Bayangkan Anda memiliki file (atau sekumpulan file) dan Anda ingin mencari string atau pengaturan konfigurasi tertentu di dalam file ini. Membuka setiap file satu per satu dan mencoba menemukan string tertentu akan melelahkan dan mungkin bukan pendekatan yang tepat. Jadi apa yang bisa kita gunakan?
Ada banyak alat yang dapat kita gunakan dalam sistem berbasis *nix untuk menemukan dan memanipulasi teks. Pada artikel ini, kita akan membahas grep perintah untuk mencari pola, baik yang ditemukan dalam file atau berasal dari aliran (file atau input yang berasal dari pipa, atau | ). Dalam artikel mendatang, kita juga akan melihat cara menggunakan sed (Stream Editor) untuk memanipulasi aliran.
Cara terbaik untuk memahami cara kerja suatu program atau utilitas adalah dengan melihat halaman manualnya. Banyak (jika tidak semua) alat Unix menyediakan halaman manual selama instalasi. Pada sistem berbasis Linux Red Hat Enterprise, kita dapat menjalankan yang berikut ini untuk membuat daftar grep file dokumentasi ':
$ rpm -qd grep
/usr/share/doc/grep/AUTHORS
/usr/share/doc/grep/NEWS
/usr/share/doc/grep/README
/usr/share/doc/grep/THANKS
/usr/share/doc/grep/TODO
/usr/share/info/grep.info.gz
/usr/share/man/man1/egrep.1.gz
/usr/share/man/man1/fgrep.1.gz
Dengan halaman manual yang kita miliki, sekarang kita dapat menggunakan grep dan jelajahi opsinya.
grep dasar
Selama bagian artikel ini, kami menggunakan words file, yang dapat Anda temukan di lokasi berikut:
$ ls -l /usr/share/dict/words
lrwxrwxrwx. 1 root root 11 Feb 3 2019 /usr/share/dict/words -> linux.words
File ini berisi 479.826 kata dan disediakan oleh words kemasan. Di sistem Fedora saya, paket itu adalah words-3.0-33.fc30.noarch . Ketika kita membuat daftar isi dari words file, kita melihat output berikut:
$ cat /usr/share/dict/words
1080
10-point
10th
11-point
[……]
[……]
zyzzyva
zyzzyvas
ZZ
Zz
zZt
ZZZ
Oke, jadi kami mengucapkan words file berisi 479.826 baris, tetapi bagaimana kita tahu itu? Ingat, kita berbicara tentang halaman manual sebelumnya. Mari kita lihat apakah grep menawarkan opsi untuk menghitung baris dalam file tertentu.
Ironisnya, kami akan menggunakan grep untuk mengambil opsi sebagai berikut:

Jadi, kita jelas membutuhkan -c , atau opsi panjang --count , untuk menghitung jumlah baris dalam file tertentu. Menghitung baris dalam /usr/share/dict/words hasil:
$ grep -c '.' /usr/share/dict/words
479826
'.' artinya kita akan menghitung semua baris yang mengandung setidaknya satu karakter, spasi, blank, tab, dll.
grep dasar regex
grep perintah menjadi lebih kuat ketika kita menggunakan ekspresi reguler (regex). Jadi, sementara kita fokus pada grep perintah itu sendiri, kami juga akan menyentuh sintaks ekspresi reguler dasar.
