Huuu! Halloween akhirnya tiba. Sudah menyiapkan kostum Halloween favoritmu? Atau, mungkin anak-anak Anda sedang bersiap-siap untuk melakukan trick-or-treat. Ini adalah tahun 2020, dan pandemi Coronavirus ini mungkin adalah hal yang paling menakutkan—bahkan lebih menakutkan daripada hantu dan zombie yang mengetuk pintu Anda.

Ketika Anda seorang sysadmin, Anda mungkin menghadapi beberapa momen yang sangat menakutkan yang membuat Anda merinding dan malam tanpa tidur, tetapi bahkan hantu, zombie, atau monster yang paling menakutkan pun memiliki musuh yang harus dihindari, apakah itu salib Koptik, kalung bawang putih. , sebongkah Kryptonite, atau sysadmin ahli. Pada artikel ini, saya akan menyajikan beberapa momen menakutkan yang mungkin terjadi bagi seorang sysadmin seperti Anda. Saya juga akan memberi tahu Anda bagaimana Anda bisa menanganinya. Bagaimanapun, ini adalah Halloween, jadi pikirkan daftar ini sebagai hadiah Halloween saya untuk Anda.
Saya juga menyediakan blog ini di YouTube, Anda ingin menontonnya daripada membaca lebih lanjut.
Trik #1:Server cloud mogok

Ini jam 2 pagi, dan ponsel cerdas Anda mulai berdering. Setengah bangun, Anda mengangkat telepon dan menatap layar. Menembak. Email Anda terus mendapatkan pemberitahuan yang dibuat secara otomatis dari sistem pesan Slack/Teams bahwa server produksi Anda telah tidak aktif selama dua hingga tiga jam. Hal berikutnya yang Anda tahu, bos Anda ingin Anda dan tim operasi lainnya berada di sana secepatnya. Ini jelas merupakan situasi yang tidak Anda inginkan, jadi bagaimana Anda bisa mencegahnya?
[ Anda mungkin juga menyukai: Perintah bash bang:Trik yang harus diketahui untuk baris perintah Linux ]
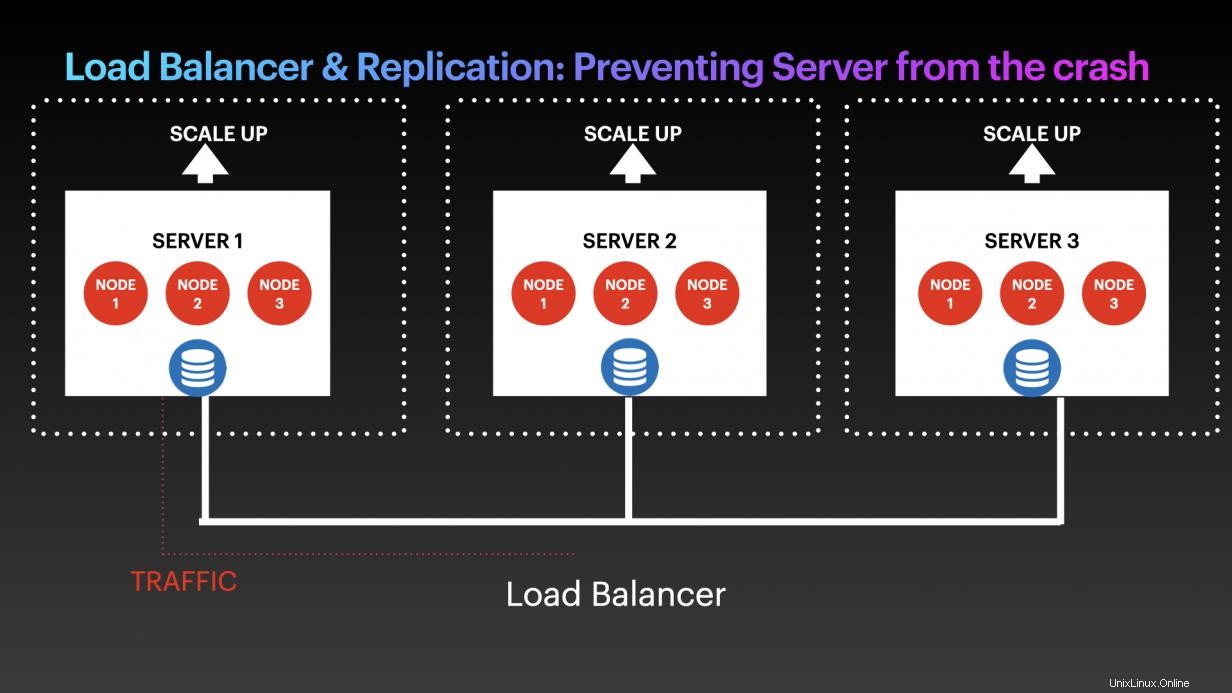
Perlakukan #1:Load balancer dan replikasi:Mencegah server mogok
Meskipun tidak mungkin untuk sepenuhnya mencegah server yang sedang berjalan agar tidak mogok, dimungkinkan untuk membuat sistem yang hampir toleran terhadap kesalahan jika Anda merancangnya dengan cara yang benar. Salah satu solusinya adalah mengatur replikasi di beberapa lingkungan dengan multi-cluster dan multi-node. Anda dapat menambahkan penyeimbang beban untuk memastikan bahwa cluster lain terus beroperasi meskipun satu cluster dimatikan. Jika ada terlalu banyak lalu lintas atau masalah kinerja lainnya, Anda dapat mengonfigurasi fitur penskalaan otomatis untuk meningkatkan atau menskalakan.
Trik #2:Kerusakan atau kehilangan data

