Teman-teman melanjutkan dengan pengetahuan lanjutan dan pemecahan masalah di glusterfs. Dalam artikel ini, kami memiliki 3 cluster node yang berjalan di glusterfs3.4. Berikut adalah langkah-langkah yang digunakan untuk pemecahan masalah glusterfs.
Langkah 1 :Periksa status dan informasi volume Gluster.

[root@gluster1 ~]# gluster volume info
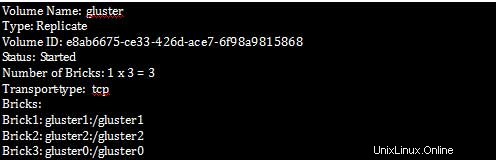
Langkah 2 :Untuk memverifikasi semua detail replikasi di Bricks.
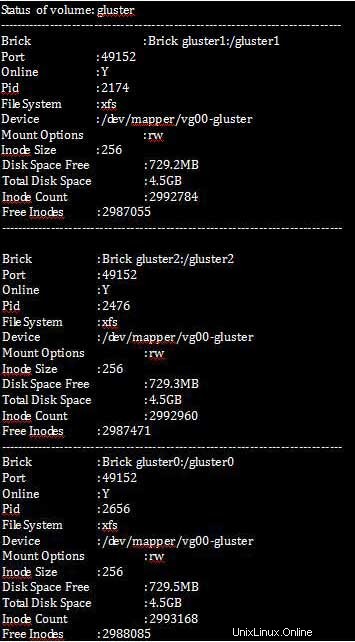
Perintah yang disebutkan di bawah ini akan menampilkan statistik lengkap tentang data apa yang telah direplikasi dan berapa banyak yang harus direplikasi dengan memeriksa ukuran total ruang disk yang kosong.
[root@gluster1 ~]# gluster volume status all detail
Langkah 3 :Sekarang kita perlu memiliki konfigurasi tertentu untuk meningkatkan kinerja dan karakteristik penyembuhan glusterfs.
# gluster volume set gluster cluster.min-free-disk 5% # gluster volume set cluster.rebalance-stats on # gluster volume set cluster.readdir-optimize on # gluster volume set cluster.background-self-heal-count 20 # gluster volume set cluster.metadata-self-heal on # gluster volume set cluster.data-self-heal on # gluster volume set cluster.entry-self-heal: on # gluster volume set cluster.self-heal-daemon on # gluster volume set cluster.heal-timeout 500 # gluster volume set cluster.self-heal-window-size 2 # gluster volume set cluster.data-self-heal-algorithm diff # gluster volume set cluster.eager-lock on # gluster volume set cluster.quorum-type auto # gluster volume set cluster.self-heal-readdir-size 2KB # gluster volume set network.ping-timeout 5
Kemudian jalankan:
# service glusterd restart
Setelah kita mengatur properti cluster, kita dapat memeriksa informasi volume seperti yang ditunjukkan di bawah ini:
[root@gluster1 ~]# gluster volume info
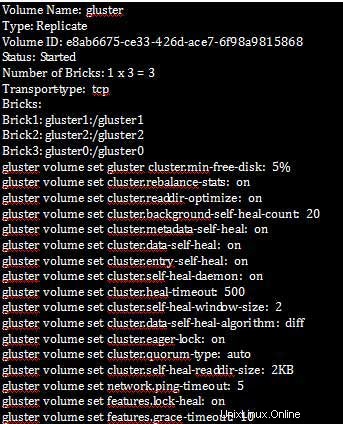
[root@gluster1 ~]# gluster volume status
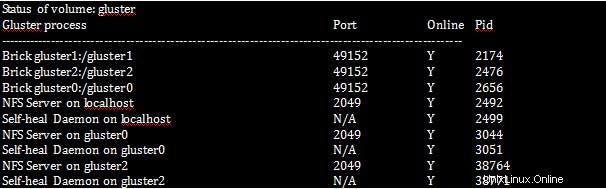
Harap diperhatikan bahwa Self-heal Daemon harus berjalan di setiap sistem dalam cluster karena bertanggung jawab untuk memulihkan jika ada node yang tidak aktif selama beberapa waktu dari cluster.
Langkah 4 :Sekarang untuk menghapus mesin gluster0 dari cluster.
Lepas Volume yang terpasang pada mesin gluster0:
[root@gluster0 ~]# umount /mnt [root@gluster1 ~]# gluster volume remove-brick gluster replica 2 gluster0:/gluster0 commit
info volume gluster (untuk memverifikasi):
[root@gluster1 ~]# gluster volume info
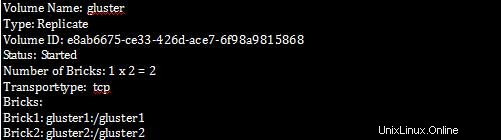
Pada gluster1 jalankan perintah berikut:
# gluster peer detach gluster0
bata server gluster0 dihapus dari cluster.