Mari kita asumsikan bahwa kita hanya tertarik pada kata-kata yang dimulai dengan Z . Situasi ini adalah di mana regex berguna. Kami menggunakan karat (^ ) untuk mencari pola yang dimulai dengan karakter tertentu, yang menunjukkan awal string:
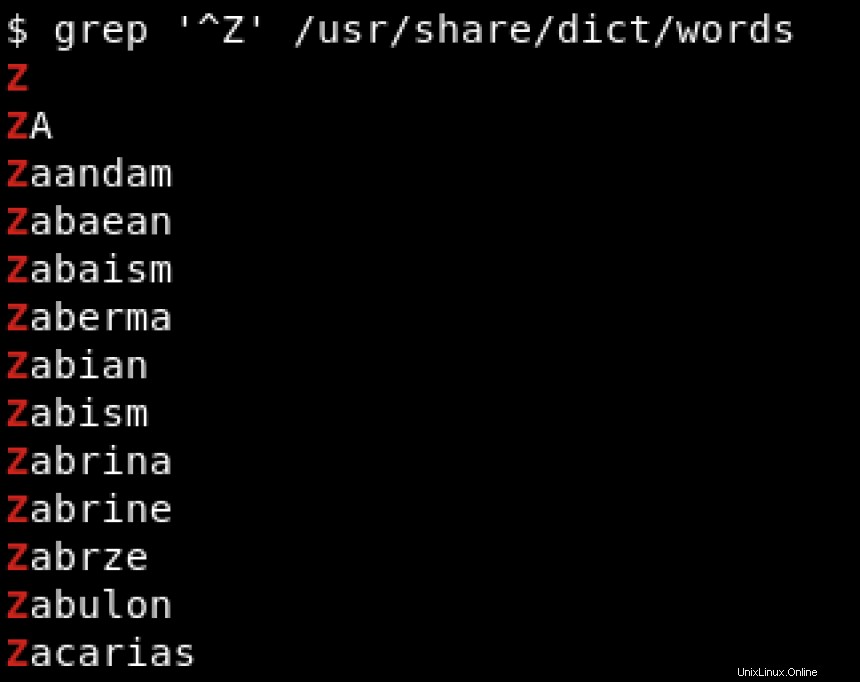
Untuk mencari pola yang diakhiri dengan karakter tertentu, kami menggunakan tanda dolar ($ ) untuk menunjukkan akhir dari string. Lihat contoh di bawah ini tempat kami mencari string yang diakhiri dengan hat :
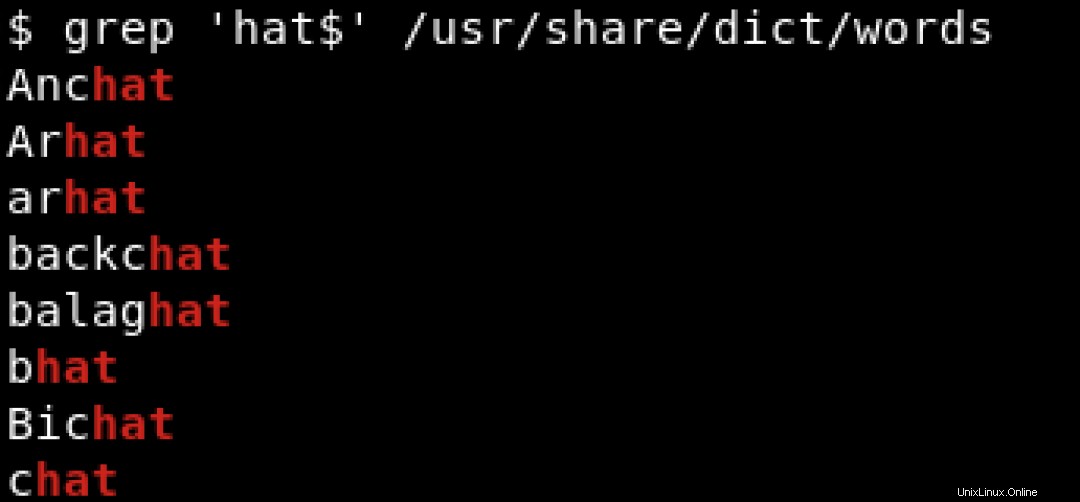
Untuk mencetak semua baris yang mengandung hat terlepas dari posisinya, apakah di awal baris atau di akhir baris, kami akan menggunakan sesuatu seperti:
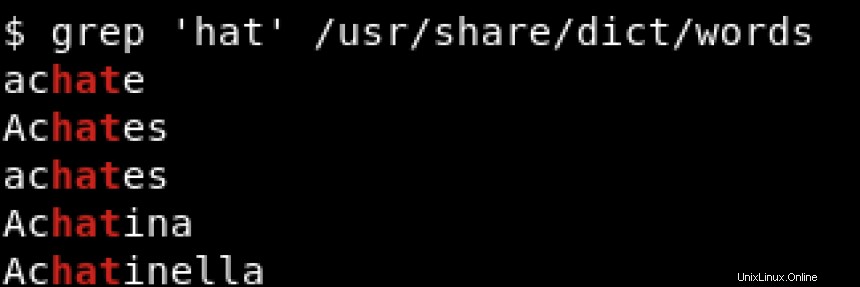
^ dan $ disebut metakarakter dan harus diloloskan dengan garis miring terbalik (\ ) ketika kita ingin mencocokkan karakter ini secara harfiah. Jika Anda ingin tahu lebih banyak tentang metakarakter, lihat https://www.regular-expressions.info/characters.html.
