Jika Anda membaca artikel pertama saya tentang menggunakan Keepalive untuk mengelola failover sederhana dalam cluster, maka Anda akan mengingat VRRP menggunakan konsep prioritas saat menentukan server mana yang akan menjadi master aktif. Server dengan prioritas tertinggi "menang" dan akan bertindak sebagai master, memegang permintaan VIP dan servis. Keepalived menyediakan beberapa metode yang berguna untuk menyesuaikan prioritas berdasarkan status sistem Anda. Dalam artikel ini, Anda akan menjelajahi beberapa mekanisme ini, bersama dengan Keepalived kemampuan untuk menjalankan skrip saat status server berubah.
Saya hanya akan menunjukkan konfigurasi pada server1 untuk contoh-contoh ini. Pada titik ini, Anda mungkin merasa nyaman dengan konfigurasi yang diperlukan di server2 jika Anda telah membaca keseluruhan seri. Jika tidak, luangkan waktu untuk meninjau artikel pertama dan kedua dari seri ini sebelum melanjutkan.
- Menggunakan Keepalive untuk mengelola failover sederhana dalam kluster
- Menyiapkan cluster Linux dengan Keepalive:Konfigurasi dasar
Simbol jaringan dalam diagram tersedia melalui VRT Network Equipment Extension, CC BY-SA 3.0.
Keepalived melakukan pekerjaan yang baik dalam memicu failover ketika iklan tidak diterima, seperti ketika master aktif mati sepenuhnya atau tidak dapat dijangkau karena alasan lain. Namun, Anda akan sering menemukan bahwa mekanisme pemicu yang lebih halus diperlukan. Misalnya, aplikasi Anda mungkin menjalankan health check-nya sendiri untuk menentukan kemampuan aplikasi dalam melayani permintaan klien. Anda tidak ingin server aplikasi yang tidak sehat tetap menjadi master aktif hanya karena masih hidup dan mengirimkan VRRP iklan.
Catatan:Saya menemukan bahwa versi Keepalived tersedia melalui repositori paket standar yang berisi bug yang mencegah beberapa contoh di bawah ini bekerja dengan benar. Jika Anda mengalami masalah, Anda mungkin ingin menginstal Keepalived dari sumber, seperti yang dijelaskan dalam artikel sebelumnya.
Proses pelacakan
Salah satu yang paling umum Keepalived setup melibatkan pelacakan proses di server untuk menentukan kesehatan host. Misalnya, Anda mungkin menyiapkan sepasang server web yang sangat tersedia dan memicu failover jika Apache berhenti berjalan di salah satunya.
