Kubernetes adalah platform open source untuk mengelola beban kerja dan layanan dalam container yang memfasilitasi konfigurasi dan otomatisasi deklaratif. Nama Kubernetes berasal dari bahasa Yunani, yang berarti juru mudi atau pilot. Ini portabel serta dapat diperluas dan memiliki ekosistem yang berkembang pesat. Layanan dan alat Kubernetes tersedia secara luas.
Dalam artikel ini, kita akan membahas komponen utama Kubernetes setinggi 10.000 kaki, mulai dari komposisi setiap container, hingga cara container dalam pod di-deploy dan dijadwalkan di setiap pekerja. Sangat penting untuk memahami detail lengkap dari cluster Kubernetes agar dapat menerapkan dan merancang solusi berdasarkan Kubernetes sebagai orkestra untuk aplikasi dalam container.
Berikut adalah penjelasan singkat mengenai hal-hal yang akan kita bahas dalam artikel ini:
- Komponen panel kontrol
- Komponen pekerja Kubernetes
- Pod sebagai blok bangunan dasar
- Layanan Kubernetes, penyeimbang beban, dan pengontrol Ingress
- Penerapan Kubernetes dan Set Daemon
- Penyimpanan persisten di Kubernetes
Pesawat Kontrol Kubernetes
Node master Kubernetes adalah tempat layanan bidang kontrol inti berada; tidak semua layanan harus berada di node yang sama; namun, untuk sentralisasi dan kepraktisan, mereka sering digunakan dengan cara ini. Hal ini jelas menimbulkan pertanyaan tentang ketersediaan layanan; namun, masalah tersebut dapat dengan mudah diatasi dengan memiliki beberapa node dan menyediakan permintaan load balancing untuk mencapai kumpulan master node yang sangat tersedia. .
Node master terdiri dari empat layanan dasar:
- Kube-apiserver
- Penjadwal kube
- Manajer-pengendali-kube
- Database dll
Node master dapat berjalan di server bare metal, mesin virtual, atau cloud pribadi atau publik, tetapi tidak disarankan untuk menjalankan beban kerja container pada node tersebut. Kita akan melihat lebih banyak tentang ini nanti.
Diagram berikut menunjukkan komponen node master Kubernetes:
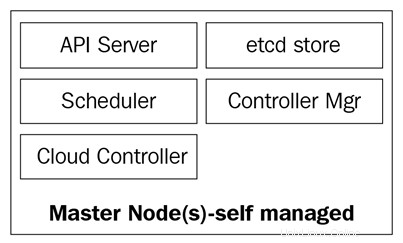
Kube-apiserver
Server API adalah yang mengikat semuanya bersama. Ini adalah REST API frontend dari cluster yang menerima manifes untuk membuat, memperbarui, dan menghapus objek API seperti layanan, pod, Ingress, dan lainnya.
Kube-apiserver adalah satu-satunya layanan yang harus kita ajak bicara; itu juga satu-satunya yang menulis dan berbicara ke database etcd untuk mendaftarkan status cluster. Dengan perintah kubectl, kami akan mengirimkan perintah untuk berinteraksi dengannya. Ini akan menjadi pisau Swiss Army kami untuk Kubernetes.
Kube-controller-manager
Singkatnya, daemon kube-controller-manager adalah kumpulan loop kontrol tak terbatas yang dikirimkan untuk kemudahan dalam satu biner. Ini mengawasi keadaan cluster yang diinginkan dan memastikan bahwa itu dicapai dan dipenuhi dengan memindahkan semua bit dan potongan yang diperlukan untuk mencapainya. Kube-controller-manager bukan hanya satu pengontrol; itu berisi beberapa loop berbeda yang menonton komponen berbeda di cluster. Beberapa di antaranya adalah pengontrol layanan, pengontrol namespace, pengontrol akun layanan, dan banyak lainnya. Anda dapat menemukan setiap pengontrol dan definisinya di repositori GitHub Kubernetes:https://github.com/kubernetes/kubernetes/tree/master/pkg/controller.
Kube-scheduler
Kube-scheduler menjadwalkan pod yang baru dibuat ke node dengan ruang yang cukup untuk memenuhi kebutuhan sumber daya pod. Ini pada dasarnya mendengarkan kube-apiserver dan kube-controller-manager untuk pod yang baru dibuat yang dimasukkan ke dalam antrian dan kemudian dijadwalkan ke node yang tersedia oleh penjadwal. Definisi kube-scheduler dapat ditemukan di sini:https://github.com/kubernetes/kubernetes/blob/master/pkg/scheduler.
