Pendahuluan
Apache Hive adalah sistem gudang data perusahaan yang digunakan untuk melakukan kueri, mengelola, dan menganalisis data yang disimpan dalam Sistem File Terdistribusi Hadoop.
Hive Query Language (HiveQL) memfasilitasi kueri dalam shell antarmuka baris perintah Hive. Hadoop dapat menggunakan HiveQL sebagai jembatan untuk berkomunikasi dengan sistem manajemen basis data relasional dan melakukan tugas berdasarkan perintah seperti SQL.
Panduan langsung ini menunjukkan kepada Anda cara menginstal Apache Hive di Ubuntu 20.04 .

Prasyarat
Apache Hive didasarkan pada Hadoop dan memerlukan kerangka kerja Hadoop yang berfungsi penuh.
Instal Apache Hive di Ubuntu
Untuk mengonfigurasi Apache Hive, pertama-tama Anda harus mengunduh dan meng-unzip Hive. Maka Anda perlu menyesuaikan file dan pengaturan berikut:
- Edit .bashrc berkas
- Edit hive-config.sh berkas
- Buat direktori Hive dalam HDFS
- Konfigurasikan hive-site.xml berkas
- Mulai Database Derby
Langkah 1:Unduh dan Untar Hive
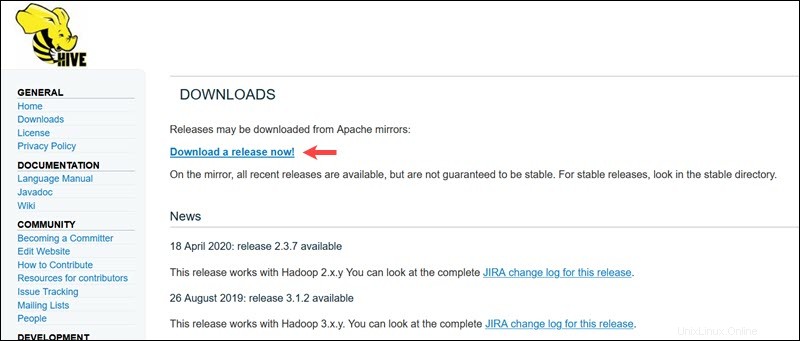
Kunjungi halaman unduh resmi Apache Hive dan tentukan versi Hive mana yang paling cocok untuk edisi Hadoop Anda. Setelah Anda menetapkan versi yang Anda butuhkan, pilih Unduh Rilis Sekarang! pilihan.
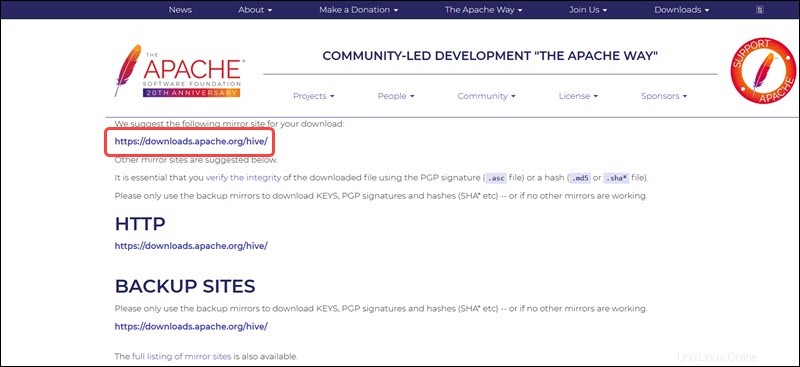
Tautan cermin pada halaman berikutnya mengarah ke direktori yang berisi paket tar Hive yang tersedia. Halaman ini juga memberikan petunjuk berguna tentang cara memvalidasi integritas file yang diambil dari situs mirror.
Sistem Ubuntu yang disajikan dalam panduan ini sudah memiliki Hadoop 3.2.1 diinstal. Versi Hadoop ini kompatibel dengan Hive 3.1.2 rilis.
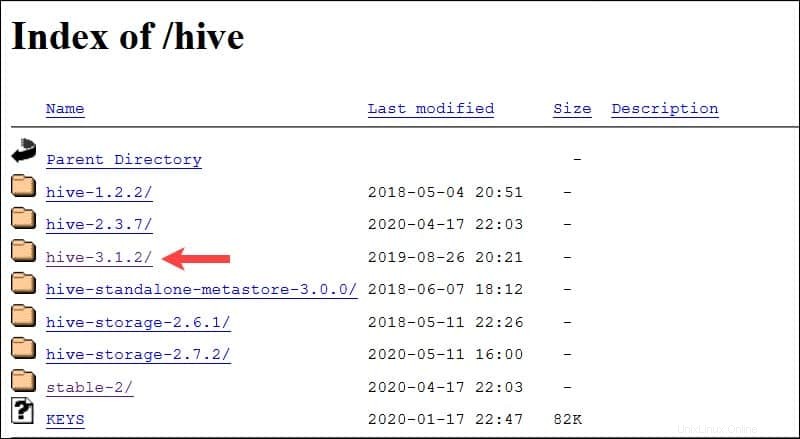
Pilih apache-hive-3.1.2-bin.tar.gz file untuk memulai proses pengunduhan.
Atau, akses baris perintah Ubuntu Anda dan unduh file Hive terkompresi menggunakan dan wget perintah diikuti dengan jalur unduhan:
wget https://downloads.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz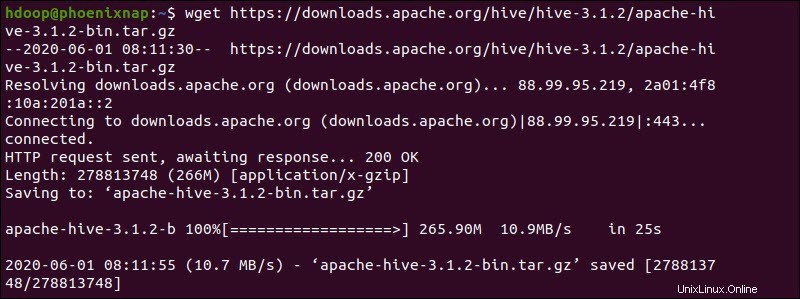
Setelah proses pengunduhan selesai, untar paket Hive terkompresi:
tar xzf apache-hive-3.1.2-bin.tar.gzFile biner Hive sekarang berada di apache-hive-3.1.2-bin direktori.