Seorang magang baru bernama Mike bergabung dengan tim teknik Anda. Bersemangat karena dia mendapatkan alat yang dia butuhkan, dia menjalankan kueri SQL tanpa bermaksud merusak apa pun. Tapi uh-oh. Perubahan kecil ini menyebabkan tabel database Anda terhapus, dan semua data penting pelanggan kini hilang. Apa yang dapat Anda lakukan untuk mencegah masalah seperti ini terjadi?
Perlakukan #2:Pencadangan dan pemulihan data:Perbaiki kehilangan dan kerusakan data
Kehilangan data adalah masalah serius untuk layanan atau aplikasi langsung apa pun. Dengan demikian, strategi backup dan restore harus selalu tersedia, setidaknya untuk lingkungan produksi. Idealnya, prosedur pencadangan dan pemulihan harus tersedia di semua lingkungan. Juga, buat mekanisme untuk mengotomatisasi proses ini. Cara paling sederhana yang dapat Anda mulai adalah dengan membuat beberapa skrip bash untuk menjalankan serangkaian perintah pencadangan dan pemulihan.

Trik #3:Aplikasi mogok

Hore! Server dan database Anda sekarang toleran terhadap kesalahan dan kokoh, tetapi satu aplikasi Java yang mengekspos titik akhir penting yang dihadapi bisnis tiba-tiba meledak. Saat pelanggan mengunjungi situs web, mereka hanya melihat halaman 404, yang membebani perusahaan Anda satu juta dolar per menit.
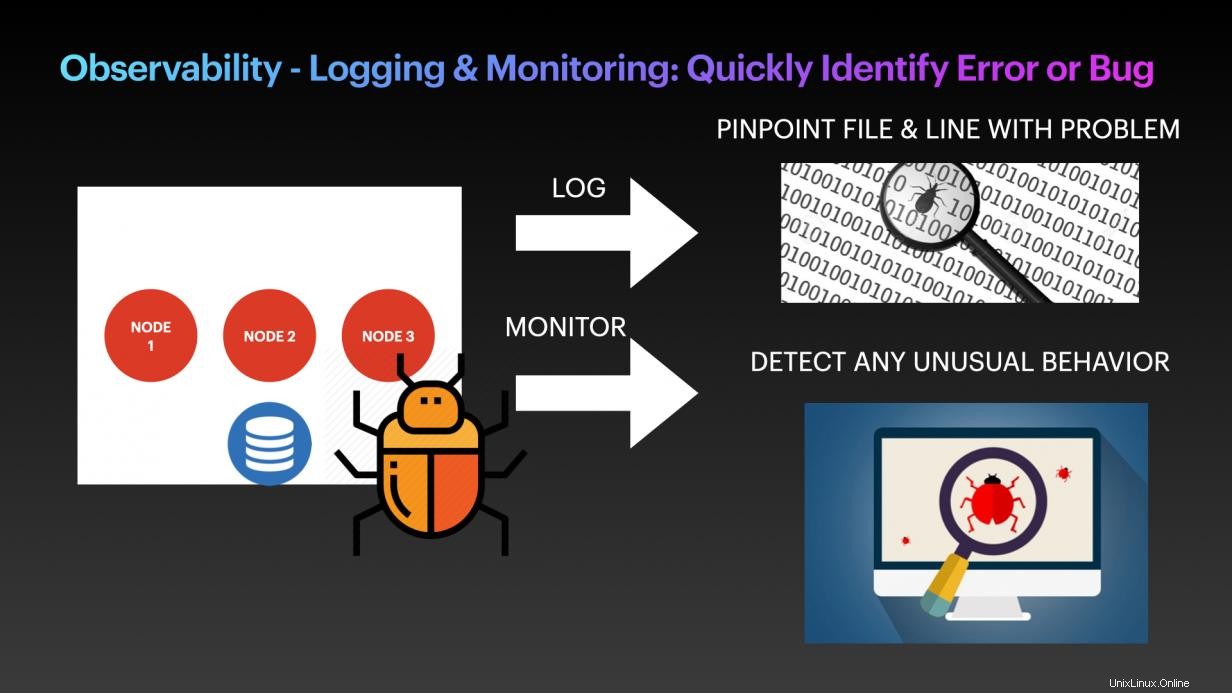
Perlakukan #3:Observabilitas - pencatatan dan pemantauan:Identifikasi kesalahan atau bug dengan cepat