Selain sumber daya komputasi, kube-scheduler juga membaca aturan afinitas dan anti-afinitas node untuk mengetahui apakah sebuah node dapat atau tidak dapat menjalankan pod tersebut.
Database etcd
Database etcd adalah penyimpanan nilai kunci yang sangat andal dan konsisten yang digunakan untuk menyimpan status cluster Kubernetes. Ini berisi status pod saat ini di mana node berjalan, berapa banyak node yang dimiliki cluster saat ini, bagaimana status node tersebut, berapa banyak replika penerapan yang berjalan, nama layanan, dan lain-lain.
Seperti yang kami sebutkan sebelumnya, hanya kube-apiserver yang berbicara dengan database etcd. Jika kube-controller-manager perlu memeriksa status kluster, cluster akan melalui server API untuk mendapatkan status dari database etcd, alih-alih melakukan kueri ke penyimpanan etcd secara langsung. Hal yang sama terjadi pada kube-scheduler jika penjadwal perlu memberitahukan bahwa sebuah pod telah dihentikan atau dialokasikan ke node lain; itu akan menginformasikan server API, dan server API akan menyimpan status saat ini di database etcd.
Dengan etcd, kami telah membahas semua komponen utama untuk node master Kubernetes kami sehingga kami siap untuk mengelola cluster kami. Tapi sebuah cluster tidak hanya terdiri dari master; kami masih membutuhkan node yang akan melakukan pekerjaan berat dengan menjalankan aplikasi kami.
Node Pekerja Kubernetes
Node pekerja yang melakukan tugas ini di Kubernetes disebut node. Sebelumnya, sekitar tahun 2014, mereka disebut antek, tetapi istilah ini kemudian diganti hanya dengan node, karena nama tersebut membingungkan dengan istilah Salt dan membuat orang berpikir bahwa Salt memainkan peran utama di Kubernetes.
Node ini adalah satu-satunya tempat Anda akan menjalankan beban kerja, karena penampung atau pemuatan tidak direkomendasikan pada node master karena harus tersedia untuk mengelola seluruh cluster. Node sangat sederhana dalam hal komponen; mereka hanya membutuhkan tiga layanan untuk memenuhi tugas mereka:
- Kubelet
- Kube-proxy
- Waktu proses penampung
Mari kita jelajahi ketiga komponen ini sedikit lebih dalam.
Kubelet
Kubelet adalah komponen Kubernetes tingkat rendah dan salah satu yang paling penting setelah kube-apiserver; kedua komponen ini penting untuk penyediaan pod/kontainer di cluster. Kubelet adalah layanan yang berjalan pada node Kubernetes dan mendengarkan server API untuk pembuatan pod. Kubelet hanya bertugas untuk memulai/menghentikan dan memastikan container dalam pod dalam keadaan sehat; kubelet tidak akan dapat mengelola container apa pun yang tidak dibuat olehnya.
Kubelet mencapai tujuan dengan berbicara ke runtime container melalui antarmuka runtime container (CRI) . CRI menyediakan pluggability ke kubelet melalui klien gRPC, yang dapat berbicara dengan runtime container yang berbeda. Seperti yang kami sebutkan sebelumnya, Kubernetes mendukung beberapa runtime container untuk men-deploy container, dan inilah cara Kubernetes mencapai dukungan yang beragam untuk mesin yang berbeda.
Anda dapat memeriksa kode sumber kubelet melalui https://github.com/kubernetes/kubernetes/tree/master/pkg/kubelet.
Kube-proxy
Kube-proxy adalah layanan yang berada di setiap node cluster dan merupakan layanan yang memungkinkan komunikasi antara pod, container, dan node. Layanan ini mengawasi kube-apiserver untuk melihat perubahan pada layanan yang ditentukan (layanan adalah semacam penyeimbang beban logis di Kubernetes; kami akan mempelajari layanan lebih dalam nanti di artikel ini) dan menjaga jaringan tetap terbarui melalui aturan iptables yang meneruskan lalu lintas ke titik akhir yang benar. Kube-proxy juga menyiapkan aturan di iptables yang melakukan load balancing acak di seluruh pod di belakang layanan.
