Saya bekerja paruh waktu sebagai auditor data. Pikirkan saya sebagai korektor yang bekerja dengan tabel data daripada halaman prosa. Tabel diekspor dari database relasional dan biasanya berukuran cukup sederhana:100.000 hingga 1.000.000 catatan dan 50 hingga 200 bidang.
Saya belum pernah melihat tabel data bebas kesalahan. Kekacauan tidak terbatas, seperti yang mungkin Anda pikirkan, untuk menduplikasi catatan, kesalahan ejaan dan pemformatan, dan item data yang ditempatkan di bidang yang salah. Saya juga menemukan:
- rekaman rusak tersebar di beberapa baris karena item data telah menyematkan jeda baris
- item data dalam satu bidang tidak sesuai dengan item data di bidang lain, dalam catatan yang sama
- rekaman dengan item data terpotong, seringkali karena string yang sangat panjang dimasukkan ke dalam bidang dengan batas 50 atau 100 karakter
- kegagalan penyandian karakter yang menghasilkan omong kosong yang dikenal sebagai mojibake
- karakter kontrol yang tidak terlihat, beberapa di antaranya dapat menyebabkan kesalahan pemrosesan data
- karakter pengganti dan tanda tanya misterius yang disisipkan oleh program terakhir yang gagal memahami pengkodean karakter data
Membersihkan masalah ini tidak sulit, tetapi ada hambatan non-teknis untuk menemukannya. Yang pertama adalah keengganan alami setiap orang untuk menangani kesalahan data. Sebelum saya melihat tabel, pemilik atau pengelola data mungkin telah melalui kelima tahap Duka Data:
- Tidak ada kesalahan dalam data kami.
- Yah, mungkin ada beberapa kesalahan, tapi itu tidak terlalu penting.
- Oke, ada banyak kesalahan; kami akan meminta orang-orang internal kami untuk menangani mereka.
- Kami telah mulai memperbaiki beberapa kesalahan, tetapi ini memakan waktu; kami akan melakukannya saat kami bermigrasi ke perangkat lunak database baru.
- Kami tidak punya waktu untuk membersihkan data saat pindah ke database baru; kita bisa menggunakan bantuan.
Sikap pemblokiran kemajuan kedua adalah keyakinan bahwa pembersihan data memerlukan aplikasi khusus—baik program berpemilik yang mahal atau program open source OpenRefine yang luar biasa. Untuk mengatasi masalah yang tidak dapat diselesaikan oleh aplikasi khusus, pengelola data mungkin meminta bantuan programmer—seseorang yang mahir menggunakan Python atau R.
Tetapi audit dan pembersihan data umumnya tidak memerlukan aplikasi khusus. Tabel data teks biasa telah ada selama beberapa dekade, dan begitu juga alat pemrosesan teks. Buka shell Bash dan Anda memiliki kotak alat yang dimuat dengan prosesor teks yang kuat seperti grep , cut , paste , sort , uniq , tr , dan awk . Mereka cepat, andal, dan mudah digunakan.
Saya melakukan semua audit data saya di baris perintah, dan saya telah menempatkan banyak trik audit data saya di situs web "buku masak". Operasi yang saya lakukan secara teratur disimpan sebagai fungsi dan skrip shell (lihat contoh di bawah).
Ya, pendekatan baris perintah mengharuskan data yang akan diaudit telah diekspor dari database. Dan ya, hasil audit perlu diedit nanti dalam database, atau (database memungkinkan) item data yang dibersihkan perlu diimpor sebagai pengganti yang berantakan.
Tapi kelebihannya luar biasa. awk akan memproses beberapa juta catatan dalam hitungan detik di desktop atau laptop kelas konsumen. Ekspresi reguler yang tidak rumit akan menemukan semua kesalahan data yang dapat Anda bayangkan. Dan semua ini akan terjadi dengan aman di luar struktur basis data:Audit baris perintah tidak dapat memengaruhi basis data, karena ia bekerja dengan data yang dibebaskan dari penjara basis datanya.
Pembaca yang dilatih di Unix akan tersenyum puas pada saat ini. Mereka ingat memanipulasi data pada baris perintah bertahun-tahun yang lalu hanya dengan cara ini. Apa yang terjadi sejak itu adalah bahwa kekuatan pemrosesan dan RAM telah meningkat secara spektakuler, dan alat baris perintah standar telah dibuat jauh lebih efisien. Audit data tidak pernah secepat atau semudah ini. Dan sekarang Microsoft Windows 10 dapat menjalankan program Bash dan GNU/Linux, pengguna Windows dapat menghargai moto Unix dan Linux untuk menangani data yang berantakan:Tetap tenang dan buka terminal.

