Di sini kita akan melihat cara menginstal Apache Spark di Ubuntu 20.04 atau 18.04, perintah akan berlaku untuk Linux Mint, Debian dan sistem Linux serupa lainnya.
Apache Spark adalah alat pemrosesan data tujuan umum yang disebut mesin pemrosesan data. Digunakan oleh insinyur data dan ilmuwan data untuk melakukan kueri data yang sangat cepat pada sejumlah besar data dalam kisaran terabyte. Ini adalah kerangka kerja untuk perhitungan berbasis cluster yang bersaing dengan Hadoop Map / Reduce klasik dengan menggunakan RAM yang tersedia di cluster untuk eksekusi pekerjaan yang lebih cepat.
Selain itu, Spark juga menawarkan opsi untuk mengontrol data melalui SQL, memprosesnya dengan streaming (mendekati) waktu nyata, dan menyediakan basis data grafiknya sendiri dan perpustakaan pembelajaran mesin. Kerangka kerja ini menawarkan teknologi dalam memori untuk tujuan ini, yaitu dapat menyimpan kueri dan data secara langsung di memori utama node cluster.
Apache Spark sangat ideal untuk memproses data dalam jumlah besar dengan cepat. Model pemrograman Spark didasarkan pada Resilient Distributed Datasets (RDD), kelas koleksi yang beroperasi terdistribusi dalam sebuah cluster. Platform sumber terbuka ini mendukung berbagai bahasa pemrograman seperti Java, Scala, Python, dan R.
Langkah-Langkah Instalasi Apache Spark di Ubuntu 20.04
Langkah-langkah yang diberikan disini dapat digunakan untuk versi Ubuntu lainnya seperti 21.04/18.04, termasuk pada Linux Mint, Debian, dan Linux sejenis.
1. Instal Java dengan dependensi lain
Di sini kami menginstal versi Jave terbaru yang tersedia yang merupakan persyaratan Apache Spark bersama dengan beberapa hal lainnya – Git dan Scala untuk memperluas kemampuannya.
sudo apt install default-jdk scala git
2. Unduh Apache Spark di Ubuntu 20.04
Sekarang, kunjungi situs web resmi Spark dan unduh versi terbaru yang tersedia. Namun, saat menulis tutorial ini versi terbaru adalah 3.1.2. Karenanya, di sini kami mengunduh yang sama, jika berbeda saat Anda melakukan instalasi Spark di sistem Ubuntu Anda, lakukan itu. Cukup salin tautan unduh alat ini dan gunakan dengan wget atau langsung unduh di sistem Anda.
wget https://downloads.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
3. Ekstrak Spark ke /opt
Untuk memastikan kami tidak menghapus folder yang diekstrak secara tidak sengaja, mari letakkan di tempat yang aman yaitu /opt direktori.
sudo mkdir /opt/spark
sudo tar -xf spark*.tgz -C /opt/spark --strip-component 1
Juga, ubah izin folder, sehingga Spark dapat menulis di dalamnya.
sudo chmod -R 777 /opt/spark
4. Tambahkan folder Spark ke jalur sistem
Sekarang, karena kami telah memindahkan file ke /opt direktori, untuk menjalankan perintah Spark di terminal kita harus menyebutkan seluruh jalurnya setiap kali yang mengganggu. Untuk mengatasi ini, kami mengonfigurasi variabel lingkungan untuk Spark dengan menambahkan jalur rumahnya ke file profil/bashrc sistem. Ini memungkinkan kita untuk menjalankan perintahnya dari mana saja di terminal terlepas dari direktori mana kita berada.
echo "export SPARK_HOME=/opt/spark" >> ~/.bashrc echo "export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin" >> ~/.bashrc echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.bashrc
Muat ulang cangkang:
source ~/.bashrc
5. Mulai server master Apache Spark di Ubuntu
Karena kita telah mengonfigurasi lingkungan variabel untuk Spark, sekarang mari kita mulai server master mandirinya dengan menjalankan skripnya:
start-master.sh
Ubah UI Web Spark Master dan Listen Port (opsional, gunakan hanya jika diperlukan)
Jika Anda ingin menggunakan port khusus maka itu mungkin untuk digunakan, opsi atau argumen yang diberikan di bawah ini.