Berikut adalah contoh aturan iptables yang dibuat oleh kube-proxy:
-A KUBE-SERVICES -d 10.0.162.61/32 -p tcp -m comment --comment "default/example:has no endpoints" -m tcp --dport 80 -j REJECT --reject-with icmp-port-unreachable
Perhatikan bahwa ini adalah layanan tanpa titik akhir (tidak ada pod di belakangnya).
Waktu proses penampung
Untuk dapat menjalankan container, kami memerlukan container runtime . Ini adalah mesin dasar yang akan membuat container di kernel node untuk menjalankan pod kita. Kubelet akan berbicara dengan runtime ini dan akan memutar atau menghentikan container kita sesuai permintaan.
Saat ini, Kubernetes mendukung runtime container yang sesuai dengan OCI, seperti Docker, rkt, runc, runsc, dan sebagainya.
Anda dapat merujuk ini https://github.com/opencontainers/runtime-spec untuk mempelajari lebih lanjut tentang semua spesifikasi dari halaman OCI Git-Hub.
Sekarang setelah kita menjelajahi semua komponen inti yang membentuk sebuah cluster, sekarang mari kita lihat apa yang dapat dilakukan dengan komponen tersebut dan bagaimana Kubernetes akan membantu kita mengatur dan mengelola aplikasi dalam container.
Objek Kubernetes
Objek Kubernetes persis seperti itu:objek atau abstraksi persisten logis yang akan mewakili status cluster Anda. Andalah yang bertanggung jawab untuk memberi tahu Kubernetes tentang status yang Anda inginkan dari objek tersebut sehingga ia dapat bekerja untuk mempertahankannya dan memastikan bahwa objek tersebut ada.
Untuk membuat objek, ada dua hal yang harus dimiliki:status dan spesifikasinya. Status disediakan oleh Kubernetes, dan ini adalah status objek saat ini. Kubernetes akan mengelola dan memperbarui status tersebut sesuai kebutuhan agar sesuai dengan status yang Anda inginkan. Kolom spek, di sisi lain, adalah apa yang Anda berikan ke Kubernetes, dan adalah apa yang Anda katakan untuk menggambarkan objek yang Anda inginkan. Misalnya, gambar yang Anda inginkan untuk menjalankan penampung, jumlah penampung dari gambar yang ingin Anda jalankan, dan seterusnya.
Setiap objek memiliki kolom spesifikasi khusus untuk jenis tugas yang mereka lakukan, dan Anda akan memberikan spesifikasi ini pada file YAML yang dikirim ke kube-apiserver dengan kubectl, yang mengubahnya menjadi JSON dan mengirimkannya sebagai permintaan API . Kami akan menyelam lebih dalam ke setiap objek dan bidang spesifikasinya nanti di artikel ini.
Berikut adalah contoh YAML yang dikirim ke kubectl:
kucing <
Bidang dasar definisi objek adalah yang pertama, dan bidang ini tidak akan berbeda dari satu objek ke objek lainnya dan sangat jelas. Mari kita lihat sekilas mereka:
Jadi, kami sekarang telah melalui bidang yang paling sering digunakan dan isinya; Anda dapat mempelajari lebih lanjut tentang konvensi Kuberntes API di https://github.com/kubernetes/community/blob/master/contributors/devel/api-conventions.md
Beberapa bidang objek nantinya dapat dimodifikasi setelah objek dibuat, tetapi itu akan tergantung pada objek dan bidang yang ingin Anda ubah.
Berikut ini adalah daftar singkat dari berbagai objek Kubernetes yang dapat Anda buat:
Dan masih banyak lagi.
Mari kita lihat lebih dekat masing-masing item ini.
Pod adalah objek paling dasar di Kubernetes dan juga yang paling penting. Semuanya berputar di sekitar mereka; kita dapat mengatakan bahwa Kubernetes adalah untuk pod! Semua objek lain ada di sini untuk melayani mereka, dan semua tugas yang mereka lakukan adalah membuat pod mencapai status yang Anda inginkan.
Jadi, apa itu pod dan mengapa pod begitu penting?
Pod adalah objek logis yang menjalankan satu atau beberapa container bersama-sama pada namespace jaringan yang sama, komunikasi antar-proses (IPC) yang sama. dan, terkadang, bergantung pada versi Kubernetes, ID proses (PID) yang sama ruang nama. Ini karena merekalah yang akan menjalankan kontainer kami dan karenanya akan menjadi pusat perhatian. Inti dari Kubernetes adalah menjadi orkestra container, dan dengan pod, kami memungkinkan orkestrasi.