Keepalived membuatnya mudah melalui track_process arahan konfigurasi. Pada contoh di bawah ini, saya telah menyiapkan Keepalived untuk melihat httpd proses dengan bobot 10. Selama httpd sedang berjalan, prioritas yang diiklankan adalah 254 (244 + 10 =254). Jika httpd berhenti berjalan, maka prioritas akan turun ke 244 dan memicu failover (dengan asumsi bahwa konfigurasi serupa ada di server2).
server1# cat keepalived.conf
vrrp_track_process track_apache {
process httpd
weight 10
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_process {
track_apache
}
} Dengan konfigurasi ini (dan Apache diinstal dan dijalankan di kedua server), Anda dapat menguji skenario failover dengan menghentikan Apache dan melihat perpindahan VIP dari server1 ke server2:
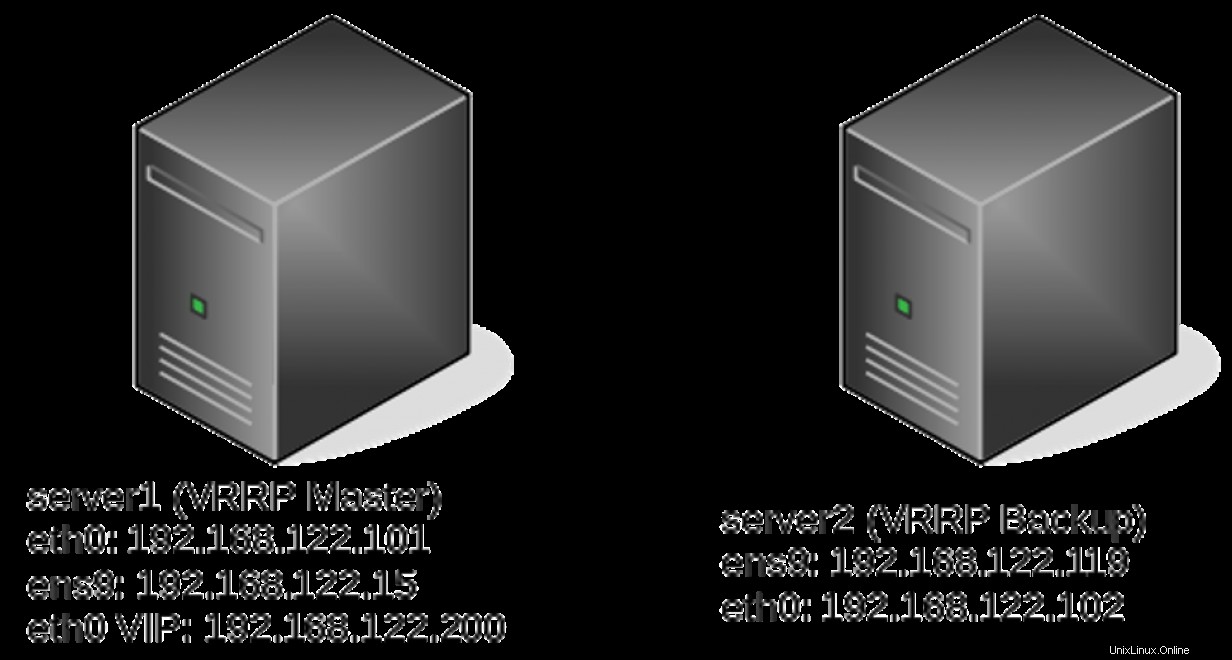
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64
server1# systemctl stop httpd
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
server2# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.102/24 192.168.122.200/24 fe80::5054:ff:fe04:2c5d/64 Melacak file
Keepalived juga memiliki kemampuan untuk membuat keputusan prioritas berdasarkan konten file, yang dapat berguna jika Anda menjalankan aplikasi yang dapat menulis nilai ke file ini. Misalnya, Anda mungkin memiliki proses latar belakang di aplikasi Anda yang secara berkala melakukan health check dan menulis nilai ke file berdasarkan kesehatan aplikasi secara keseluruhan.
Keepalived halaman manual menjelaskan bahwa pelacakan file didasarkan pada bobot yang dikonfigurasi untuk file:
“nilai akan dibaca sebagai angka dalam teks dari file. Jika bobot yang dikonfigurasi terhadap track_file adalah 0, nilai bukan nol dalam file akan diperlakukan sebagai status gagal, dan nilai nol akan diperlakukan sebagai status OK, jika tidak, nilainya akan dikalikan dengan bobot yang dikonfigurasi di pernyataan track_file. Jika hasilnya kurang dari -253 instance VRRP atau grup sinkronisasi apa pun yang memantau skrip akan bertransisi ke status kesalahan (bobotnya bisa 254 untuk memungkinkan nilai negatif dibaca dari file).”
Saya akan menjaga semuanya tetap sederhana dan menggunakan bobot 1 untuk file trek dalam contoh ini. Konfigurasi ini akan mengambil nilai numerik dalam file di /var/run/my_app/vrrp_track_file dan kalikan dengan 1.
server1# cat keepalived.conf
vrrp_track_file track_app_file {
file /var/run/my_app/vrrp_track_file
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_file {
track_app_file weight 1
}
}
Anda sekarang dapat membuat file dengan nilai awal dan memulai ulang Keepalived . Prioritas dapat dilihat di tcpdump output, seperti yang dibahas dalam artikel kedua dari seri ini.
