Beberapa perusahaan tidak mengizinkan layanan mereka dihentikan. Jika server padam, operator seluler mungkin mengalami downtime sistem penagihan yang menyebabkan kehilangan koneksi untuk semua kliennya. Penerimaan dampak potensial dari situasi seperti itu mengarah pada gagasan untuk selalu memiliki rencana B.
Dalam artikel ini kami menyoroti berbagai cara perlindungan terhadap kegagalan server, serta arsitektur yang digunakan untuk penerapan VMmanager Cloud, panel kontrol untuk membangun cluster Ketersediaan Tinggi.

Kata Pengantar
Terminologi di bidang toleransi cluster berbeda dari situs web ke situs web. Untuk menghindari pencampuran istilah dan definisi yang berbeda, mari kita uraikan istilah dan definisi yang akan digunakan dalam artikel yang diberikan:
- Fault Tolerance (FT) adalah kemampuan sistem untuk melanjutkan operasinya setelah kegagalan salah satu komponennya.
- Cluster adalah sekelompok server (cluster node) yang terhubung melalui saluran komunikasi.
- Fault Tolerant Cluster (FTC) adalah cluster di mana kegagalan satu server tidak mengakibatkan seluruh cluster tidak tersedia sepenuhnya. Fungsi dari node yang gagal secara otomatis dipindahkan di antara node yang tersisa.
- Continuous Availability (CA) berarti bahwa pengguna dapat menggunakan layanan tanpa mengalami waktu tunggu. Tidak peduli sudah berapa lama sejak node gagal.
- Ketersediaan Tinggi (HA) berarti bahwa pengguna mungkin mengalami waktu tunggu layanan jika salah satu node mati; namun, sistem akan dipulihkan secara otomatis dengan waktu henti minimum.
- Cluster CA adalah cluster Continuous Availability.
- cluster HA adalah cluster Ketersediaan Tinggi.
Biarkan diperlukan untuk menyebarkan cluster yang terdiri dari 10 node dengan mesin virtual yang berjalan di setiap node. Tujuannya adalah untuk melindungi mesin virtual setelah kegagalan server. Server CPU ganda digunakan untuk memaksimalkan penghitungan kepadatan rak.
Pada awalnya, opsi paling menarik bagi perusahaan adalah menerapkan klaster Ketersediaan Berkelanjutan saat layanan masih disediakan setelah peralatan gagal. Memang, Ketersediaan Berkelanjutan adalah suatu keharusan jika Anda perlu mempertahankan pengoperasian sistem penagihan atau mengotomatiskan proses produksi yang berkelanjutan. Namun, pendekatan ini juga memiliki jebakan dan jebakan yang dibahas di bawah ini.
Ketersediaan Berkelanjutan
Kontinuitas layanan hanya layak jika salinan yang tepat dari mesin fisik atau virtual dengan layanan ini dibuat, yang tersedia pada waktu tertentu. Model redundansi seperti itu disebut 2N. Membuat salinan server setelah peralatan gagal akan memakan waktu, menyebabkan waktu layanan habis. Lebih jauh lagi, dalam hal ini, dump RAM tidak dapat diambil dari server yang gagal, yang berarti semua informasi yang ada di sana akan hilang.
Ada dua metode yang digunakan untuk menyediakan CA:pada perangkat keras dan lapisan perangkat lunak. Mari kita fokus pada masing-masing secara lebih rinci.
Metode perangkat keras mewakili server ganda di mana semua komponen diduplikasi dan perhitungan dijalankan secara bersamaan dan independen. Sinkronisasi dicapai dengan menggunakan node khusus yang memeriksa hasil yang berasal dari kedua bagian. Jika node mendeteksi ketidaksesuaian, node mencoba untuk mendefinisikan masalah dan memperbaiki kesalahan. Jika kesalahan tidak dapat diperbaiki, sistem akan menonaktifkan modul yang gagal.
Stratus, produsen server CA, menjamin bahwa waktu henti sistem secara keseluruhan tidak melebihi 32 detik per tahun. Hasil tersebut dapat dicapai dengan menggunakan peralatan khusus. Menurut perwakilan Stratus, biaya satu server CA dengan CPU ganda untuk setiap modul yang disinkronkan adalah sekitar $160.000 tergantung pada spesifikasinya. Harga yang diperpanjang untuk seluruh klaster CA dalam kasus ini adalah $1600.000.
Metode perangkat lunak
Alat perangkat lunak paling populer untuk penyebaran klaster Ketersediaan Berkelanjutan pada saat artikel ini dibuat adalah VMware vSphere. Teknologi Continuous Availability dari produk ini disebut Fault Tolerance.