Seperti yang kami sebutkan sebelumnya, container di pod yang sama berada dalam "gelembung" tempat mereka dapat berbicara satu sama lain melalui localhost, karena mereka bersifat lokal satu sama lain. Satu container dalam sebuah pod memiliki alamat IP yang sama dengan container lainnya karena container tersebut berbagi namespace jaringan, tetapi dalam banyak kasus, Anda akan menjalankan basis satu-satu, yaitu, satu container per pod . Beberapa container per pod hanya digunakan pada skenario yang sangat spesifik, seperti saat aplikasi membutuhkan helper seperti pendorong data atau proxy yang perlu berkomunikasi secara cepat dan tangguh dengan aplikasi utama.
Cara Anda mendefinisikan pod sama dengan cara Anda melakukannya untuk objek Kubernetes lainnya:melalui YAML yang berisi semua spesifikasi dan definisi pod:
jenis:PodapiVersion:v1metadata:name:hello-podlabels: hello:podspec: containers: - name:hello-container image:alpine args: - echo - "Hello World"
Mari kita lihat definisi pod dasar yang diperlukan di bawah bidang spesifikasi untuk membuat pod kita:
Ini adalah spesifikasi paling dasar yang akan kamu nyatakan pada sebuah pod; spesifikasi lain akan mengharuskan Anda memiliki sedikit lebih banyak pengetahuan latar belakang tentang cara menggunakannya dan bagaimana mereka berinteraksi dengan berbagai objek Kubernetes lainnya. Kami akan mengunjunginya kembali nanti di artikel ini; beberapa di antaranya adalah sebagai berikut:
Untuk melihat pod yang sedang berjalan di cluster Anda, Anda dapat menjalankan kubectl get pods:
[email protected]:~$ kubectl get podsNAME READY STATUS RESTART AGEbusybox 1/1 Berjalan 120 5d
Atau, Anda dapat menjalankan pod kubectl describe pod tanpa menentukan pod apa pun. Ini akan mencetak deskripsi dari setiap pod yang berjalan di cluster. Dalam hal ini, ini hanya akan menjadi pod busybox , karena ini adalah satu-satunya yang sedang berjalan:
[Email Dilindungi]:~ $ Kubectl Jelaskan podsname:Busyboxnespace:DefaultPriority:0PriorityClassName:
Pod bersifat fana. Setelah mati atau dihapus, mereka tidak dapat dipulihkan. IP-nya dan container yang menjalankannya akan hilang; mereka benar-benar fana. Data pada pod yang dipasang sebagai volume mungkin bertahan atau tidak, tergantung pada cara Anda mengaturnya. Jika pod kami mati dan kami kehilangannya, bagaimana kami memastikan bahwa semua layanan mikro kami berjalan? Nah, penerapan adalah jawabannya.
Pod sendiri tidak terlalu berguna karena tidak terlalu efisien untuk menjalankan lebih dari satu instance aplikasi kita dalam satu pod. Penyediaan ratusan salinan aplikasi kita pada pod yang berbeda tanpa memiliki metode untuk mencarinya, semuanya akan menjadi tidak terkendali dengan sangat cepat.
Di sinilah penerapan berperan. Dengan penerapan, kami dapat mengelola pod kami dengan pengontrol. Ini memungkinkan kita untuk tidak hanya memutuskan berapa banyak yang ingin kita jalankan, tetapi kita juga dapat mengelola pembaruan dengan mengubah versi image atau image itu sendiri yang dijalankan oleh container kita. Deployments adalah yang paling sering Anda kerjakan. Dengan penerapan serta pod dan objek lain yang kami sebutkan sebelumnya, mereka memiliki definisi sendiri di dalam file YAML:
apiVersion:apps/v1kind:Deploymentmetadata:name:nginx-deployment labels: deployment:nginxspec:replicas:3 selector: matchLabels: template nginx: metadata: labels: app:nginx image spec: container 1.7.9 port: - containerPort:80
Mari kita mulai mengeksplorasi definisi mereka.
Di awal YAML, kami memiliki kolom yang lebih umum, seperti apiVersion, kind, dan metadata. Namun di bawah spesifikasi di sinilah kita akan menemukan opsi khusus untuk Objek API ini.