Langkah 2:Konfigurasi Variabel Lingkungan Hive (bashrc)
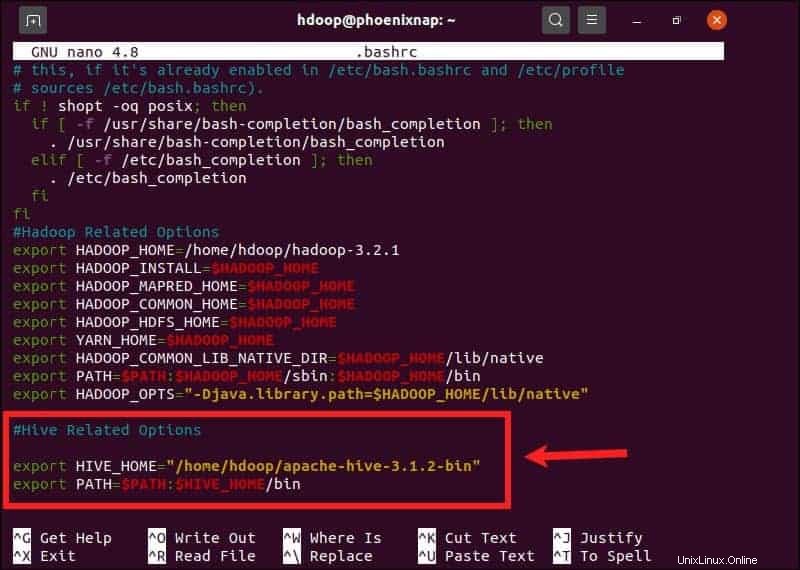
$HIVE_HOME variabel lingkungan perlu mengarahkan shell klien ke apache-hive-3.1.2-bin direktori. Edit .bashrc file konfigurasi shell menggunakan editor teks pilihan Anda (kami akan menggunakan nano):
sudo nano .bashrcTambahkan variabel lingkungan Hive berikut ke .bashrc berkas:
export HIVE_HOME= "home/hdoop/apache-hive-3.1.2-bin"
export PATH=$PATH:$HIVE_HOME/binVariabel lingkungan Hadoop terletak di dalam file yang sama.
Simpan dan keluar dari .bashrc file setelah Anda menambahkan variabel Hive. Terapkan perubahan ke lingkungan saat ini dengan perintah berikut:
source ~/.bashrcLangkah 3:Edit file hive-config.sh
Apache Hive harus dapat berinteraksi dengan Sistem File Terdistribusi Hadoop. Akses hive-config.sh file menggunakan $HIVE_HOME yang dibuat sebelumnya variabel:
sudo nano $HIVE_HOME/bin/hive-config.sh
Tambahkan HADOOP_HOME variabel dan path lengkap ke direktori Hadoop Anda:
export HADOOP_HOME=/home/hdoop/hadoop-3.2.1
Simpan hasil edit dan keluar dari hive-config.sh berkas.
Langkah 4:Buat Direktori Hive di HDFS
Buat dua direktori terpisah untuk menyimpan data di lapisan HDFS:
- Sementara, tmp direktori akan menyimpan hasil antara dari proses Hive.
- Gudang direktori akan menyimpan tabel terkait Hive.
Buat Direktori tmp
Buat tmp direktori dalam lapisan penyimpanan HDFS. Direktori ini akan menyimpan data perantara yang dikirimkan Hive ke HDFS:
hdfs dfs -mkdir /tmpTambahkan izin menulis dan mengeksekusi ke anggota grup tmp:
hdfs dfs -chmod g+w /tmpPeriksa apakah izin ditambahkan dengan benar:
hdfs dfs -ls /Outputnya mengonfirmasi bahwa pengguna sekarang memiliki izin menulis dan mengeksekusi.