Contoh:Hapus komentar
Sekarang kita telah menggores permukaan grep , mari kita kerjakan beberapa skenario dunia nyata. Banyak file konfigurasi di *nix berisi komentar, yang menjelaskan pengaturan berbeda di dalam file konfigurasi. /etc/fstab , file misalnya, memiliki:
$ cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Thu Oct 27 05:06:06 2016
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/VGCRYPTO-ROOT / ext4 defaults,x-systemd.device-timeout=0 1 1
UUID=e9de0f73-ddddd-4d45-a9ba-1ffffa /boot ext4 defaults 1 2
LABEL=SSD_SWAP swap swap defaults 0 0
#/dev/mapper/VGCRYPTO-SWAP swap swap defaults,x-systemd.device-timeout=0 0 0
Komentar ditandai dengan hash (# ), dan kami ingin mengabaikannya saat dicetak. Salah satu opsi adalah cat perintah:
$ cat /etc/fstab | grep -v '^#'
Namun, Anda tidak perlu cat di sini (hindari Penggunaan Cat yang Tidak Berguna). grep perintah sangat mampu membaca file, jadi sebagai gantinya, Anda dapat menggunakan sesuatu seperti ini untuk mengabaikan baris yang berisi komentar:
$ grep -v '^#' /etc/fstab
Jika Anda ingin mengirim output (tanpa komentar) ke file lain, gunakan:
$ grep -v '^#' /etc/fstab > ~/fstab_without_comment
Sementara grep dapat memformat output di layar, perintah ini tidak dapat mengubah file di tempat. Untuk melakukan ini, kita memerlukan editor file seperti ed . Di artikel berikutnya, kita akan menggunakan sed untuk mencapai hal yang sama yang kami lakukan di sini dengan grep .
Contoh:Hapus komentar dan baris kosong
Saat kami masih menggunakan grep , mari kita periksa /etc/sudoers mengajukan. File ini berisi banyak komentar, tetapi kami hanya tertarik pada baris yang tidak memiliki komentar, dan kami juga ingin menghapus baris yang kosong.
Jadi, pertama, mari kita hapus baris yang berisi komentar. Output berikut dihasilkan:
# grep -v '^#' /etc/sudoers
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
Sekarang, kami ingin menyingkirkan baris kosong (kosong). Nah, itu mudah, jalankan grep yang lain perintah:
# grep -v '^#' /etc/sudoers | grep -v '^$'
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
valentin.local ALL=NOPASSWD: /usr/bin/updatedb
Bisakah kita melakukan yang lebih baik? Bisakah kita menjalankan grep perintah untuk menjadi lebih ramah sumber daya dan tidak bercabang grep dua kali? Kita pasti bisa:
# grep -Ev '^#|^$' /etc/sudoers
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
valentin.local ALL=NOPASSWD: /usr/bin/updatedb
Di sini kami memperkenalkan grep lainnya pilihan, -E (atau --extended-regexp ) <PATTERN> adalah ekspresi reguler yang diperluas.
Contoh:Cetak saja /etc/passwd pengguna
Jelas bahwa grep sangat kuat bila digunakan dengan regex. Artikel ini hanya mencakup sebagian kecil dari apa yang grep benar-benar mampu. Untuk mendemonstrasikan kemampuan grep dan penggunaan ekspresi reguler, kami akan mengurai /etc/passwd file dan cetak hanya nama pengguna.