Di bawah spesifikasi, kita dapat menambahkan kolom berikut:
Pemilih :Dengan kolom Selector, deployment akan mengetahui pod mana yang akan ditargetkan saat perubahan diterapkan. Ada dua bidang yang akan Anda gunakan di bawah pemilih: matchLabels dan matchExpressions. Dengan matchLabels, pemilih akan menggunakan label pod (key/value pair). Penting untuk diperhatikan bahwa semua label yang Anda tentukan di sini akan DIANDALKAN. Artinya, pod akan mengharuskannya memiliki semua label yang Anda tentukan di bawah matchLabels.
Replika :Ini akan menyatakan jumlah pod yang perlu tetap dijalankan oleh penerapan melalui pengontrol replikasi; misalnya, jika Anda menentukan tiga replika, dan salah satu pod mati, pengontrol replikasi akan melihat spesifikasi replika sebagai status yang diinginkan dan menginformasikan penjadwal untuk menjadwalkan pod baru, karena status saat ini adalah 2 sejak pod mati.
RevisionHistoryLimit :Setiap kali Anda membuat perubahan pada penerapan, perubahan ini disimpan sebagai revisi penerapan, yang nantinya dapat Anda kembalikan ke status sebelumnya atau menyimpan catatan tentang apa yang diubah. Anda dapat melihat histori dengan kubectl rollout histori deployment/
Strategi :Ini akan memungkinkan Anda memutuskan bagaimana Anda ingin menangani pembaruan atau skala pod horizontal. Untuk menimpa default, yaitu rollingUpdate, Anda perlu menulis type key, tempat Anda dapat memilih di antara dua nilai: recreate atau rollingUpdate.
Meskipun membuat ulang adalah cara cepat untuk memperbarui penerapan Anda, ini akan menghapus semua pod dan menggantinya dengan yang baru, tetapi ini menyiratkan bahwa Anda harus mempertimbangkan bahwa waktu henti sistem akan diterapkan untuk jenis strategi ini. RollingUpdate, di sisi lain, lebih lancar dan lebih lambat dan ideal untuk aplikasi stateful yang dapat menyeimbangkan kembali datanya. RollingUpdate membuka pintu untuk dua bidang lagi, yaitu maxSurge dan maxUnavailable.
Yang pertama adalah berapa banyak pod di atas jumlah total yang Anda inginkan saat melakukan pembaruan; misalnya, penerapan dengan 100 pod dan 20% maxSurge akan tumbuh hingga maksimum 120 pod saat memperbarui. Opsi berikutnya akan memungkinkan Anda memilih berapa banyak pod dalam persentase yang ingin Anda bunuh untuk menggantinya dengan yang baru dalam skenario 100 pod. Jika terdapat 20% maxUnavailable, hanya 20 pod yang akan dimatikan dan diganti dengan yang baru sebelum melanjutkan untuk mengganti sisa penerapan.
Templat :Ini hanyalah bidang spesifikasi pod bersarang tempat Anda akan menyertakan semua spesifikasi dan metadata pod yang akan dikelola penerapannya.
Kami telah melihat bahwa, dengan penerapan, kami mengelola pod kami, dan mereka membantu kami mempertahankannya dalam keadaan yang kami inginkan. Semua pod ini masih berada dalam sesuatu yang disebut cluster jaringan , yang merupakan jaringan tertutup di mana hanya komponen cluster Kubernetes yang dapat berbicara satu sama lain, bahkan memiliki rangkaian rentang IP sendiri. Bagaimana kita berbicara dengan pod kita dari luar? Bagaimana kita mencapai aplikasi kita? Di sinilah layanan berperan.
Layanan :
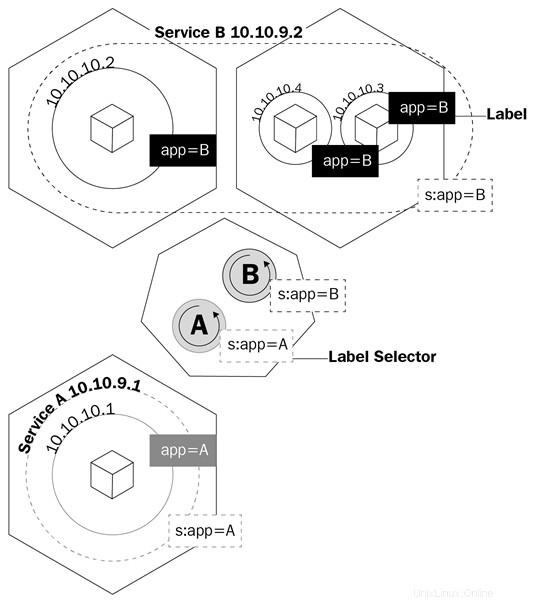
Nama layanan tidak sepenuhnya menjelaskan apa yang sebenarnya dilakukan layanan di Kubernetes. Layanan Kubernetes adalah yang mengarahkan lalu lintas ke pod kami. Kita dapat mengatakan bahwa layanan adalah apa yang mengikat pod bersama-sama.
