Apache Hadoop adalah kerangka kerja sumber terbuka yang digunakan untuk mengelola, menyimpan, dan memproses data untuk berbagai aplikasi data besar yang berjalan di bawah sistem klaster. Itu ditulis dalam Java dengan beberapa kode asli dalam skrip C dan shell. Ini menggunakan sistem file terdistribusi (HDFS) dan ditingkatkan dari server tunggal ke ribuan mesin.
Apache Hadoop didasarkan pada empat komponen utama:
- Hadoop Umum : Ini adalah kumpulan utilitas dan perpustakaan yang dibutuhkan oleh modul Hadoop lainnya.
- HDFS : Juga dikenal sebagai Sistem File Terdistribusi Hadoop yang didistribusikan ke beberapa node.
- MapReduce : Ini adalah kerangka kerja yang digunakan untuk menulis aplikasi untuk memproses data dalam jumlah besar.
- BENANG Hadoop : Juga dikenal sebagai Yet Another Resource Negotiator adalah lapisan manajemen sumber daya Hadoop.
Dalam tutorial ini, kami akan menjelaskan cara menyiapkan cluster Hadoop node tunggal di Ubuntu 20.04.
Prasyarat
- Server yang menjalankan Ubuntu 20.04 dengan RAM 4 GB.
- Kata sandi root dikonfigurasi di server Anda.
Perbarui Paket Sistem
Sebelum memulai, disarankan untuk memperbarui paket sistem Anda ke versi terbaru. Anda dapat melakukannya dengan perintah berikut:
apt-get update -y
apt-get upgrade -y
Setelah sistem Anda diperbarui, mulai ulang untuk menerapkan perubahan.
Instal Java
Apache Hadoop adalah aplikasi berbasis Java. Jadi, Anda perlu menginstal Java di sistem Anda. Anda dapat menginstalnya dengan perintah berikut:
apt-get install default-jdk default-jre -y
Setelah diinstal, Anda dapat memverifikasi versi Java yang diinstal dengan perintah berikut:
java -version
Anda akan mendapatkan output berikut:
openjdk version "11.0.7" 2020-04-14 OpenJDK Runtime Environment (build 11.0.7+10-post-Ubuntu-3ubuntu1) OpenJDK 64-Bit Server VM (build 11.0.7+10-post-Ubuntu-3ubuntu1, mixed mode, sharing)
Buat Pengguna Hadoop dan Siapkan SSH Tanpa Kata Sandi
Pertama, buat pengguna baru bernama hadoop dengan perintah berikut:
adduser hadoop
Selanjutnya, tambahkan pengguna hadoop ke grup sudo
usermod -aG sudo hadoop
Selanjutnya, login dengan pengguna hadoop dan buat pasangan kunci SSH dengan perintah berikut:
su - hadoop
ssh-keygen -t rsa
Anda akan mendapatkan output berikut:
Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Created directory '/home/hadoop/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub The key fingerprint is: SHA256:HG2K6x1aCGuJMqRKJb+GKIDRdKCd8LXnGsB7WSxApno [email protected] The key's randomart image is: +---[RSA 3072]----+ |..=.. | | O.+.o . | |oo*.o + . o | |o .o * o + | |o+E.= o S | |=.+o * o | |*.o.= o o | |=+ o.. + . | |o .. o . | +----[SHA256]-----+
Selanjutnya, tambahkan kunci ini ke kunci ssh Resmi dan berikan izin yang sesuai:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
Selanjutnya, verifikasi SSH tanpa kata sandi dengan perintah berikut:
ssh localhost
Setelah Anda masuk tanpa kata sandi, Anda dapat melanjutkan ke langkah berikutnya.
Instal Hadoop
Pertama, login dengan pengguna hadoop dan unduh versi terbaru Hadoop dengan perintah berikut:
su - hadoop
wget https://downloads.apache.org/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
Setelah unduhan selesai, ekstrak file yang diunduh dengan perintah berikut:
tar -xvzf hadoop-3.2.1.tar.gz
Selanjutnya, pindahkan direktori hasil ekstrak ke /usr/local/:
sudo mv hadoop-3.2.1 /usr/local/hadoop
Selanjutnya, buat direktori untuk menyimpan log dengan perintah berikut:
sudo mkdir /usr/local/hadoop/logs
Selanjutnya, ubah kepemilikan direktori hadoop menjadi hadoop:
sudo chown -R hadoop:hadoop /usr/local/hadoop
Selanjutnya, Anda perlu mengonfigurasi variabel lingkungan Hadoop. Anda dapat melakukannya dengan mengedit file ~/.bashrc:
nano ~/.bashrc
Tambahkan baris berikut:
export HADOOP_HOME=/usr/local/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Simpan dan tutup file setelah Anda selesai. Kemudian, aktifkan variabel lingkungan dengan perintah berikut:
source ~/.bashrc
Konfigurasi Hadoop
Di bagian ini, kita akan mempelajari cara mengatur Hadoop pada satu node.