–pelabuhan – Port untuk layanan yang akan didengarkan (default:7077 untuk master, acak untuk pekerja)
–webui-port – Port untuk UI web (default:8080 untuk master, 8081 untuk pekerja)
Contoh – Saya ingin menjalankan Spark web UI di 8082, dan membuatnya mendengarkan port 7072 maka perintah untuk memulainya akan seperti ini:
start-master.sh --port 7072 --webui-port 8082
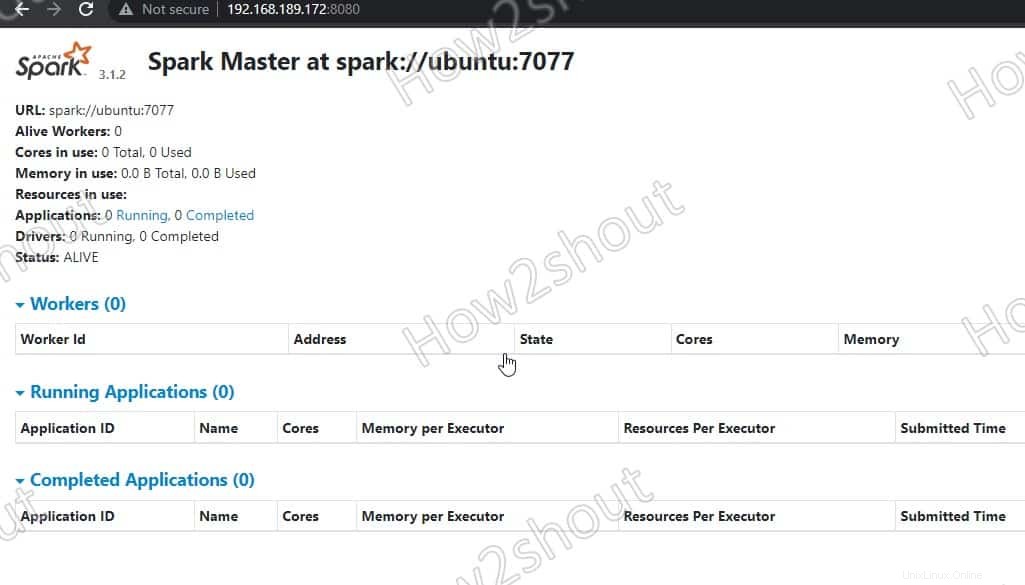
6. Akses Spark Master (spark://Ubuntu:7077) – Antarmuka web
Sekarang, mari kita akses antarmuka web server master Spark yang berjalan pada nomor port 8080 . Jadi, di browser Anda buka http://127.0.0.1:8080 .
Master kami berjalan di spark://Ubuntu :7077, di mana Ubuntu adalah sistem nama host dan bisa berbeda dalam kasus Anda.
Jika Anda menggunakan server CLI dan ingin menggunakan browser dari sistem lain yang dapat mengakses alamat IP server, untuk itu buka dulu 8080 di firewallnya. Ini akan memungkinkan Anda untuk mengakses antarmuka web Spark dari jarak jauh di – http://your-server-ip-addres:8080
sudo ufw allow 8080
7. Jalankan Skrip Pekerja Budak
Untuk menjalankan pekerja budak Spark, kita harus memulai skripnya yang tersedia di direktori yang telah kita salin di /opt . Sintaks perintahnya adalah:
Sintaks perintah:
start-worker.sh spark://hostname:port
Pada perintah di atas ubah hostname dan pelabuhan . Jika Anda tidak tahu nama host Anda, cukup ketik- hostname di terminal. Di mana port default master yang sedang berjalan adalah 7077, Anda dapat melihat pada tangkapan layar di atas .