Format /etc/passwd filenya sebagai berikut:
$ head /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
Kolom di atas memiliki arti sebagai berikut:
<name>:<password>:<UID>:<GID>:<GECOS>:<directory>:<shell>
Lihat man 5 passwd untuk informasi lebih lanjut tentang /etc/passwd mengajukan. Untuk mencetak nama pengguna saja, kita bisa menggunakan sesuatu seperti berikut:
$ grep -Eo '^[a-zA-Z_-]+' /etc/passwd
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
operator
Dalam grep di atas perintah, kami memperkenalkan opsi lain:-o (atau --only-matching ) untuk hanya menampilkan bagian dari pencocokan baris <PATTERN> . Kemudian, kami menggabungkan -Eo untuk mendapatkan hasil yang diinginkan.
Kami sekarang akan memecah perintah di atas sehingga kami dapat lebih memahami apa yang sebenarnya terjadi. Dari kiri ke kanan:
^cocok di awal baris.[a-zA-Z_-]disebut kelas karakter, dan cocok dengan satu karakter yang cocok dengan daftar yang disertakan.+adalah quantifier yang cocok antara satu dan jumlah yang tidak terbatas.
Ekspresi reguler di atas akan berulang hingga mencapai karakter yang tidak cocok. Baris pertama file adalah:
root:x:0:0:root:/root:/bin/bash
Ini diproses sebagai berikut:
- Karakter pertama adalah
r, jadi dicocokkan dengan[a-z]. +pindah ke karakter berikutnya.- Karakter kedua adalah
odan ini dicocokkan dengan[a-z]. +pindah ke karakter berikutnya.
Urutan ini berulang sampai kita menekan titik dua (: ). Kelas karakter [a-zA-Z_-] tidak cocok dengan : simbol, jadi grep pindah ke baris berikutnya.
Karena nama pengguna di passwd file semua huruf kecil, kita juga bisa menyederhanakan kelas karakter kita sebagai berikut, dan tetap mendapatkan hasil yang diinginkan:
$ grep -Eo '^[a-z_-]+' /etc/passwd
Contoh:Temukan proses
Saat menggunakan ps untuk memahami suatu proses, kita sering menggunakan sesuatu seperti:
$ ps aux | grep ‘thunderbird’
Tapi ps perintah tidak hanya akan mencantumkan thunderbird proses. Itu juga mencantumkan grep perintah yang baru saja kami jalankan, karena grep juga berjalan setelah pipa dan ditampilkan dalam daftar proses:
$ ps aux | grep thunderbird
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
val+ 14064 0.0 0.0 57 82 pts/2 S+ 21:12 0:00 grep --color=auto thunderbird
Kita bisa mengatasinya dengan menambahkan grep -v grep untuk mengecualikan grep dari keluaran:
$ ps aux | grep thunderbird | grep -v grep
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
Saat menggunakan grep -v grep akan melakukan apa yang kita inginkan, ada cara yang lebih baik untuk mencapai hasil yang sama tanpa mengeluarkan grep . baru proses:
$ ps aux | grep [t]hunderbird
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
[t]hunderbird di sini cocok dengan t liter literal , dan peka huruf besar/kecil. Itu tidak akan cocok dengan grep , dan itulah sebabnya kami sekarang hanya melihat thunderbird dalam keluaran.
Contoh ini hanyalah demonstrasi tentang betapa fleksibelnya grep adalah, tidak akan membantu Anda memecahkan masalah pohon proses Anda. Ada alat yang lebih cocok untuk tujuan ini, seperti pgrep .
Penutup
Gunakan grep ketika Anda ingin mencari pola, baik dalam file atau beberapa direktori secara rekursif. Coba pahami cara kerja ekspresi reguler saat grep , karena regex bisa menjadi kuat.
[Ingin mencoba Red Hat Enterprise Linux? Unduh sekarang secara gratis.]