Jika tujuan Anda adalah menggunakan profiler, gunakan salah satu yang disarankan.
Namun, jika Anda sedang terburu-buru dan Anda dapat menginterupsi program Anda secara manual di bawah debugger saat secara subyektif lambat, ada cara sederhana untuk menemukan masalah kinerja.
Hentikan saja beberapa kali, dan setiap kali lihat tumpukan panggilan. Jika ada beberapa kode yang membuang-buang persentase waktu, 20% atau 50% atau apa pun, itu adalah kemungkinan Anda akan menangkapnya saat beraksi di setiap sampel. Jadi, itu kira-kira persentase sampel yang akan Anda lihat. Tidak ada tebakan yang diperlukan. Jika Anda menebak apa masalahnya, ini akan membuktikan atau menyangkalnya.
Anda mungkin memiliki beberapa masalah kinerja dengan ukuran berbeda. Jika Anda membersihkan salah satu dari mereka, yang tersisa akan mengambil persentase yang lebih besar, dan lebih mudah dikenali, pada lintasan berikutnya. Ini efek pembesaran , jika digabungkan dengan beberapa masalah, dapat menyebabkan faktor percepatan yang sangat besar.
Peringatan :Pemrogram cenderung skeptis terhadap teknik ini kecuali mereka telah menggunakannya sendiri. Mereka akan mengatakan bahwa profiler memberi Anda informasi ini, tetapi itu hanya benar jika mereka mengambil sampel seluruh tumpukan panggilan, dan kemudian membiarkan Anda memeriksa kumpulan sampel acak. (Ringkasan adalah tempat hilangnya wawasan.) Grafik panggilan tidak memberi Anda informasi yang sama, karena
- Mereka tidak meringkas di tingkat instruksi, dan
- Mereka memberikan ringkasan yang membingungkan di hadapan rekursi.
Mereka juga akan mengatakan itu hanya berfungsi pada program mainan, padahal sebenarnya itu bekerja pada program apa pun, dan tampaknya bekerja lebih baik pada program yang lebih besar, karena mereka cenderung memiliki lebih banyak masalah untuk ditemukan. Mereka akan mengatakan terkadang menemukan hal-hal yang bukan masalah, tetapi itu hanya benar jika Anda melihat sesuatu sekali . Jika Anda melihat masalah pada lebih dari satu sampel, itu nyata.
N.B. Ini juga dapat dilakukan pada program multi-utas jika ada cara untuk mengumpulkan sampel tumpukan panggilan dari kumpulan utas pada satu titik waktu, seperti yang ada di Java.
P.P.S Secara umum, semakin banyak lapisan abstraksi yang Anda miliki dalam perangkat lunak, semakin besar kemungkinan Anda menemukan bahwa itu adalah penyebab masalah kinerja (dan peluang untuk mempercepat).
Ditambahkan :Ini mungkin tidak jelas, tetapi teknik pengambilan sampel tumpukan bekerja sama baiknya dengan adanya rekursi. Alasannya adalah bahwa waktu yang akan dihemat dengan penghapusan instruksi diperkirakan oleh fraksi sampel yang berisi instruksi tersebut, terlepas dari berapa kali hal itu dapat terjadi dalam sampel.
Keberatan lain yang sering saya dengar adalah:"Ini akan berhenti di suatu tempat secara acak, dan akan melewatkan masalah sebenarnya ". Ini berasal dari memiliki konsep sebelumnya tentang apa masalah sebenarnya. Sifat utama dari masalah kinerja adalah bahwa mereka menentang ekspektasi. Pengambilan sampel memberi tahu Anda bahwa ada masalah, dan reaksi pertama Anda adalah ketidakpercayaan. Itu wajar, tetapi Anda bisa pastikan jika menemukan masalah itu nyata, dan sebaliknya.
Ditambahkan :Biarkan saya membuat penjelasan Bayesian tentang cara kerjanya. Misalkan ada beberapa instruksi I (panggilan atau sebaliknya) yang ada di tumpukan panggilan beberapa pecahan f waktu (dan dengan demikian biaya yang banyak). Untuk mudahnya, misalkan kita tidak tahu apa itu f adalah, tetapi asumsikan itu adalah 0,1, 0,2, 0,3, ... 0,9, 1,0, dan probabilitas sebelumnya dari masing-masing kemungkinan ini adalah 0,1, jadi semua biaya ini kemungkinannya sama-sama a-priori.
Kemudian misalkan kita hanya mengambil 2 sampel tumpukan, dan kita melihat instruksi I pada kedua sampel, observasi yang ditunjuk o=2/2 . Ini memberi kami perkiraan baru tentang frekuensi f dari I , menurut ini:
Prior
P(f=x) x P(o=2/2|f=x) P(o=2/2&&f=x) P(o=2/2&&f >= x) P(f >= x | o=2/2)
0.1 1 1 0.1 0.1 0.25974026
0.1 0.9 0.81 0.081 0.181 0.47012987
0.1 0.8 0.64 0.064 0.245 0.636363636
0.1 0.7 0.49 0.049 0.294 0.763636364
0.1 0.6 0.36 0.036 0.33 0.857142857
0.1 0.5 0.25 0.025 0.355 0.922077922
0.1 0.4 0.16 0.016 0.371 0.963636364
0.1 0.3 0.09 0.009 0.38 0.987012987
0.1 0.2 0.04 0.004 0.384 0.997402597
0.1 0.1 0.01 0.001 0.385 1
P(o=2/2) 0.385
Kolom terakhir menyatakan bahwa, misalnya, probabilitas bahwa f>=0,5 adalah 92%, naik dari asumsi sebelumnya sebesar 60%.