server1# mkdir /var/run/my_app
server1# echo 5 > /var/run/my_app/vrrp_track_file
server1# systemctl restart keepalived
server1# tcpdump proto 112
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
16:19:32.191562 IP server1 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 249, authtype simple, intvl 1s, length 20 Anda dapat melihat bahwa prioritas yang diiklankan adalah 249, yang merupakan nilai dalam file (5) dikalikan dengan bobot (1) dan ditambahkan ke prioritas dasar (244). Demikian pula, menyesuaikan prioritas ke 6 akan meningkatkan prioritas:
server1# echo 6 > /var/run/my_app/vrrp_track_file
server1# tcpdump proto 112
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
16:20:43.214940 IP server1 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 250, authtype simple, intvl 1s, length 20 Lacak antarmuka
Untuk server dengan banyak antarmuka, akan berguna untuk menyesuaikan prioritas Keepalived instance berdasarkan status antarmuka. Misalnya, penyeimbang beban dengan VIP frontend dan koneksi backend ke jaringan internal mungkin ingin memicu Keepalived failover jika koneksi ke jaringan backend terputus. Ini dapat dilakukan dengan konfigurasi track_interface:
server1# cat keepalived.conf
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_interface {
ens9 weight 5
}
} Konfigurasi di atas memberikan bobot 5 ke status antarmuka ens9. Ini akan menyebabkan server1 mengambil prioritas 249 (244 + 5 =249) selama ens9 aktif. Jika ens9 turun, maka prioritas akan turun ke 244 (dan memicu failover, dengan asumsi bahwa server2 dikonfigurasi dengan cara yang sama). Anda dapat menguji ini di server multi-antarmuka dengan mematikan antarmuka dan melihat perpindahan VIP antar host:
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64
ens9 UP 192.168.122.15/24 fe80::7444:5ec4:8015:722f/64
server1# ip link set ens9 down
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
ens9 DOWN
server2# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
ens9 UP 192.168.122.119/24 fe80::fc9f:8999:b93e:d491/64
eth0 UP 192.168.122.102/24 192.168.122.200/24 fe80::5054:ff:fe04:2c5d/64 Skrip lacak
Anda telah melihat bahwa Keepalived menawarkan banyak metode pemeriksaan bawaan yang berguna untuk menentukan kesehatan dan VRRP subsequent selanjutnya prioritas tuan rumah. Namun, terkadang lingkungan yang lebih kompleks memerlukan penggunaan perkakas khusus, seperti skrip pemeriksaan kesehatan, untuk memenuhi kebutuhan mereka. Untungnya, Keepalived juga memiliki kemampuan untuk menjalankan skrip arbitrer untuk menentukan kesehatan host. Anda dapat menyesuaikan bobot skrip, tetapi saya akan menyederhanakannya untuk contoh ini:skrip yang mengembalikan 0 akan menunjukkan keberhasilan, sedangkan skrip yang mengembalikan apa pun akan menunjukkan bahwa Keepalived instance harus memasuki status kesalahan.
Skripnya adalah ping sederhana ke 8.8.8.8 favorit semua orang Server DNS Google, seperti yang terlihat di bawah ini. Di lingkungan Anda, kemungkinan besar Anda akan menggunakan skrip yang lebih kompleks untuk melakukan pemeriksaan kesehatan apa pun yang Anda perlukan.
server1# cat /usr/local/bin/keepalived_check.sh
#!/bin/bash
/usr/bin/ping -c 1 -W 1 8.8.8.8 > /dev/null 2>&1
Anda akan melihat bahwa saya menggunakan batas waktu 1 detik untuk ping (-W 1). Saat menulis Keepalived periksa skrip, ada baiknya untuk membuatnya tetap ringan dan cepat. Anda tidak ingin server yang rusak tetap menjadi master untuk waktu yang lama karena skrip Anda lambat.
Keepalived konfigurasi untuk skrip cek ditunjukkan di bawah ini:
server1# cat keepalived.conf
vrrp_script keepalived_check {
script "/usr/local/bin/keepalived_check.sh"
interval 1
timeout 5
rise 3
fall 3
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_script {
keepalived_check
}
}
Ini sangat mirip dengan konfigurasi yang telah Anda kerjakan, tetapi vrrp_script blok memiliki beberapa arahan unik:
interval:Seberapa sering skrip harus dijalankan (1 detik).timeout:Berapa lama menunggu skrip kembali (5 detik).rise:Berapa kali skrip harus kembali dengan sukses agar host dianggap "sehat". Dalam contoh ini, skrip harus berhasil kembali 3 kali. Ini membantu mencegah kondisi "mengepak" di mana satu kegagalan (atau keberhasilan) menyebabkanKeepalivednegara untuk membalik bolak-balik dengan cepat.fall:Berapa kali skrip harus dikembalikan dengan tidak berhasil (atau time out) agar host dianggap “tidak sehat”. Ini berfungsi sebagai kebalikan dari direktif naik.