Berbeda dengan metode perangkat keras, teknologi ini memiliki persyaratan tertentu, seperti berikut:
- CPU pada host fisik:
- Intel dengan arsitektur Sandy Bridge (atau yang lebih baru). Avoton tidak didukung.
- Bulldozer AMD (atau yang lebih baru).
- Mesin dengan Toleransi Kesalahan harus disambungkan ke satu jaringan 10 Gb dengan latensi rendah. VMware sangat merekomendasikan penggunaan jaringan khusus.
- Tidak lebih dari 4 CPU virtual per VM.
- Tidak lebih dari 8 CPU virtual per host fisik.
- Tidak lebih dari 4 mesin virtual per host fisik.
- Snapshot mesin virtual tidak tersedia.
- VMotion penyimpanan tidak tersedia.
Daftar lengkap batasan dan ketidaksesuaian dapat ditemukan di dokumentasi resmi.
Lisensi vSphere didasarkan pada CPU fisik. Harga mulai dari $1750 per lisensi + $550 untuk langganan dan dukungan tahunan. Otomatisasi manajemen klaster juga memerlukan VMware vCenter Server yang harganya lebih dari $8000. Model 2N digunakan untuk menyediakan Ketersediaan Berkelanjutan, oleh karena itu diperlukan untuk membeli 10 server yang direplikasi dengan lisensi untuk masing-masing server untuk membangun sebuah cluster dengan 10 node dengan mesin virtual.
Biaya keseluruhan perangkat lunak adalah 2[Jumlah CPU per server]*(10[Jumlah node dengan mesin virtual]+10[Jumlah node yang direplikasi])*(1750+550)[Biaya lisensi per setiap CPU]+8000 [Biaya Server VMware vCenter]=$100.000. Semua harga dibulatkan.
Konfigurasi node tertentu tidak dijelaskan dalam artikel ini karena komponen server selalu berbeda tergantung pada tujuan cluster. Peralatan jaringan juga tidak dijelaskan karena harus identik dalam setiap kasus. Artikel ini berfokus pada komponen yang pasti akan bervariasi, yaitu biaya lisensi.
Penting juga untuk menyebutkan produk yang tidak lagi dikembangkan dan didukung.
Produk yang disebut Remus didasarkan pada virtualisasi Xen. Ini adalah solusi open source gratis yang memanfaatkan teknologi snapshot mikro. Sayangnya dokumentasinya belum diperbarui untuk waktu yang lama:Panduan instalasi memberikan instruksi untuk Ubuntu 12.10 yang akhir masa pakainya diumumkan pada tahun 2014. Bahkan pencarian Google tidak menemukan perusahaan yang menggunakan Remus untuk operasi mereka.
Upaya telah dilakukan untuk memodifikasi QEMU untuk membangun cluster Continuous Availability pada teknologi ini. Ada dua proyek yang mengumumkan pekerjaan mereka ke arah ini.
Yang pertama adalah Kemari, produk open source yang dipimpin oleh Yoshiaki Tamura. Proyek ini dimaksudkan untuk menggunakan migrasi QEMU langsung. Komitmen terakhir dibuat pada Februari 2011, yang menunjukkan bahwa pembangunan menemui jalan buntu dan tidak akan dilanjutkan.
Produk kedua adalah Micro Checkpointing, sebuah proyek open source yang didirikan oleh Michael Hines. Tidak ada aktivitas yang ditemukan di changelognya selama setahun terakhir, yang menyerupai proyek Kemari.
Fakta-fakta ini memungkinkan kami membuat kesimpulan bahwa hingga saat ini tidak ada kemungkinan untuk Ketersediaan Berkelanjutan pada virtualisasi KVM.
Terlepas dari semua keunggulan sistem Continuous Availability, ada banyak hambatan dalam penerapan dan pengoperasian solusi tersebut. Namun demikian, dalam beberapa kasus Toleransi Kesalahan mungkin diperlukan tetapi tanpa keharusan untuk terus tersedia. Skenario semacam itu memungkinkan penggunaan kluster dengan Ketersediaan Tinggi.
Ketersediaan Tinggi
Cluster High Availability memberikan Fault Tolerance dengan secara otomatis mendeteksi jika perangkat keras mati dan selanjutnya meluncurkan layanan pada node yang tersedia.
Ketersediaan Tinggi tidak mendukung sinkronisasi CPU yang diluncurkan pada node dan tidak selalu memungkinkan untuk menyinkronkan disk lokal. Dengan mengingat hal ini, disarankan untuk menempatkan drive yang digunakan oleh node dalam penyimpanan independen yang terpisah seperti penyimpanan jaringan.