Mari kita bayangkan bahwa kita memiliki tipe aplikasi frontend/backend yang khas di mana pod frontend kita berbicara dengan pod backend kita melalui alamat IP pod. Jika pod di backend mati, kami kehilangan komunikasi dengan backend kami. Ini bukan hanya karena pod baru tidak akan memiliki alamat IP yang sama dengan pod yang mati, tetapi sekarang kita juga harus mengkonfigurasi ulang aplikasi kita untuk menggunakan alamat IP baru. Masalah ini dan masalah serupa diselesaikan dengan layanan.
Layanan adalah objek logis yang memberi tahu kube-proxy untuk membuat aturan iptables berdasarkan pod mana yang berada di belakang layanan. Layanan mengonfigurasi titik akhirnya, yang merupakan cara pod di belakang layanan dipanggil, dengan cara yang sama seperti penerapan mengetahui pod mana yang harus dikontrol, bidang pemilih, dan label pod.
Diagram ini menunjukkan cara layanan menggunakan label untuk mengelola lalu lintas:
Layanan tidak hanya akan membuat kube-proxy membuat aturan untuk merutekan lalu lintas; itu juga akan memicu sesuatu yang disebut kube-dns.
Kube-dns adalah kumpulan pod dengan kontainer SkyDNS yang berjalan di cluster yang menyediakan server DNS dan forwarder, yang akan membuat record untuk layanan dan terkadang pod untuk kemudahan penggunaan. Setiap kali Anda membuat layanan, data DNS yang mengarah ke alamat IP cluster internal layanan akan dibuat dengan formulir nama-layanan.namespace.svc.cluster.local. Anda dapat mempelajari lebih lanjut tentang spesifikasi DNS Kubernetes di sini: https://github.com/kubernetes/dns/blob/master/docs/specification.md.
Kembali ke contoh kita, sekarang kita hanya perlu mengonfigurasi aplikasi untuk berbicara dengan layanan nama domain yang sepenuhnya memenuhi syarat (FQDN) untuk berbicara dengan pod backend kami. Dengan cara ini, tidak masalah apa alamat IP yang dimiliki pod dan layanan. Jika pod di belakang layanan mati, layanan akan menangani semuanya dengan menggunakan catatan A, karena kami akan dapat memberi tahu frontend kami untuk merutekan semua lalu lintas ke my-svc. Logika layanan akan menangani yang lainnya.
Ada beberapa jenis layanan yang dapat Anda buat setiap kali Anda mendeklarasikan objek yang akan dibuat di Kubernetes. Mari kita lihat mereka untuk melihat mana yang paling cocok untuk jenis pekerjaan yang kita butuhkan:
IP Cluster :Ini adalah layanan default. Setiap kali Anda membuat layanan ClusterIP, itu akan membuat layanan dengan alamat IP internal cluster yang hanya dapat dirutekan di dalam cluster Kubernetes. Tipe ini ideal untuk pod yang hanya perlu berbicara satu sama lain dan tidak keluar dari cluster.
NodePort :Saat Anda membuat jenis layanan ini, secara default port acak dari 30000 ke 32767 akan dialokasikan untuk meneruskan traffic ke pod endpoint layanan. Anda dapat mengganti perilaku ini dengan menentukan port node di array port. Setelah ini ditentukan, Anda akan dapat mengakses pod Anda melalui
LoadBalancer :Sebagian besar waktu, Anda akan menjalankan Kubernetes di penyedia cloud. Jenis LoadBalancer sangat ideal untuk situasi ini, karena Anda akan dapat mengalokasikan alamat IP publik ke layanan Anda melalui API penyedia cloud Anda. Ini adalah layanan yang ideal ketika Anda ingin berkomunikasi dengan pod Anda dari luar cluster Anda. Dengan LoadBalancer, Anda tidak hanya dapat mengalokasikan alamat IP publik tetapi juga, menggunakan Azure, mengalokasikan alamat IP pribadi dari jaringan pribadi virtual Anda. Jadi, Anda dapat berbicara dengan pod Anda dari internet atau secara internal di subnet pribadi Anda.