Anda dapat menguji konfigurasi ini dengan memaksa skrip gagal. Pada contoh di bawah ini, saya menambahkan iptables aturan yang mencegah komunikasi dengan 8.8.8.8 . Ini menyebabkan pemeriksaan kesehatan gagal dan VIP menghilang setelah beberapa detik. Saya kemudian dapat menghapus aturan dan melihat VIP muncul kembali.
server1# iptables -I OUTPUT -d 8.8.8.8 -j DROP
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
server1# iptables -D OUTPUT -d 8.8.8.8 -j DROP
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64
Kiat singkat tentang skrip di Keepalived :Mereka dapat dijalankan sebagai pengguna yang berbeda selain root. Meskipun saya tidak menunjukkannya dalam contoh ini, lihat halaman manual dan pastikan bahwa Anda menggunakan pengguna yang paling tidak memiliki hak istimewa untuk menghindari implikasi keamanan negatif dari skrip pemeriksaan Anda.
Beri tahu skrip
Saya telah mendiskusikan cara untuk memicu Keepalived tanggapan berdasarkan kondisi eksternal. Namun, Anda mungkin juga ingin memicu tindakan saat Keepalived transisi dari satu keadaan ke keadaan lain. Misalnya, Anda mungkin ingin menghentikan layanan saat Keepalived memasuki status pencadangan, atau Anda mungkin ingin mengirim email ke administrator. Keepalived memungkinkan Anda melakukan ini dengan skrip notifikasi.
Keepalived menyediakan beberapa perintah pemberitahuan untuk hanya memanggil skrip pada status tertentu (notify_master , notify_backup , dll), tapi saya akan fokus pada notify bare direktif karena ini adalah yang paling fleksibel. Saat skrip di notify direktif dipanggil, ia menerima empat argumen tambahan (setelah argumen apa pun yang diteruskan ke skrip itu sendiri).
Diurutkan secara berurutan, yaitu:
- Grup atau instance:Indikasi apakah notifikasi dipicu oleh
VRRPgrup (tidak dibahas dalam seri ini) atauVRRPtertentu contoh. - Nama grup atau instance
- Menyatakan bahwa grup atau instance sedang bertransisi ke
- Prioritas
Melihat contoh membuat ini lebih jelas. Skrip dan Keepalived konfigurasinya seperti ini:
server1# cat /usr/local/bin/keepalived_notify.sh
#!/bin/bash
echo "$1 $2 has transitioned to the $3 state with a priority of $4" > /var/run/keepalived_status
server1# cat keepalived.conf
vrrp_script keepalived_check {
script "/usr/local/bin/keepalived_check.sh"
interval 1
timeout 5
rise 3
fall 3
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_script {
keepalived_check
}
notify "/usr/local/bin/keepalived_notify.sh"
}
Konfigurasi di atas akan memanggil /usr/local/bin/keepalived_notify.sh skrip setiap kali Keepalived transisi keadaan terjadi. Karena skrip pemeriksaan yang sama ada, Anda dapat dengan mudah memeriksa status awal dan kemudian memicu transisi:
server1# cat /var/run/keepalived_status
INSTANCE VI_1 has transitioned to the MASTER state with a priority of 244
server1# iptables -A OUTPUT -d 8.8.8.8 -j DROP
server1# cat /var/run/keepalived_status
INSTANCE VI_1 has transitioned to the FAULT state with a priority of 244
server1# iptables -D OUTPUT -d 8.8.8.8 -j DROP
server1# cat /var/run/keepalived_status
INSTANCE VI_1 has transitioned to the MASTER state with a priority of 244
Anda dapat melihat bahwa argumen baris perintah sesuai dengan yang saya jelaskan di awal bagian ini. Jelas ini adalah contoh sederhana, tetapi skrip notifikasi dapat melakukan banyak tindakan kompleks, seperti menyesuaikan aturan perutean atau memicu skrip lain. Mereka adalah cara yang berguna untuk mengambil tindakan eksternal berdasarkan Keepalived perubahan status.
Menutup
Artikel ini menutup Keepalived yang mendasar seri dengan beberapa konsep lanjutan. Anda telah mempelajari cara memicu Keepalived prioritas dan perubahan status berdasarkan peristiwa eksternal, seperti status proses, perubahan antarmuka, dan bahkan hasil skrip eksternal. Anda juga mempelajari cara memicu skrip pemberitahuan sebagai tanggapan terhadap Keepalived perubahan negara. Anda dapat menggabungkan dua atau lebih pendekatan ini untuk membangun sepasang server Linux yang sangat tersedia yang merespons berbagai rangsangan eksternal dan memastikan bahwa lalu lintas selalu mencapai alamat IP yang sehat yang dapat melayani permintaan klien.
[ Ingin mempelajari lebih lanjut tentang administrasi sistem? Ikuti kursus online gratis:Tinjauan teknis Red Hat Enterprise Linux. ]