Alasannya jelas:Node tidak dapat dijangkau setelah kegagalannya, dan informasi dari perangkat penyimpanannya tidak dapat diambil. Sistem penyimpanan data juga harus toleran terhadap kesalahan, jika tidak, tidak ada kemungkinan untuk Ketersediaan Tinggi. Akibatnya, cluster Ketersediaan Tinggi terdiri dari dua sub-cluster:
- Kluster komputasi yang terdiri dari node dengan mesin virtual
- Kluster penyimpanan dengan disk yang digunakan oleh node komputasi.
Saat ini ada solusi berikut yang digunakan untuk mengimplementasikan cluster Ketersediaan Tinggi dengan mesin virtual pada node cluster:
- Detak jantung, versi 1.? dengan DRBD;
- Alat pacu jantung;
- VMware vSphere;
- Proxmox VE;
- XenServer;
- OpenStack;
- oVirt;
- Virtualisasi Red Hat Enterprise;
- Pengelompokan Failover Server Windows dengan peran server Hyper-V;
- VMmanager Cloud.
Mari kita lihat lebih dekat VMmanager Cloud.
VMmanager Cloud
VMmanager Cloud adalah produk yang memungkinkan penerapan cluster Ketersediaan Tinggi dan menggunakan virtualisasi QEMU-KVM. Teknologi ini dipilih karena secara aktif dikembangkan dan didukung dan memungkinkan untuk menginstal sistem operasi apa pun pada mesin virtual. Produk menggunakan Corosync untuk mendeteksi ketersediaan cluster. Jika salah satu server mati, VMmanager mendistribusikan mesin virtualnya di antara node yang tersisa satu per satu.
Dalam bentuk yang disederhanakan, mekanisme ini bekerja sebagai berikut:
- Sistem mengidentifikasi node cluster dengan jumlah mesin virtual terendah.
- Ini memeriksa apakah ada cukup RAM untuk menemukan mesin.
- Jika ada cukup memori pada sebuah node untuk mesin yang bersangkutan, VMmanager membuat mesin virtual baru pada node ini.
- Jika tidak ada cukup memori, sistem akan memeriksa node lain dengan lebih banyak mesin virtual.
Menguji beberapa konfigurasi perangkat keras dan pertanyaan dari banyak pengguna VMmanager Cloud saat ini mengidentifikasi bahwa biasanya diperlukan waktu 45-90 detik untuk mendistribusikan dan memulihkan operasi semua VM dari node yang gagal, bergantung pada kinerja peralatan.
Direkomendasikan untuk mendedikasikan satu atau beberapa node sebagai perlindungan terhadap situasi darurat dan tidak menerapkan VM pada node ini selama operasi rutin. Ini meminimalkan kemungkinan kekurangan sumber daya pada node cluster langsung untuk menambahkan mesin virtual dari node yang gagal. Jika hanya satu node cadangan yang digunakan, model keamanan tersebut disebut N+1.
VMmanager Cloud mendukung jenis penyimpanan berikut:sistem file, LVM, Jaringan LVM, iSCSI dan Ceph [khususnya RBD (RADOS Block Device), salah satu implementasi Ceph]. Tiga yang terakhir digunakan untuk Ketersediaan Tinggi.
Satu lisensi seumur hidup untuk sepuluh node operasional dan satu node cadangan berharga €3520, atau $3865 hingga saat ini (satu lisensi berharga €320 per node terlepas dari nomor CPU). Lisensi mencakup pembaruan gratis selama satu tahun; mulai dari tahun kedua, pembaruan disediakan per model langganan dengan harga €880 per tahun untuk seluruh cluster.
Mari kita periksa bagaimana VMmanager Cloud telah digunakan untuk penerapan cluster Ketersediaan Tinggi.
Byte Pertama
FirstByte mulai menyediakan hosting cloud pada Februari 2016. Awalnya cluster mereka dibuat di OpenStack; namun kurangnya spesialis untuk sistem ini baik dari segi ketersediaan dan biaya mendorong mereka untuk mencari solusi alternatif. Sistem baru untuk membangun cluster Ketersediaan Tinggi harus memenuhi persyaratan berikut:
- Kemampuan untuk menerapkan mesin virtual KVM.
- Integrasi dengan Ceph.
- Integrasi dengan sistem penagihan untuk menawarkan layanan yang ada.
- Biaya lisensi terjangkau.
- Dukungan dari pengembang perangkat lunak.
VMmanager Cloud memenuhi semua persyaratan.
Fitur khas cluster FirstByte:
- Transfer data didasarkan pada teknologi Ethernet dan peralatan Cisco.
- Perutean dilakukan dengan menggunakan Cisco ASR9001. Cluster ini menggunakan sekitar 50000 alamat IPv6.