Jadi, karena nama host kami adalah ubuntu, perintahnya akan seperti ini:
start-worker.sh spark://ubuntu:7077
Segarkan Antarmuka web dan Anda akan melihat ID Pekerja dan jumlah memori dialokasikan untuk itu:
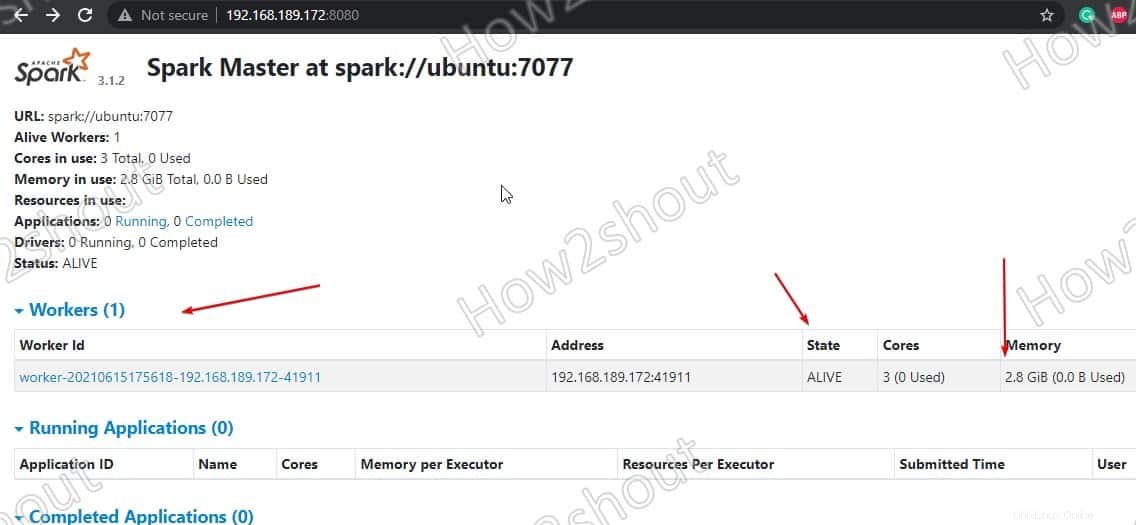
Jika mau, Anda dapat mengubah memori/ram yang dialokasikan untuk pekerja. Untuk itu, Anda harus me-restart pekerja dengan jumlah RAM yang ingin Anda berikan.
stop-worker.sh start-worker.sh -m 212M spark://ubuntu:7077
Gunakan Spark Shell
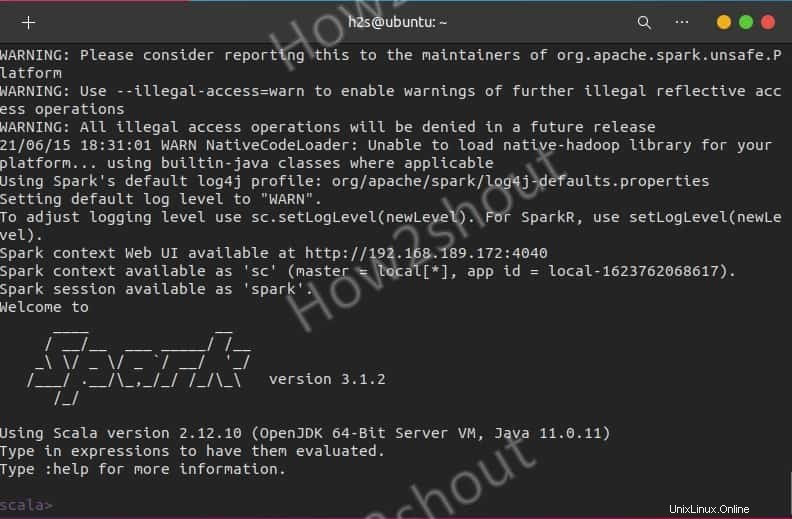
Mereka yang ingin menggunakan Spark shell untuk memulai pemrograman dapat mengaksesnya dengan mengetik langsung:
spark-shell
Untuk melihat opsi yang didukung, ketik- :help dan untuk keluar dari shell gunakan – :quite
Untuk memulai dengan Python shell alih-alih Scala, gunakan:
pyspark
Perintah Memulai dan Menghentikan Server
Jika Anda ingin memulai atau menghentikan master/pekerja instance, lalu gunakan skrip yang sesuai:
stop-master.sh stop-worker.sh
Untuk menghentikan sekaligus
stop-all.sh
Atau mulai sekaligus:
start-all.sh
Mengakhiri Pikiran:
Dengan cara ini, kita dapat menginstal dan mulai menggunakan Apache Spark di Ubuntu Linux. Untuk mengetahui lebih banyak tentang Anda dapat merujuk ke dokumentasi resmi . Namun, dibandingkan dengan Hadoop, Spark masih relatif muda, jadi Anda harus memperhitungkan beberapa sisi kasar. Namun, ini telah membuktikan dirinya berkali-kali dalam praktik dan memungkinkan kasus penggunaan baru di bidang data besar atau cepat melalui eksekusi cepat pekerjaan dan caching data. Dan terakhir, ia menawarkan API seragam untuk alat yang seharusnya harus dioperasikan dan dioperasikan secara terpisah di lingkungan Hadoop.