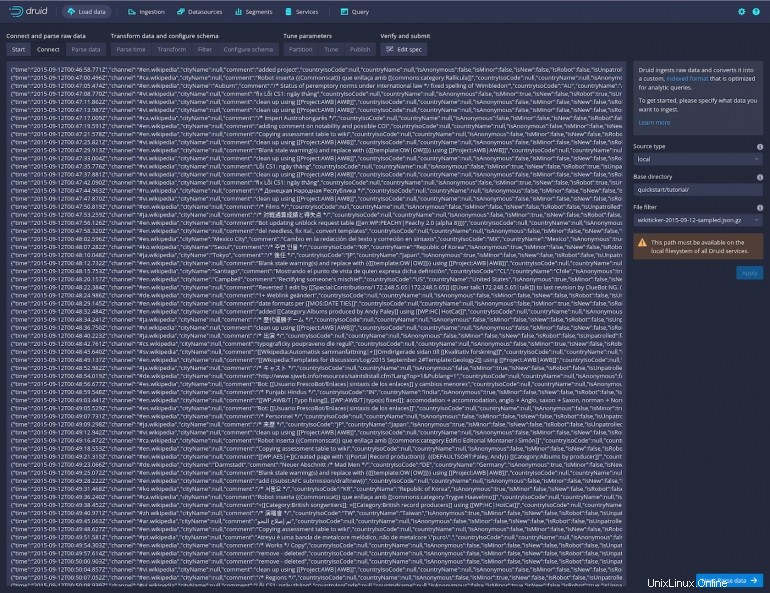
Klik Terapkan dan Anda akan melihat sejumlah besar data muncul di jendela utama (Gambar D ).
Gambar D
Klik Berikutnya:Parse Data di kanan bawah dan Anda akan disajikan daftar data dalam format yang lebih mudah dibaca (Gambar E ).
Gambar E
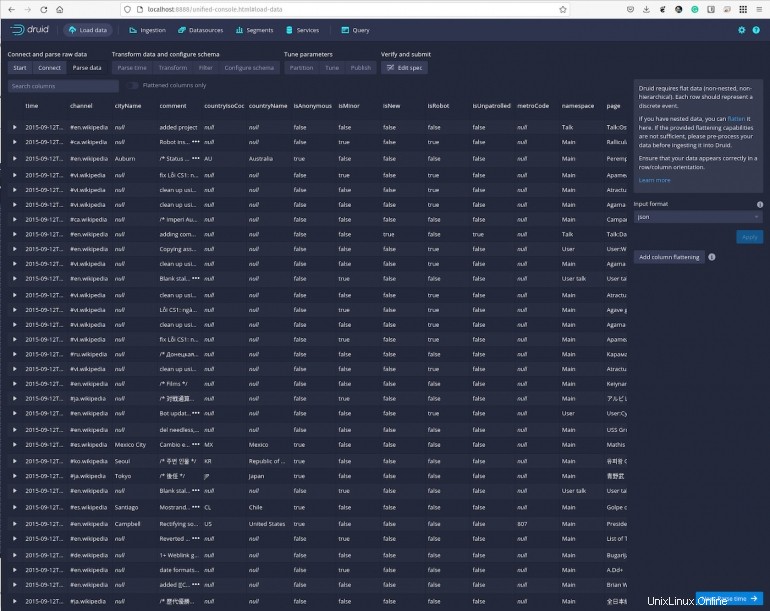
Klik Berikutnya:Parse Time dan Anda dapat melihat data berdasarkan stempel waktu tertentu (Gambar F ).
Gambar F
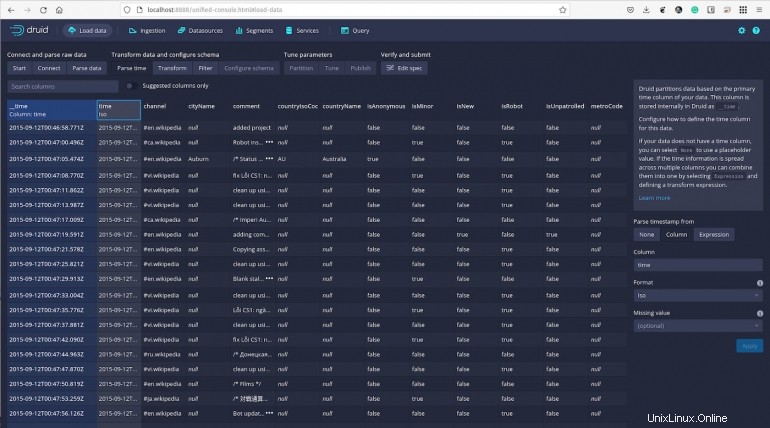
Klik Berikutnya:Transform dan Anda kemudian dapat melakukan transformasi per baris dari nilai kolom untuk membuat kolom baru atau mengubah yang sudah ada.
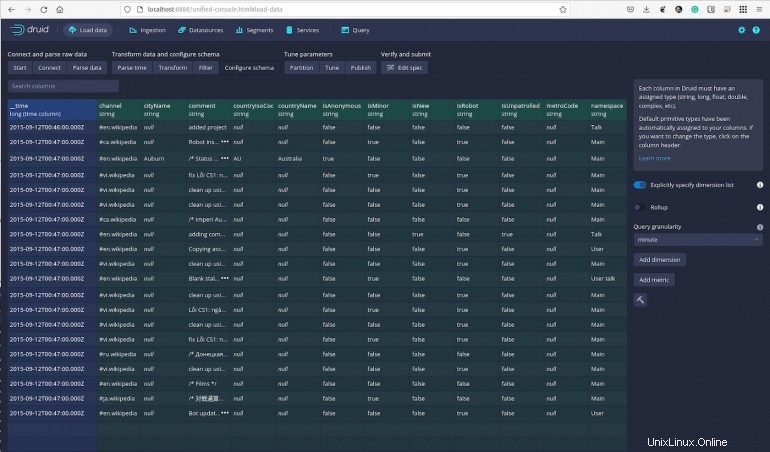
Terus mengeklik data dan, kapan pun, Anda dapat menjalankan kueri dan memfilter data sesuai kebutuhan. Di bagian Konfigurasi Skema (Gambar G ), Anda bahkan dapat menentukan perincian kueri serta menambahkan dimensi dan metrik.
Gambar G
Dan itulah dasar-dasar Apache Druid. Meskipun kami hanya melihat sekilas tentang apa yang dapat dilakukan oleh platform analisis data yang kuat ini, Anda seharusnya dapat memahami cara kerjanya dengan bermain-main dengan data sampel.
Setelah selesai bekerja, pastikan untuk kembali ke jendela terminal dan hentikan layanan Apache Druid dengan CTRL + C.