- Kecepatan tautan antara node komputasi dan sakelar adalah 10 Gbps.
- Kecepatan transfer data antara sakelar dan node penyimpanan adalah 20 Gbps, dengan dua saluran gabungan pada masing-masing 10 Gbps.
- Tautan terpisah 20 Gbps digunakan antara rak dengan node penyimpanan untuk replikasi.
- Disk SAS yang dikombinasikan dengan SSD dipasang di semua node penyimpanan.
- Jenis penyimpanan adalah RBD.
Tata letak sistem disajikan di bawah ini:
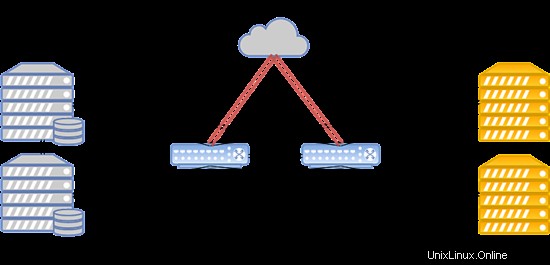
Konfigurasi tersebut berfungsi untuk menghosting situs web populer, server game, dan database dengan beban di atas rata-rata.
VDS Pertama
FirstVDS menyediakan layanan cluster toleransi kesalahan yang dimulai pada September 2015.
VMmanager Cloud dipilih untuk cluster ini karena faktor berikut:
- Pengalaman yang solid dalam menggunakan panel kontrol sistem ISP.
- Integrasi dengan BILLmanager per default.
- Dukungan teknis berkualitas tinggi.
- Integrasi dengan Ceph.
Cluster mereka memiliki fitur berikut:
- Transfer data didasarkan pada jaringan Infiniband dengan kecepatan koneksi 56 Gbps;
- Jaringan Infiniband dibangun di atas peralatan Mellanox;
- Node penyimpanan memiliki drive SSD;
- Jenis penyimpanan adalah RBD.
Sistem dapat ditata dengan cara berikut:
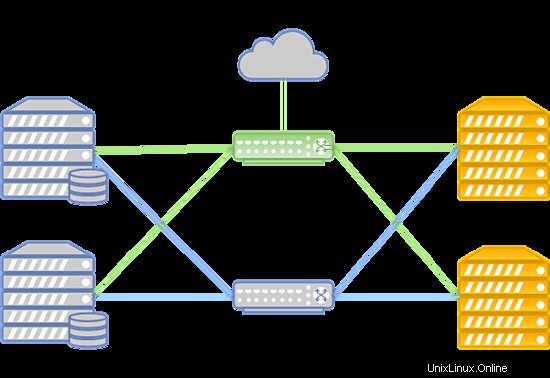
Jika terjadi kegagalan jaringan Infiniband, koneksi antara penyimpanan disk VM dan server komputasi dibuat melalui jaringan Ethernet yang digunakan pada peralatan Juniper. Koneksi baru diatur secara otomatis.
Karena komunikasi berkecepatan tinggi dengan penyimpanan, cluster ini berfungsi sempurna untuk menghosting situs web dengan lalu lintas sangat tinggi, streaming video dan konten, serta data besar.
Kesimpulan
Mari kita simpulkan temuan utama dari artikel tersebut.
Kluster Continuous Availability adalah suatu keharusan ketika setiap detik waktu henti membawa kerugian besar. Jika dibiarkan mati selama 5 menit saat mesin virtual sedang digunakan pada node cadangan, cluster Ketersediaan Tinggi dapat menjadi opsi yang baik untuk mengurangi biaya perangkat keras dan perangkat lunak.
Penting juga untuk diingatkan bahwa satu-satunya cara untuk mencapai Toleransi Kesalahan adalah secara berlebihan. Pastikan untuk mereplikasi server Anda, peralatan dan tautan komunikasi data, saluran akses Internet, dan daya. Replikasi semua yang Anda bisa. Langkah-langkah tersebut memungkinkan untuk menghilangkan kemacetan dan titik kegagalan potensial yang dapat menyebabkan downtime dari keseluruhan sistem. Dengan mengambil langkah-langkah di atas, Anda dapat yakin bahwa Anda memiliki cluster yang toleran terhadap kesalahan yang tahan terhadap kegagalan.
Jika menurut Anda model Ketersediaan Tinggi sesuai dengan kebutuhan Anda dan VMmanager Cloud adalah alat yang baik untuk mewujudkannya, lihat panduan penginstalan dan dokumentasi untuk mempelajari sistem lebih lanjut. saya semoga operasi Anda bebas kegagalan dan berkelanjutan!