Setelah Anda memasuki domain sistem operasi Linux, daftar kemungkinan komputasi melalui lingkungan baris perintah Linux akan tampak tidak ada habisnya. Ini hanya karena semakin sering Anda menggunakan Linux, semakin Anda ingin belajar dan keinginan ini membawa Anda melalui banyak kesempatan belajar.
Dalam tutorial ini, kita akan melihat menghitung dan mencetak baris duplikat dalam file teks di bawah lingkungan sistem operasi Linux. Modul tutorial ini adalah bagian dari manajemen file Linux.
Baris perintah atau lingkungan terminal Linux bukanlah hal baru untuk memproses file teks input. Ini sangat mahir dalam operasi seperti itu sehingga belum menghadapi tantangan yang layak di bawah pemrosesan file teks.
Tutorial ini akan menjelaskan cara mengidentifikasi/menangani baris duplikat dalam file teks acak di Linux.
Pernyataan Masalah
Untuk membuat tutorial ini lebih mudah dan lebih menarik, kita akan membuat file teks sampel yang akan bertindak sebagai file acak yang ingin kita periksa keberadaan baris duplikatnya.
$ sudo nano sample_file.txt
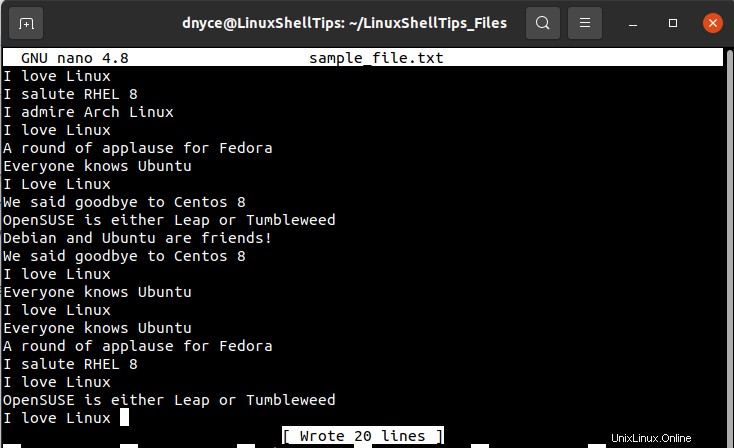
Hanya dengan memindai melalui tangkapan layar file teks di atas, kita seharusnya dapat mencatat keberadaan beberapa baris duplikat tetapi kita tidak dapat memastikan jumlah pasti kemunculannya.
Untuk memastikan jumlah baris duplikat yang terjadi, kami akan menemukan solusi kami dari pendekatan berbasis baris perintah/terminal Linux berikut:
Temukan Baris Duplikat dalam File Menggunakan Perintah sortir dan uniq
Kenyamanan menggunakan unik perintahnya adalah ia datang dengan -c pilihan perintah. Namun, opsi perintah ini hanya valid jika file teks yang Anda targetkan/pindai memiliki duplikat baris yang berdekatan.
Untuk menghindari ketidaknyamanan ini saat menggunakan uniq perintah untuk mencetak baris duplikat kita harus meminjam pendekatan perintah sort untuk mengelompokkan baris berulang/ganda dalam file teks yang ditargetkan.
Singkatnya, pertama-tama kita akan meneruskan file teks yang ditargetkan melalui sort perintah dan kemudian menyalurkannya ke uniq perintah yang kemudian akan disertai dengan -c opsi perintah seperti yang ditunjukkan di bawah ini:
$ sort sample_file.txt | uniq -c
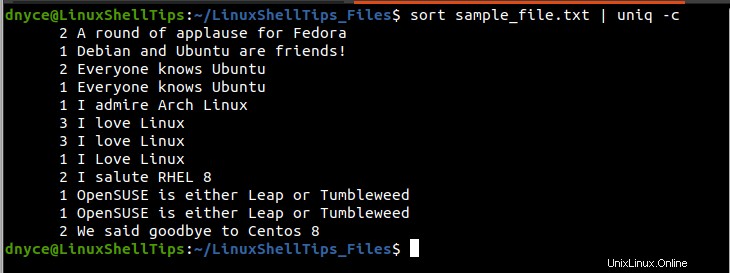
Kolom pertama (di sebelah kiri) dari output di atas menunjukkan berapa kali garis yang dicetak di kolom kanan muncul dalam sample_file.txt berkas teks. Misalnya, baris “Saya suka Linux” digandakan/diulang (3+3+1) kali dalam file teks sebanyak 7 kali.
Mencetak Baris Duplikat dalam File Menggunakan Perintah Awk
awk perintah untuk menyelesaikan ini “cetak baris duplikat dalam file teks ” Masalah adalah satu kalimat sederhana. Untuk memahami cara kerjanya, pertama-tama kita perlu mengimplementasikannya seperti yang ditunjukkan di bawah ini:
$ awk '{ a[$0]++ } END{ for(x in a) print a[x], x }' sample_file.txt
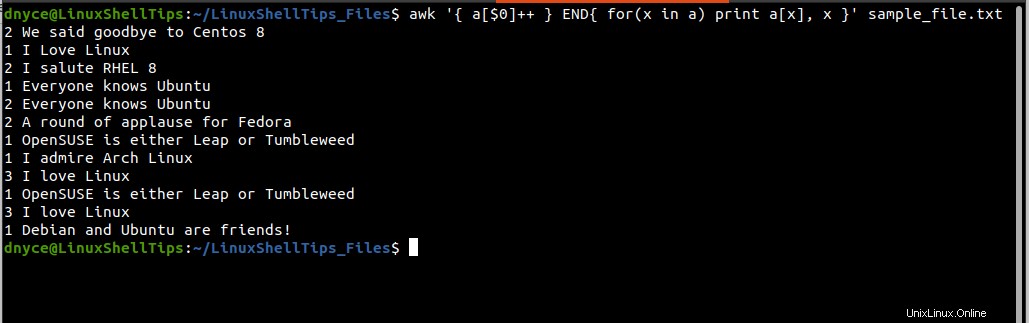
Eksekusi perintah di atas menghasilkan dua kolom, kolom pertama menghitung berapa kali baris yang diulang/digandakan muncul dalam file teks, dan kolom kedua menunjuk ke baris yang dimaksud.
Namun, output dari perintah di atas tidak terorganisir seperti yang ada di bawah sort dan unik perintah.
Kami telah berhasil membahas cara mencetak baris duplikat dalam file teks di bawah lingkungan sistem operasi Linux.