Contoh
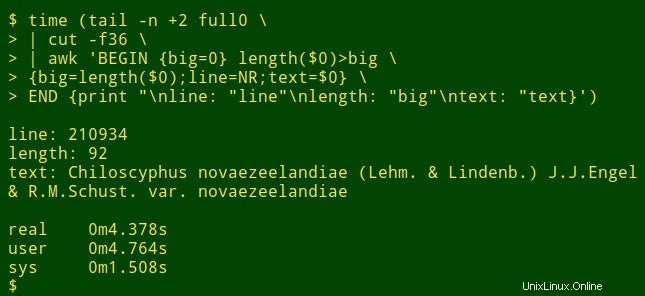
Misalkan saya ingin menemukan item data terpanjang di bidang tertentu dari tabel besar. Itu sebenarnya bukan tugas audit data, tetapi ini akan menunjukkan cara kerja alat shell. Untuk tujuan demonstrasi, saya akan menggunakan tabel yang dipisahkan tab full0 , yang memiliki 1.122.023 catatan (ditambah baris header) dan 49 bidang, dan saya akan mencari di bidang nomor 36. (Saya mendapatkan nomor bidang dengan fungsi yang dijelaskan di situs buku masak saya.)
Perintah dimulai dengan menggunakan tail untuk menghapus baris header dari full0 . Hasilnya disalurkan ke cut , yang mengekstrak bidang 36 yang dipenggal. Berikutnya dalam pipeline adalah awk . Di sini variabel big diinisialisasi ke nilai 0; lalu awk menguji panjang item data dalam catatan pertama. Jika panjangnya lebih besar dari 0, awk mengatur ulang big ke panjang baru dan menyimpan nomor baris (NR) dalam variabel line dan seluruh item data dalam variabel text . awk kemudian memproses masing-masing dari 1.122.022 catatan yang tersisa secara bergantian, mengatur ulang ketiga variabel ketika menemukan item data yang lebih panjang. Akhirnya, ia mencetak daftar nomor baris, panjang item data, dan teks lengkap dari item data terpanjang yang dipisahkan dengan rapi. (Dalam kode berikut, perintah telah dipecah untuk kejelasan menjadi beberapa baris.)
<code>tail -n +2 full0 \
> | cut -f36 \
> | awk 'BEGIN {big=0} length($0)>big \
> {big=length($0);line=NR;text=$0} \
> END {print "\nline: "line"\nlength: "big"\ntext: "text}' </code>
Berapa lama? Sekitar 4 detik di desktop saya (core i5, RAM 8GB):
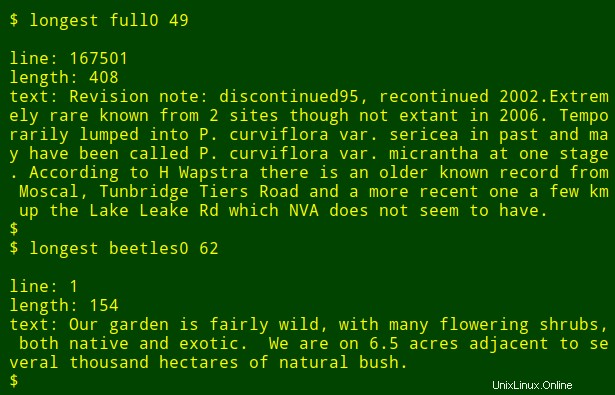
Sekarang untuk bagian yang rapi:Saya dapat memasukkan perintah panjang itu ke dalam fungsi shell, longest , yang mengambil sebagai argumennya nama file ($1) dan nomor kolom ($2) :

Saya kemudian dapat menjalankan kembali perintah sebagai suatu fungsi, menemukan item data terpanjang di bidang lain dan di file lain tanpa perlu mengingat bagaimana perintah itu ditulis:
Sebagai tweak terakhir, saya dapat menambahkan ke output nama bidang bernomor yang saya cari. Untuk melakukan ini, saya menggunakan head untuk mengekstrak baris header tabel, pipa baris itu ke tr untuk mengonversi tab ke baris baru, dan menyalurkan daftar yang dihasilkan ke tail dan head untuk mencetak $2th nama bidang pada daftar, di mana $2 adalah argumen nomor bidang. Nama field disimpan dalam variabel shell field dan diteruskan ke awk untuk dicetak sebagai awk internal internal variabel fld .
<code>longest() { field=$(head -n 1 "$1" | tr '\t' '\n' | tail -n +"$2" | head -n 1); \
tail -n +2 "$1" \
| cut -f"$2" | \
awk -v fld="$field" 'BEGIN {big=0} length($0)>big \
{big=length($0);line=NR;text=$0}
END {print "\nfield: "fld"\nline: "line"\nlength: "big"\ntext: "text}'; }</code> 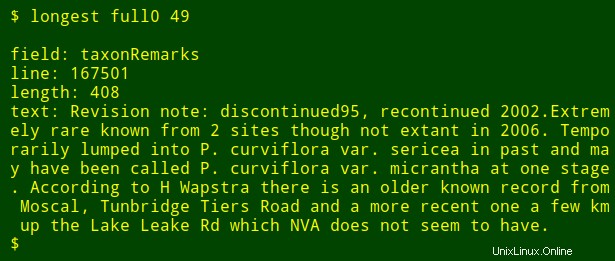
Perhatikan bahwa jika saya mencari item data terpanjang di sejumlah bidang yang berbeda, yang harus saya lakukan adalah menekan tombol Panah Atas untuk mendapatkan longest terakhir perintah, lalu mundur spasi nomor bidang dan masukkan yang baru.