Mari kita tinjau definisi layanan YAML:
apiVersion:v1kind:Servicemetadata: name:my-servicespec:selector: app:front-end type:NodePort ports: - name:http port:80 targetPort:8080 nodePort:30024 protokol:TCP
YAML layanan sangat sederhana, dan spesifikasinya akan bervariasi, tergantung pada jenis layanan yang Anda buat. Tetapi hal terpenting yang harus Anda perhitungkan adalah definisi port. Mari kita lihat ini:
Meskipun sekarang kami memahami bagaimana kami dapat berkomunikasi dengan pod di cluster kami, kami masih perlu memahami bagaimana kami akan menangani masalah kehilangan data setiap kali pod dihentikan. Di sinilah Persisten Volume (PV ) mulai digunakan.
Penyimpanan yang terus-menerus di dunia kontainer merupakan masalah serius. Satu-satunya penyimpanan yang persisten di seluruh container yang dijalankan adalah lapisan gambar, dan hanya dapat dibaca. Lapisan tempat wadah berjalan adalah baca/tulis, tetapi semua data di lapisan ini dihapus setelah wadah berhenti. Dengan pod, ini sama. Saat sebuah kontainer mati, data yang tertulis di dalamnya akan hilang.
Kubernetes memiliki sekumpulan objek untuk menangani penyimpanan di seluruh pod. Yang pertama akan kita bahas adalah volume.
Volume memecahkan salah satu masalah terbesar dalam hal penyimpanan persisten. Pertama-tama, volume sebenarnya bukan objek, tetapi definisi dari spesifikasi pod. Saat Anda membuat pod, Anda dapat menentukan volume di bawah bidang spesifikasi pod. Kontainer dalam pod ini akan dapat memasang volume pada namespace mount mereka, dan volume akan tersedia di seluruh kontainer yang dimulai ulang atau mogok. Namun, volume diikat ke pod, dan jika pod dihapus, volumenya juga akan hilang. Data pada volume adalah cerita lain; data persistensi akan bergantung pada backend volume tersebut.
Kubernetes mendukung beberapa jenis volume atau sumber volume dan bagaimana mereka dipanggil dalam spesifikasi API, yang berkisar dari peta sistem file dari node lokal, disk virtual penyedia cloud, dan volume yang didukung penyimpanan yang ditentukan perangkat lunak. Mount filesystem lokal adalah yang paling umum yang akan Anda lihat ketika datang ke volume reguler. Penting untuk dicatat bahwa kelemahan menggunakan sistem file node lokal adalah bahwa data tidak akan tersedia di semua node cluster, dan hanya pada node tempat pod dijadwalkan.
Mari kita periksa bagaimana pod dengan volume didefinisikan di YAML:
apiVersion:v1kind:Podmetadata:name:test-pdspec:containers:- image:k8s.gcr.io/test-webserver name:test-container volumeMounts: - mountPath:/test-pd name:test-volume volumes:- name:test-volume hostPath: path:/data type:Directory
Perhatikan bagaimana ada bidang yang disebut volume di bawah spesifikasi lalu ada bidang lain yang disebut volumeMounts.
Bidang pertama (volume) adalah tempat Anda menentukan volume yang ingin Anda buat untuk pod itu. Bidang ini akan selalu memerlukan nama dan kemudian sumber volume. Tergantung pada sumbernya, persyaratannya akan berbeda. Dalam contoh ini, sumbernya adalah hostPath, yang merupakan sistem file lokal node. hostPath mendukung beberapa jenis pemetaan, mulai dari direktori, file, perangkat blok, dan bahkan soket Unix.
Di bawah bidang kedua, volumeMounts, kami memiliki mountPath, di mana Anda menentukan jalur di dalam wadah tempat Anda ingin memasang volume. Parameter nama adalah cara Anda menentukan pod volume mana yang akan digunakan. Ini penting karena Anda dapat menentukan beberapa jenis volume di bawah volume, dan nama akan menjadi satu-satunya cara bagi pod untuk mengetahui yang
Anda dapat mempelajari lebih lanjut tentang berbagai jenis volume di sini https://kubernetes.io/docs/concepts/storage/volumes/#types-of-volumes dan di dokumen referensi Kubernetes API (https://kubernetes.io/docs /reference/generated/kubernetes-api/v1.11/#volume-v1-core).