Kesalahan aplikasi terjadi sepanjang waktu, dan ada banyak teknik dan Pola Desain pemrograman, seperti pola Pemutus Arus, untuk menangani masalah. Namun, kesalahan apa pun yang berjalan di dalam aplikasi harus diidentifikasi dengan cepat sebelum dapat diperbaiki. Dengan demikian, logging dan monitoring adalah kebutuhan mutlak untuk semua aplikasi. Pastikan aplikasi Anda mengaktifkan titik debug di seluruh blok dan baris kode. Kesalahan atau keluaran ini harus dikirim ke dasbor pemantauan sehingga pengembang dapat dengan cepat menemukan masalahnya.
Trik #4:Aplikasi lambat

Anda menambahkan pencatatan dan pemantauan untuk semua aplikasi. Anda akhirnya bisa tidur nyenyak, bermimpi tentang bagaimana memenangkan kompetisi kostum Halloween virtual tahun ini. Namun, beberapa menit kemudian, Anda membaca email dari pelanggan yang menyatakan bahwa layanan aplikasi benar-benar terasa lambat.
Perlakukan #4:Alat pengembang identifikasi bottleneck:Temukan tempat terjadinya pelambatan
Sama seperti pengembang yang dapat menunjukkan hambatan dengan cepat dengan pemantauan dan pencatatan yang diaktifkan di seluruh aplikasi, Anda dapat menggunakan alat pengembang seperti traceroute /tracert , Alat Pengembang browser Chrome, dan Wireshark untuk memecahkan masalah aplikasi dan mengidentifikasi dengan mudah tempat terjadinya masalah kinerja. Mengetahui alat seperti ini dapat membantu pengembang menavigasi masalah menantang yang terkait dengan aplikasi berbasis cloud.