Misalkan asumsi sebelumnya berbeda. Misalkan kita menganggap P(f=0.1) adalah 0,991 (hampir pasti), dan semua kemungkinan lainnya hampir tidak mungkin (0,001). Dengan kata lain, kepastian kita sebelumnya adalah I murah. Lalu kita mendapatkan:
Prior
P(f=x) x P(o=2/2|f=x) P(o=2/2&& f=x) P(o=2/2&&f >= x) P(f >= x | o=2/2)
0.001 1 1 0.001 0.001 0.072727273
0.001 0.9 0.81 0.00081 0.00181 0.131636364
0.001 0.8 0.64 0.00064 0.00245 0.178181818
0.001 0.7 0.49 0.00049 0.00294 0.213818182
0.001 0.6 0.36 0.00036 0.0033 0.24
0.001 0.5 0.25 0.00025 0.00355 0.258181818
0.001 0.4 0.16 0.00016 0.00371 0.269818182
0.001 0.3 0.09 0.00009 0.0038 0.276363636
0.001 0.2 0.04 0.00004 0.00384 0.279272727
0.991 0.1 0.01 0.00991 0.01375 1
P(o=2/2) 0.01375
Sekarang tertulis P(f >= 0.5) sebesar 26%, naik dari asumsi sebelumnya sebesar 0,6%. Jadi Bayes memungkinkan kami memperbarui perkiraan kami tentang kemungkinan biaya I . Jika jumlah datanya kecil, data tersebut tidak memberi tahu kami secara akurat berapa biayanya, hanya cukup besar untuk diperbaiki.
Cara lain untuk melihatnya disebut Aturan Suksesi. Jika Anda melempar koin 2 kali, dan muncul kepala dua kali, apa yang memberitahu Anda tentang kemungkinan bobot koin? Cara yang dihormati untuk menjawab adalah dengan mengatakan bahwa itu adalah distribusi Beta, dengan nilai rata-rata (number of hits + 1) / (number of tries + 2) = (2+1)/(2+2) = 75% .
(Kuncinya adalah kita melihat I lebih dari sekali. Jika kita hanya melihatnya sekali, itu tidak banyak memberi tahu kita kecuali f itu> 0.)
Jadi, bahkan jumlah sampel yang sangat kecil dapat memberi tahu kami banyak tentang biaya instruksi yang dilihatnya. (Dan itu akan melihat mereka dengan frekuensi, rata-rata, sebanding dengan biayanya. Jika n sampel diambil, dan f adalah biayanya, lalu I akan muncul di nf+/-sqrt(nf(1-f)) sampel. Contoh, n=10 , f=0.3 , yaitu 3+/-1.4 sampel.)
Ditambahkan :Untuk memberikan kesan intuitif tentang perbedaan antara pengukuran dan pengambilan sampel tumpukan acak:
Sekarang ada profiler yang mengambil sampel tumpukan, bahkan pada jam dinding, tetapi apa yang keluar adalah pengukuran (atau hot path, atau hot spot, dari mana "kemacetan" dapat dengan mudah disembunyikan). Apa yang tidak mereka tunjukkan kepada Anda (dan mereka bisa dengan mudah) adalah sampel sebenarnya itu sendiri. Dan jika tujuan Anda adalah untuk menemukan kemacetan, jumlah yang perlu Anda lihat adalah, rata-rata , 2 dibagi dengan bagian waktu yang diperlukan. Jadi, jika dibutuhkan 30% waktu, rata-rata 2/.3 =6,7 sampel akan menunjukkannya, dan peluang 20 sampel akan menunjukkannya adalah 99,2%.
Berikut adalah ilustrasi langsung tentang perbedaan antara memeriksa pengukuran dan memeriksa sampel tumpukan. Hambatannya bisa berupa satu gumpalan besar seperti ini, atau banyak gumpalan kecil, tidak ada bedanya.
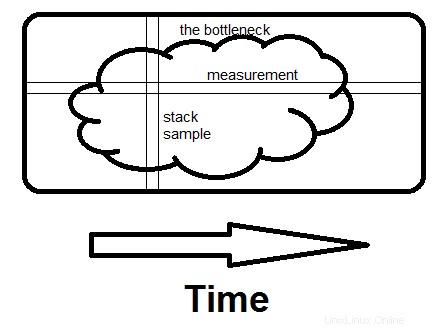
Pengukuran bersifat horizontal; ia memberi tahu Anda berapa lama waktu yang dibutuhkan rutinitas tertentu. Pengambilan sampel bersifat vertikal. Jika ada cara untuk menghindari apa yang dilakukan seluruh program pada saat itu, dan jika Anda melihatnya pada sampel kedua , Anda telah menemukan kemacetan. Itulah yang membuat perbedaan - melihat seluruh alasan waktu yang dihabiskan, bukan hanya seberapa banyak.
Anda dapat menggunakan Valgrind dengan opsi berikut
valgrind --tool=callgrind ./(Your binary)
Ini akan menghasilkan file bernama callgrind.out.x . Anda kemudian dapat menggunakan kcachegrind alat untuk membaca file ini. Ini akan memberi Anda analisis grafis tentang berbagai hal dengan hasil seperti garis mana yang harganya berapa.
Saya menganggap Anda menggunakan GCC. Solusi standarnya adalah membuat profil dengan gprof.
Pastikan untuk menambahkan -pg untuk dikompilasi sebelum membuat profil:
cc -o myprog myprog.c utils.c -g -pg
Saya belum mencobanya tetapi saya mendengar hal-hal baik tentang google-perftools. Ini pasti patut dicoba.
Pertanyaan terkait di sini.
Beberapa kata kunci lainnya jika gprof tidak melakukan pekerjaan untuk Anda:Valgrind, Intel VTune, Sun DTrace.