Memiliki volume mati dengan polong tidak ideal. Kami membutuhkan penyimpanan yang tetap ada, dan begitulah kebutuhan akan PV muncul.
Perbedaan utama antara volume dan PV adalah, tidak seperti volume, PV sebenarnya adalah objek Kubernetes API, jadi Anda dapat mengelolanya satu per satu seperti entitas terpisah, dan karena itu mereka tetap ada bahkan setelah pod dihapus.
Anda mungkin bertanya-tanya mengapa subbagian ini memiliki PV, persisten volume klaim (PVC ), dan kelas penyimpanan semuanya bercampur. Ini karena semuanya bergantung satu sama lain, dan sangat penting untuk memahami bagaimana mereka berinteraksi satu sama lain untuk menyediakan penyimpanan bagi pod kita.
Let's begin with PVs and PVCs. Like volumes, PVs have a storage source, so the same mechanism that volumes have applies here. You will either have a software-defined storage cluster providing a logical unit number (LUN ), a cloud provider giving virtual disks, or even a local filesystem to the Kubernetes node, but here, instead of being called volume sources, they are called persistent volume types instead.
PVs are pretty much like LUNs in a storage array:you create them, but without a mapping; they are just a bunch of allocated storage waiting to be used. PVCs are like LUN mappings:they are backed or bound to a PV and also are what you actually define, relate, and make available to the pod that it can then use for its containers.
The way you use PVCs on pods is exactly the same as with normal volumes. You have two fields:one to specify which PVC you want to use, and the other one to tell the pod on which container to use that PVC.
The YAML for a PVC API object definition should have the following code:
apiVersion:v1kind:PersistentVolumeClaimmetadata:name:gluster-pvc spec:accessModes:- ReadWriteMany resources: requests: storage:1Gi
The YAML for pod should have the following code:
kind:PodapiVersion:v1metadata:name:mypodspec:containers: - name:myfrontend image:nginx volumeMounts: - mountPath:"/mnt/gluster" name:volume volumes: - name:volume persistentVolumeClaim: claimName:gluster-pvc
When a Kubernetes administrator creates PVC, there are two ways that this request is satisfied:
Storage classes are like a way of tiering your storage. You can create a class that provisions slow storage volumes, or another one with hyper-fast SSD drives. However, storage classes are a little bit more complex than just tiering. As we mentioned in the two ways of creating PVC, storage classes are what make dynamic provisioning possible. When working on a cloud environment, you don't want to be manually creating every backend disk for every PV. Storage classes will set up something called a provisioner , which invokes the volume plug-in that's necessary to talk to your cloud provider's API. Every provisioner has its own settings so that it can talk to the specified cloud provider or storage provider.
You can provision storage classes in the following way; this is an example of a storage class using Azure-disk as a disk provisioner:
kind:StorageClassapiVersion:storage.k8s.io/v1metadata:name:my-storage-classprovisioner:kubernetes.io/azure-diskparameters:storageaccounttype:Standard_LRS kind:Shared
Each storage class provisioner and PV type will have different requirements and parameters, as well as volumes, and we have already had a general overview of how they work and what we can use them for. Learning about specific storage classes and PV types will depend on your environment; you can learn more about each one of them by clicking on the following links:
In this article, we learned about what Kubernetes is, its components, and what are the advantages of using orchestration are. With this, identifying each of Kubernetes API objects, their purpose and their use cases should be easy. You should now be able to understand how the master nodes control the cluster and the scheduling of the containers in the worker nodes.
If you found this article useful, ‘ Hands-On Linux for Architects ’ should be helpful for you. With this book, you will be covering everything from Linux components and functionalities to hardware and software support, which will help you implementing and tuning effective Linux-based solutions. You will be taken through an overview of Linux design methodology and core concepts of designing a solution. If you’re a Linux system administrator, Linux support engineer, DevOps engineer, Linux consultant or anyone looking to learn or expand their knowledge in architecting, this book is for you.
Pod – dasar dari Kubernetes
Deployments
Kubernetes dan penyimpanan persisten
Volume
Volume Persisten, Klaim Volume Persisten, dan Kelas Penyimpanan