Konfigurasi Variabel Lingkungan Java
Selanjutnya, Anda perlu mendefinisikan variabel lingkungan Java di hadoop-env.sh untuk mengonfigurasi YARN, HDFS, MapReduce, dan pengaturan proyek terkait Hadoop.
Pertama, cari jalur Java yang benar menggunakan perintah berikut:
which javac
Anda akan melihat output berikut:
/usr/bin/javac
Selanjutnya, cari direktori OpenJDK dengan perintah berikut:
readlink -f /usr/bin/javac
Anda akan melihat output berikut:
/usr/lib/jvm/java-11-openjdk-amd64/bin/javac
Selanjutnya, edit file hadoop-env.sh dan tentukan jalur Java:
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Tambahkan baris berikut:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_CLASSPATH+=" $HADOOP_HOME/lib/*.jar"
Selanjutnya, Anda juga perlu mengunduh file aktivasi Javax. Anda dapat mengunduhnya dengan perintah berikut:
cd /usr/local/hadoop/lib
sudo wget https://jcenter.bintray.com/javax/activation/javax.activation-api/1.2.0/javax.activation-api-1.2.0.jar
Anda sekarang dapat memverifikasi versi Hadoop menggunakan perintah berikut:
hadoop version
Anda akan mendapatkan output berikut:
Hadoop 3.2.1 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r b3cbbb467e22ea829b3808f4b7b01d07e0bf3842 Compiled by rohithsharmaks on 2019-09-10T15:56Z Compiled with protoc 2.5.0 From source with checksum 776eaf9eee9c0ffc370bcbc1888737 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.2.1.jar
Konfigurasikan File core-site.xml
Selanjutnya, Anda perlu menentukan URL untuk NameNode Anda. Anda dapat melakukannya dengan mengedit file core-site.xml:
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xml
Tambahkan baris berikut:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://0.0.0.0:9000</value>
<description>The default file system URI</description>
</property>
</configuration>
Simpan dan tutup file setelah Anda selesai:
Konfigurasikan File hdfs-site.xml
Selanjutnya, Anda perlu menentukan lokasi untuk menyimpan metadata node, file fsimage, dan mengedit file log. Anda dapat melakukannya dengan mengedit file hdfs-site.xml. Pertama, buat direktori untuk menyimpan metadata node:
sudo mkdir -p /home/hadoop/hdfs/{namenode,datanode}
sudo chown -R hadoop:hadoop /home/hadoop/hdfs Selanjutnya, edit file hdfs-site.xml dan tentukan lokasi direktori:
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
Tambahkan baris berikut:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hdfs/datanode</value>
</property>
</configuration>
Simpan dan tutup file.
Konfigurasikan File mapred-site.xml
Selanjutnya, Anda perlu mendefinisikan nilai MapReduce. Anda dapat menentukannya dengan mengedit file mapred-site.xml:
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Tambahkan baris berikut:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Simpan dan tutup file.
Konfigurasi File yarn-site.xml
Selanjutnya, Anda perlu mengedit file yarn-site.xml dan menentukan pengaturan terkait YARN:
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
Tambahkan baris berikut:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Simpan dan tutup file setelah Anda selesai.
Format HDFS NameNode
Selanjutnya, Anda perlu memvalidasi konfigurasi Hadoop dan memformat NameNode HDFS.
