Jawaban yang diperbarui di tahun 2020 :
Sesuai jawaban @Owen, ORC telah tumbuh dan matang sebagai proyek Apache miliknya. Daftar lengkap Pengadopsi ORC menunjukkan seberapa lazim ORC sekarang didukung di banyak jenis teknologi Big Data.
Penghargaan untuk @Owen dan tim proyek ORC Apache, situs proyek ORC memiliki dokumentasi terkini yang terpelihara sepenuhnya tentang penggunaan alat berdiri sendiri Java atau C++ pada file ORC yang disimpan di sistem file lokal Linux. Yang membawa obor untuk halaman wiki Hive+ORC Apache yang asli.
Jawaban asli bertanggal:May 30 '14 at 16:27
Utilitas dump file ORC dilengkapi dengan sarang (0,11 atau lebih tinggi):
hive --orcfiledump <hdfs-location-of-orc-file>Tautan sumber
Itu juga mampu melihat konten file ORC dengan aplikasi desktop yang berjalan di Linux.
Ada aplikasi desktop untuk melihat Parquet dan juga data format biner lainnya seperti ORC dan AVRO. Ini murni aplikasi Java sehingga bisa dijalankan di Linux, Mac dan juga Windows. Silakan periksa Penampil File Bigdata untuk detailnya.
Ini mendukung tipe data yang kompleks seperti array, peta, struct, dll.
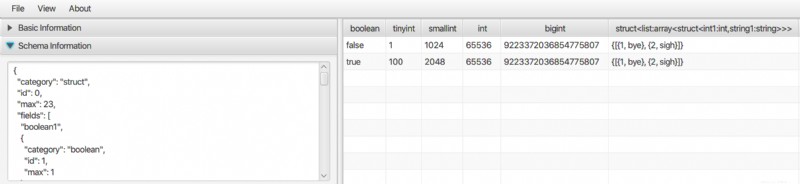
Sekarang ada juga executable asli untuk Linux dan MacOS yang mencetak konten file orc di JSON. Lihat proyek ORC (http://orc.apache.org/) dan bangun alat C++.
% orc-contents examples/TestOrcFile.test1.orc
Ada juga alat metadata asli:
% orc-metadata ../examples/TestOrcFile.test1.orc
Proyek ORC juga memiliki uber jar mandiri yang dapat melakukan hal yang sama dari Java.
% java -jar orc-tools-1.2.3-uber.jar data myfile.orc