Saya ingin menemukan artikel saya di forum literatur yang sudah usang (usang) e-bane.net. Beberapa modul forum dinonaktifkan, dan saya tidak bisa mendapatkan daftar artikel dari penulisnya. Juga situs tidak diindeks oleh mesin pencari seperti Google, Yndex, dll.
Satu-satunya cara untuk menemukan semua artikel saya adalah dengan membuka halaman arsip situs (gbr.1). Maka saya harus memilih tahun dan bulan tertentu – mis. Januari 2013 (gbr.1). Dan kemudian saya harus memeriksa setiap artikel (gbr.2) apakah di awal tertulis nama panggilan saya – pa4080 (gbr.3). Tapi ada beberapa ribu artikel.
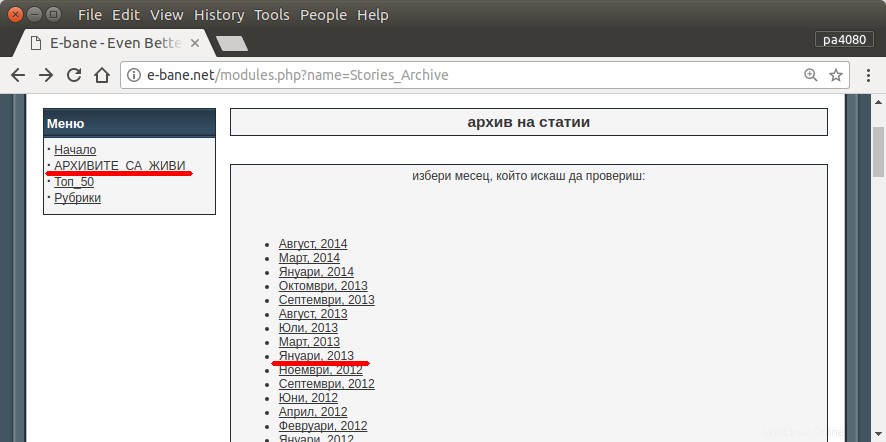
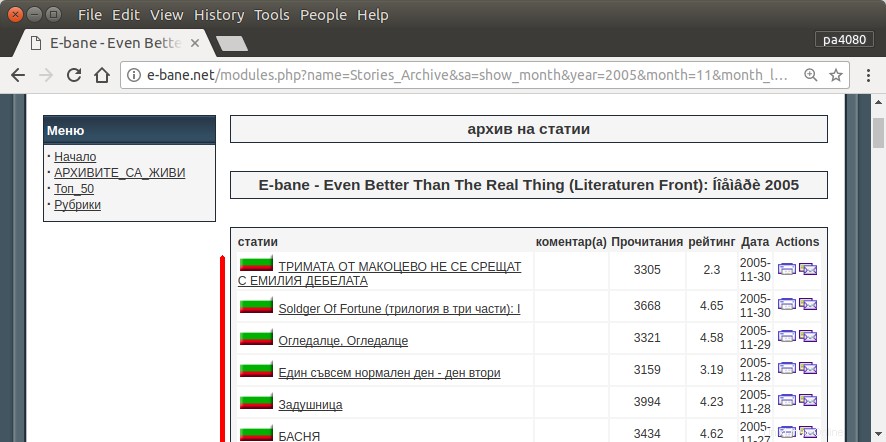
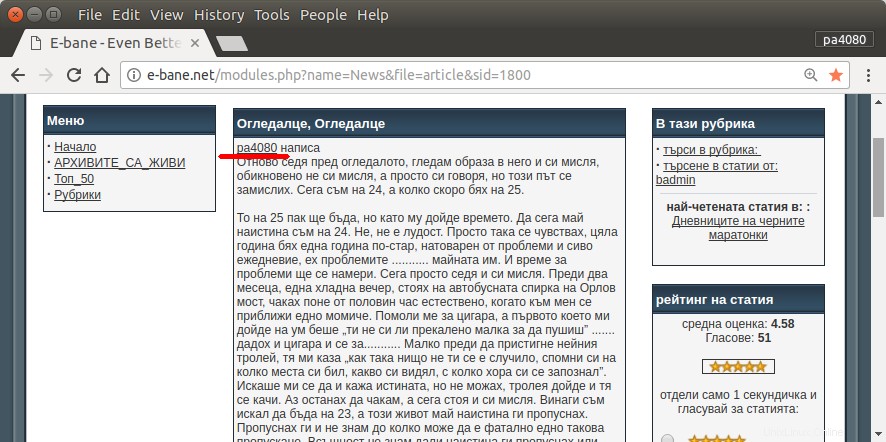
Saya telah membaca beberapa topik sebagai berikut, tetapi tidak ada solusi yang sesuai dengan kebutuhan saya:
- Web spider untuk Ubuntu
- Cara menulis laba-laba Web di sistem Linux
- Dapatkan daftar URL dari sebuah situs
Saya akan memposting solusi saya sendiri. Tapi bagi saya menarik:
Apakah ada cara yang lebih elegan untuk menyelesaikan tugas ini?