Trik #5:Latensi lambat dilaporkan hanya di satu lokasi

Sebagai seorang master sysadmin, Anda akhirnya menemukan penyebab kelambatan aplikasi secara keseluruhan. Anda memperbaiki masalahnya, dan pelanggan kemudian mengirimi Anda surat terima kasih yang menyatakan bahwa semuanya baik-baik saja. Namun, sehari kemudian, Anda mendapatkan email dari pelanggan lain yang berlokasi di Sydney, Australia, yang mengeluh bahwa aplikasi perusahaan Anda terasa lambat saat mengunjungi situs tersebut. Apa yang terjadi?
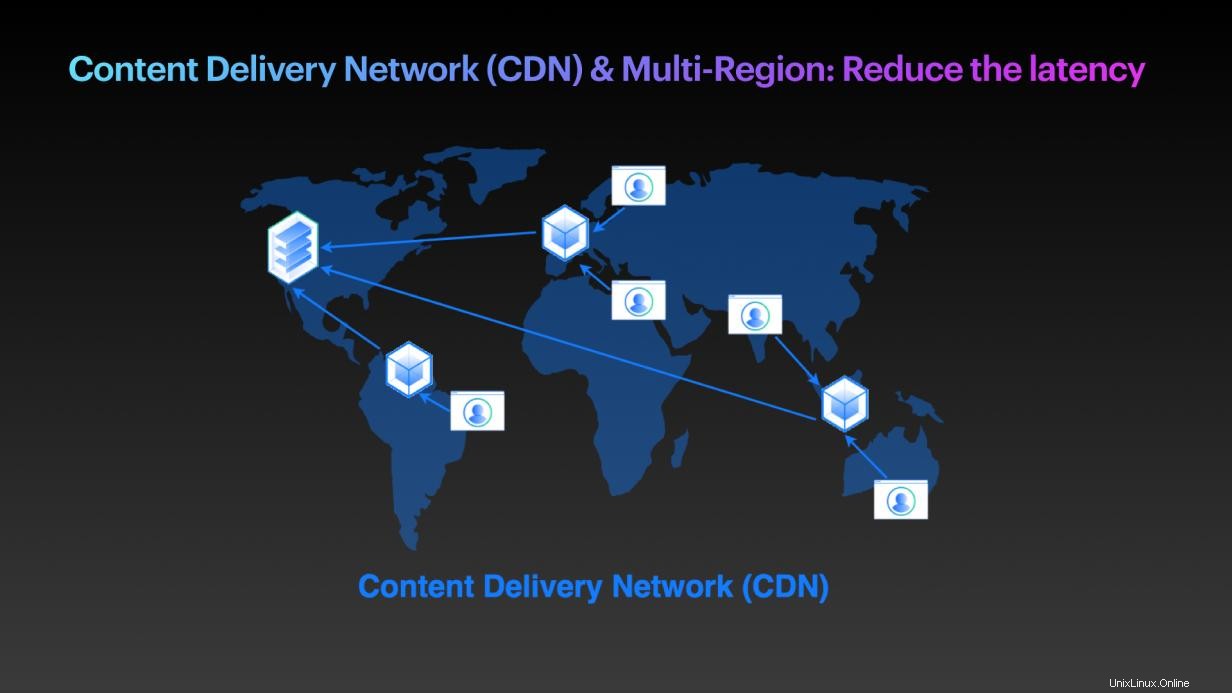
Perlakukan #5:Jaringan Pengiriman Konten (CDN) dan akses multi-wilayah:Kurangi latensi
Meskipun masalahnya masih dapat berupa masalah latensi karena desain aplikasi, masalahnya mungkin karena kurangnya ketersediaan server untuk pelanggan di kota atau wilayah tersebut. Salah satu cara untuk mengatasi masalah tersebut adalah dengan menambahkan lokasi tambahan untuk menjalankan layanan Anda sehingga server terdekat dapat dipilih secara otomatis untuk mengirimkan konten yang diperlukan kepada pelanggan. Dengan kata lain, cluster multi-region dan Content Delivery Network (CDN) dapat membantu mengurangi masalah.
[ Unduh sekarang:Panduan sysadmin untuk skrip Bash. ]
Menutup
Itu saja! Anda telah mempelajari cara mengatasi lima masalah paling umum yang mungkin Anda temui sebagai sysadmin saat Anda menjalankan aplikasi di server atau lingkungan cloud. Masalah seperti ini terjadi setiap saat, tetapi ada cara untuk mencegah atau mengurangi masalah secara tepat dengan arsitektur yang tepat dan pendekatan sysadmin yang baik. Saya harap artikel ini membantu Anda untuk menjadi sysadmin yang lebih baik. Selamat Halloween!