Tugas utama robot web adalah merayapi atau memindai situs web dan halaman untuk mendapatkan informasi; mereka bekerja tanpa lelah untuk mengumpulkan data untuk mesin pencari dan aplikasi lainnya. Bagi sebagian orang, ada alasan bagus untuk menjauhkan halaman dari mesin pencari. Baik Anda ingin menyempurnakan akses ke situs Anda atau ingin bekerja di situs pengembangan tanpa muncul di hasil Google, setelah diterapkan, file robots.txt memungkinkan perayap web dan bot mengetahui informasi apa yang dapat mereka kumpulkan.
Apa itu File Robots.txt?
Robots.txt adalah file situs web teks biasa di akar situs Anda yang mengikuti Standar Pengecualian Robot. Misalnya, www.domainanda.com akan memiliki file robots.txt di www.domainanda.com/robots.txt. File terdiri dari satu atau lebih aturan yang mengizinkan atau memblokir akses ke crawler, membatasi mereka ke jalur file tertentu di situs web. Secara default, semua file sepenuhnya diizinkan untuk dirayapi kecuali ditentukan lain.
File robots.txt adalah salah satu aspek pertama yang dianalisis oleh crawler. Penting untuk dicatat bahwa situs Anda hanya dapat memiliki satu file robots.txt. File akan diterapkan pada satu atau beberapa halaman atau seluruh situs untuk mencegah mesin telusur menampilkan detail tentang situs web Anda.
Artikel ini akan memberikan lima langkah untuk membuat file robots.txt dan sintaks yang diperlukan untuk mencegah bot.
Cara Menyiapkan File Robots.txt
1. Buat File Robots.txt
Anda harus memiliki akses ke root domain Anda. Penyedia hosting web Anda dapat membantu Anda apakah Anda memiliki akses yang sesuai atau tidak.
Bagian terpenting dari file adalah pembuatan dan lokasinya. Gunakan editor teks apa pun untuk membuat file robots.txt dan dapat ditemukan di:
- Akar domain Anda:www.domainanda.com/robots.txt.
- Subdomain Anda:page.domainanda.com/robots.txt.
- Port non-standar:www.domainanda.com:881/robots.txt.
Terakhir, Anda perlu memastikan bahwa file robots.txt Anda adalah file teks yang disandikan UTF-8. Google serta mesin telusur dan perayap populer lainnya mungkin mengabaikan karakter di luar rentang UTF-8, yang mungkin membuat aturan robots.txt Anda tidak valid.
2. Setel Agen-Pengguna Robots.txt Anda
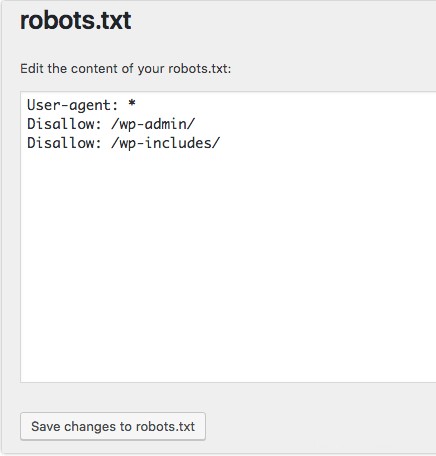
Langkah selanjutnya dalam cara membuat file robots.txt adalah mengatur user-agent . agen-pengguna berkaitan dengan perayap web atau mesin telusur yang ingin Anda izinkan atau blokir. Beberapa entitas dapat menjadi agen-pengguna . Kami telah mencantumkan beberapa perayap di bawah ini, serta asosiasinya.
Ada tiga cara berbeda untuk membuat agen-pengguna dalam file robots.txt Anda.
Membuat Satu Agen-Pengguna
Sintaks yang Anda gunakan untuk mengatur agen pengguna adalah User-agent:NameOfBot . Di bawah, DuckDuckBot adalah satu-satunya agen pengguna didirikan.
# Example of how to set user-agent
User-agent: DuckDuckBotMembuat Lebih dari Satu User-agent
Jika kami harus menambahkan lebih dari satu, ikuti proses yang sama seperti yang Anda lakukan untuk agen-pengguna DuckDuckBot pada baris berikutnya, masukkan nama agen-pengguna additional tambahan . Dalam contoh ini, kami menggunakan Facebot.
#Example of how to set more than one user-agent
User-agent: DuckDuckBot
User-agent: FacebotMenetapkan Semua Perayap sebagai Agen-Pengguna
Untuk memblokir semua bot atau crawler, ganti nama bot dengan tanda bintang (*).
#Example of how to set all crawlers as user-agent
User-agent: *3. Setel Aturan ke File Robots.txt Anda
File robots.txt dibaca dalam grup. Sebuah grup akan menentukan siapa agen-pengguna adalah dan memiliki satu aturan atau arahan untuk menunjukkan file atau direktori mana yang menjadi agen-pengguna dapat atau tidak dapat mengakses.