Jawaban yang Diterima:
script.py :
#!/usr/bin/python3
from urllib.parse import urljoin
import json
import bs4
import click
import aiohttp
import asyncio
import async_timeout
BASE_URL = 'http://e-bane.net'
async def fetch(session, url):
try:
with async_timeout.timeout(20):
async with session.get(url) as response:
return await response.text()
except asyncio.TimeoutError as e:
print('[{}]{}'.format('timeout error', url))
with async_timeout.timeout(20):
async with session.get(url) as response:
return await response.text()
async def get_result(user):
target_url = 'http://e-bane.net/modules.php?name=Stories_Archive'
res = []
async with aiohttp.ClientSession() as session:
html = await fetch(session, target_url)
html_soup = bs4.BeautifulSoup(html, 'html.parser')
date_module_links = parse_date_module_links(html_soup)
for dm_link in date_module_links:
html = await fetch(session, dm_link)
html_soup = bs4.BeautifulSoup(html, 'html.parser')
thread_links = parse_thread_links(html_soup)
print('[{}]{}'.format(len(thread_links), dm_link))
for t_link in thread_links:
thread_html = await fetch(session, t_link)
t_html_soup = bs4.BeautifulSoup(thread_html, 'html.parser')
if is_article_match(t_html_soup, user):
print('[v]{}'.format(t_link))
# to get main article, uncomment below code
# res.append(get_main_article(t_html_soup))
# code below is used to get thread link
res.append(t_link)
else:
print('[x]{}'.format(t_link))
return res
def parse_date_module_links(page):
a_tags = page.select('ul li a')
hrefs = a_tags = [x.get('href') for x in a_tags]
return [urljoin(BASE_URL, x) for x in hrefs]
def parse_thread_links(page):
a_tags = page.select('table table tr td > a')
hrefs = a_tags = [x.get('href') for x in a_tags]
# filter href with 'file=article'
valid_hrefs = [x for x in hrefs if 'file=article' in x]
return [urljoin(BASE_URL, x) for x in valid_hrefs]
def is_article_match(page, user):
main_article = get_main_article(page)
return main_article.text.startswith(user)
def get_main_article(page):
td_tags = page.select('table table td.row1')
td_tag = td_tags[4]
return td_tag
@click.command()
@click.argument('user')
@click.option('--output-filename', default='out.json', help='Output filename.')
def main(user, output_filename):
loop = asyncio.get_event_loop()
res = loop.run_until_complete(get_result(user))
# if you want to return main article, convert html soup into text
# text_res = [x.text for x in res]
# else just put res on text_res
text_res = res
with open(output_filename, 'w') as f:
json.dump(text_res, f)
if __name__ == '__main__':
main()
requirement.txt :
aiohttp>=2.3.7
beautifulsoup4>=4.6.0
click>=6.7
Ini adalah skrip versi python3 (diuji pada python3.5 di Ubuntu 17.10 ).
Cara menggunakan:
- Untuk menggunakannya, masukkan kedua kode tersebut ke dalam file. Sebagai contoh file kodenya adalah
script.pydan file paketnya adalahrequirement.txt. - Jalankan
pip install -r requirement.txt. - Jalankan skrip sebagai contoh
python3 script.py pa4080
Ini menggunakan beberapa perpustakaan:
- klik untuk pengurai argumen
- soup cantik untuk pengurai html
- aiohttp untuk pengunduh html
Hal-hal yang perlu diketahui untuk mengembangkan program lebih lanjut (selain dokumen paket yang diperlukan):
- pustaka python:asyncio, json, dan urllib.parse
- pemilih css (mdn web docs), juga beberapa html. lihat juga cara menggunakan css selector pada browser anda seperti artikel ini
Cara kerjanya:
- Pertama saya membuat pengunduh html sederhana. Ini adalah versi modifikasi dari contoh yang diberikan di aiohttp doc.
- Setelah itu buat parser baris perintah sederhana yang menerima nama pengguna dan nama file keluaran.
- Buat parser untuk tautan utas dan artikel utama. Menggunakan pdb dan manipulasi url sederhana akan berhasil.
- Gabungkan fungsi tersebut dan letakkan artikel utama di json, agar program lain dapat memprosesnya nanti.
Beberapa ide agar dapat dikembangkan lebih lanjut
- Buat subperintah lain yang menerima tautan modul tanggal:dapat dilakukan dengan memisahkan metode untuk mengurai modul tanggal ke fungsinya sendiri dan menggabungkannya dengan subperintah baru.
- Caching tautan modul tanggal:buat file json cache setelah mendapatkan tautan utas. jadi program tidak perlu mem-parsing link lagi. atau bahkan hanya men-cache seluruh artikel utama utas meskipun tidak cocok
Ini bukan jawaban yang paling elegan, tapi menurut saya ini lebih baik daripada menggunakan jawaban bash.
- Menggunakan Python, artinya bisa digunakan lintas platform.
- Instalasi sederhana, semua paket yang diperlukan dapat diinstal menggunakan pip
- Bisa dikembangkan lebih lanjut, program lebih mudah dibaca, lebih mudah dikembangkan.
- Ini melakukan pekerjaan yang sama seperti skrip bash hanya untuk 13 menit .