Pertama, login dengan pengguna Hadoop dan format HDFS NameNode dengan perintah berikut:
su - hadoop
hdfs namenode -format
Anda akan mendapatkan output berikut:
2020-06-07 11:35:57,691 INFO util.GSet: VM type = 64-bit 2020-06-07 11:35:57,692 INFO util.GSet: 0.25% max memory 1.9 GB = 5.0 MB 2020-06-07 11:35:57,692 INFO util.GSet: capacity = 2^19 = 524288 entries 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 2020-06-07 11:35:57,710 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 2020-06-07 11:35:57,710 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 2020-06-07 11:35:57,712 INFO util.GSet: Computing capacity for map NameNodeRetryCache 2020-06-07 11:35:57,712 INFO util.GSet: VM type = 64-bit 2020-06-07 11:35:57,712 INFO util.GSet: 0.029999999329447746% max memory 1.9 GB = 611.9 KB 2020-06-07 11:35:57,712 INFO util.GSet: capacity = 2^16 = 65536 entries 2020-06-07 11:35:57,743 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1242120599-69.87.216.36-1591529757733 2020-06-07 11:35:57,763 INFO common.Storage: Storage directory /home/hadoop/hdfs/namenode has been successfully formatted. 2020-06-07 11:35:57,817 INFO namenode.FSImageFormatProtobuf: Saving image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 using no compression 2020-06-07 11:35:57,972 INFO namenode.FSImageFormatProtobuf: Image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 of size 398 bytes saved in 0 seconds . 2020-06-07 11:35:57,987 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2020-06-07 11:35:58,000 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown. 2020-06-07 11:35:58,003 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at ubuntu2004/69.87.216.36 ************************************************************/
Mulai Kluster Hadoop
Pertama, jalankan NameNode dan DataNode dengan perintah berikut:
start-dfs.sh
Anda akan mendapatkan output berikut:
Starting namenodes on [0.0.0.0] Starting datanodes Starting secondary namenodes [ubuntu2004]
Selanjutnya, mulai YARN resource dan nodemanagers dengan menjalankan perintah berikut:
start-yarn.sh
Anda akan mendapatkan output berikut:
Starting resourcemanager Starting nodemanagers
Anda sekarang dapat memverifikasinya dengan perintah berikut:
jps
Anda akan mendapatkan output berikut:
5047 NameNode 5850 Jps 5326 SecondaryNameNode 5151 DataNode
Mengakses Antarmuka Web Hadoop
Anda sekarang dapat mengakses Hadoop NameNode menggunakan URL http://your-server-ip:9870. Anda akan melihat layar berikut:
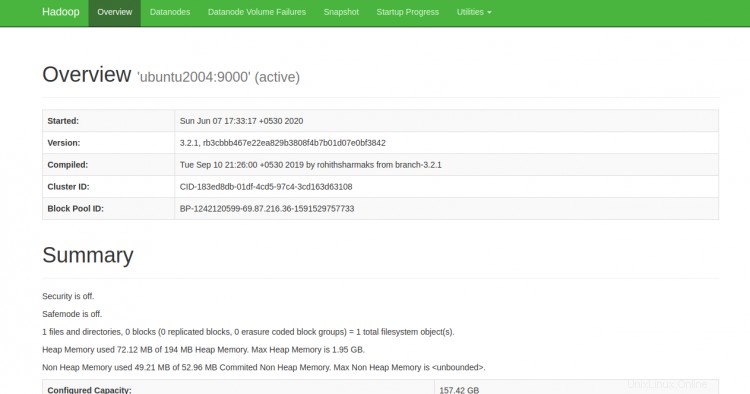
Anda juga dapat mengakses DataNodes individu menggunakan URL http://your-server-ip:9864. Anda akan melihat layar berikut:
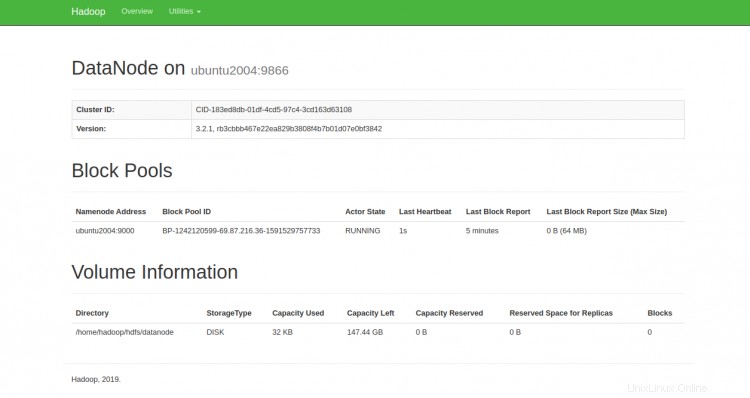
Untuk mengakses YARN Resource Manager, gunakan URL http://your-server-ip:8088. Anda akan melihat layar berikut:
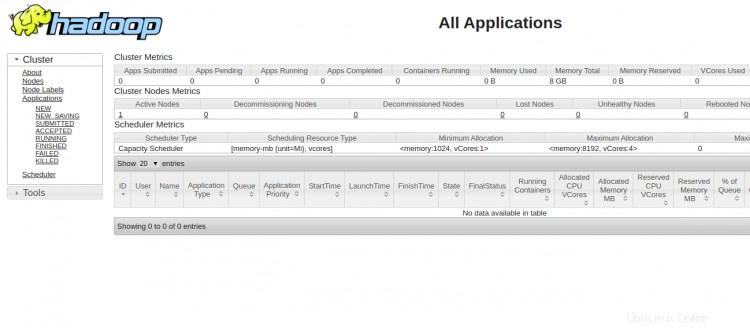
Kesimpulan
Selamat! Anda telah berhasil menginstal Hadoop pada satu node. Anda sekarang dapat mulai menjelajahi perintah HDFS dasar dan mendesain cluster Hadoop yang terdistribusi sepenuhnya. Jangan ragu untuk bertanya kepada saya jika Anda memiliki pertanyaan.