Berikut adalah arahan yang digunakan:
- Larang :Arahan yang merujuk ke halaman atau direktori yang terkait dengan domain root Anda yang tidak ingin Anda beri nama agen pengguna merangkak. Ini akan dimulai dengan garis miring (/) diikuti oleh url halaman penuh. Anda akan mengakhirinya dengan garis miring hanya jika merujuk ke direktori dan bukan seluruh halaman. Anda dapat menggunakan satu atau lebih larang setelan per aturan.
- Izinkan :Arahan merujuk ke halaman atau direktori yang relatif terhadap domain root Anda yang ingin Anda beri nama agen-pengguna merangkak. Misalnya, Anda akan menggunakan allow direktif untuk mengganti disallow aturan. Ini juga akan dimulai dengan garis miring (/) diikuti oleh url halaman penuh. Anda akan mengakhirinya dengan garis miring hanya jika merujuk ke direktori dan bukan seluruh halaman. Anda dapat menggunakan satu atau lebih izinkan setelan per aturan.
- Peta Situs :Arahan peta situs bersifat opsional dan memberikan lokasi peta situs untuk situs web. Satu-satunya ketentuan adalah bahwa itu harus berupa URL yang sepenuhnya memenuhi syarat. Anda dapat menggunakan nol atau lebih, tergantung pada apa yang diperlukan.
Perayap web memproses grup dari atas ke bawah. Seperti yang disebutkan sebelumnya, mereka mengakses halaman atau direktori mana pun yang tidak secara eksplisit disetel ke disallow . Oleh karena itu, tambahkan Disallow:/ di bawah agen-pengguna informasi di setiap grup untuk memblokir agen pengguna tertentu agar tidak merayapi situs web Anda.
# Example of how to block DuckDuckBot
User-agent: DuckDuckBot
Disallow: /
#Example of how to block more than one user-agent
User-agent: DuckDuckBot
User-agent: Facebot
Disallow: /
#Example of how to block all crawlers
User-agent: *
Disallow: /Untuk memblokir subdomain tertentu dari semua perayap, tambahkan garis miring ke depan dan URL subdomain lengkap di aturan larangan Anda.
# Example
User-agent: *
Disallow: /https://page.yourdomain.com/robots.txtJika Anda ingin memblokir sebuah direktori, ikuti proses yang sama dengan menambahkan garis miring ke depan dan nama direktori Anda, tetapi kemudian akhiri dengan garis miring lagi.
# Example
User-agent: *
Disallow: /images/Terakhir, jika Anda ingin semua mesin telusur mengumpulkan informasi di semua halaman situs Anda, Anda dapat membuat izinkan atau larang aturan, tetapi pastikan untuk menambahkan garis miring saat menggunakan allow aturan. Contoh kedua aturan ditunjukkan di bawah ini.
# Allow example to allow all crawlers
User-agent: *
Allow: /
# Disallow example to allow all crawlers
User-agent: *
Disallow:4. Unggah File Robots.txt Anda
Situs web tidak secara otomatis dilengkapi dengan file robots.txt karena tidak diperlukan. Setelah Anda memutuskan untuk membuatnya, unggah file ke direktori root situs web Anda. Mengunggah tergantung pada struktur file situs Anda dan lingkungan hosting web Anda. Hubungi penyedia hosting Anda untuk mendapatkan bantuan tentang cara mengunggah file robots.txt Anda.
5. Verifikasi File Robots.txt Anda Berfungsi dengan Benar
Ada beberapa cara untuk menguji dan memastikan file robots.txt Anda berfungsi dengan benar. Dengan salah satu dari ini, Anda dapat melihat kesalahan dalam sintaks atau logika Anda. Berikut adalah beberapa di antaranya:
- Penguji robots.txt Google di Search Console mereka.
- Validator dan Alat Pengujian robots.txt dari Merkle, Inc.
- Alat Uji robots.txt Ryte.
Bonus:Menggunakan Robots.txt Di WordPress
Jika Anda menggunakan plugin WordPress Yoast SEO, Anda akan melihat bagian dalam jendela admin untuk membuat file robots.txt.
Masuk ke backend situs WordPress Anda dan akses Alat di bawah SEO bagian, lalu klik Editor file .
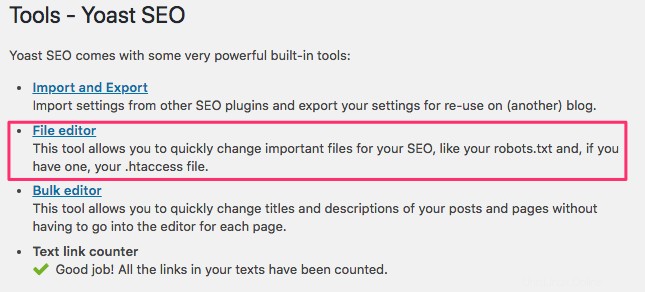
Ikuti urutan yang sama seperti sebelumnya untuk menetapkan agen dan aturan pengguna Anda. Di bawah ini, kami telah memblokir perayap web dari direktori wp-admin dan wp-include WordPress sambil tetap mengizinkan pengguna dan bot untuk melihat halaman situs lain. Setelah selesai, klik Simpan perubahan ke robots.txt untuk mengaktifkan file robots.txt.