Buat Direktori gudang
Buat gudang direktori dalam /user/hive/ direktori induk:
hdfs dfs -mkdir -p /user/hive/warehouseTambahkan tulis dan jalankan izin ke gudang anggota grup:
hdfs dfs -chmod g+w /user/hive/warehousePeriksa apakah izin ditambahkan dengan benar:
hdfs dfs -ls /user/hiveOutputnya mengonfirmasi bahwa pengguna sekarang memiliki izin menulis dan mengeksekusi.

Langkah 5:Konfigurasi File hive-site.xml (Opsional)
Distribusi Apache Hive berisi file konfigurasi template secara default. File template terletak di dalam conf Hi Hive direktori dan garis besar pengaturan Hive default.
Gunakan perintah berikut untuk menemukan file yang benar:
cd $HIVE_HOME/conf
Buat daftar file yang terdapat dalam folder menggunakan ls perintah.

Gunakan hive-default.xml.template untuk membuat hive-site.xml berkas:
cp hive-default.xml.template hive-site.xmlAkses hive-site.xml file menggunakan editor teks nano:
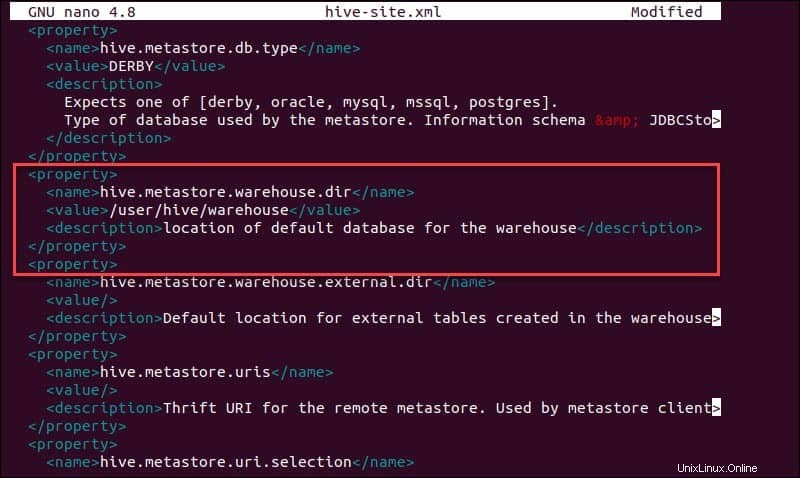
sudo nano hive-site.xmlMenggunakan Hive dalam mode yang berdiri sendiri daripada dalam kluster Apache Hadoop di kehidupan nyata adalah opsi yang aman bagi pendatang baru. Anda dapat mengonfigurasi sistem untuk menggunakan penyimpanan lokal alih-alih lapisan HDFS dengan menyetel hive.metastore.warehouse.dir nilai parameter ke lokasi gudang Hive Anda direktori.
Langkah 6:Memulai Basis Data Derby
Apache Hive menggunakan database Derby untuk menyimpan metadata. Memulai database Derby, dari Hive bin direktori menggunakan schematool perintah:
$HIVE_HOME/bin/schematool -dbType derby -initSchemaProsesnya bisa memakan waktu beberapa saat.
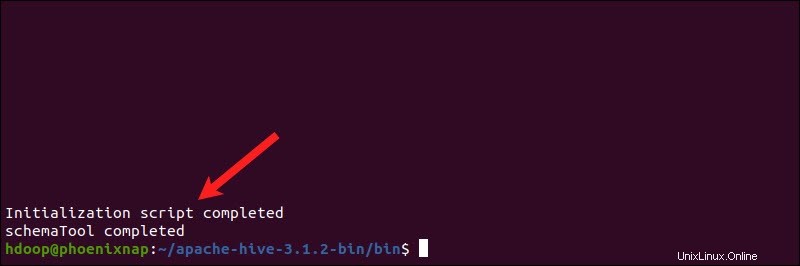
Derby adalah penyimpanan metadata default untuk Hive. Jika Anda berencana untuk menggunakan solusi database yang berbeda, seperti MySQL atau PostgreSQL, Anda dapat menentukan tipe database di hive-site.xml berkas.
Cara Memperbaiki Kesalahan Ketidakcocokan jambu biji di Hive
Jika database Derby tidak berhasil dimulai, Anda mungkin menerima kesalahan dengan konten berikut:
“Pengecualian di utas “utama” java.lang.NoSuchMethodError:com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V”
Kesalahan ini menunjukkan bahwa kemungkinan besar ada masalah ketidakcocokan antara Hadoop dan Hive jambu biji versi.
Temukan toples jambu biji file di Hive lib direktori:
ls $HIVE_HOME/lib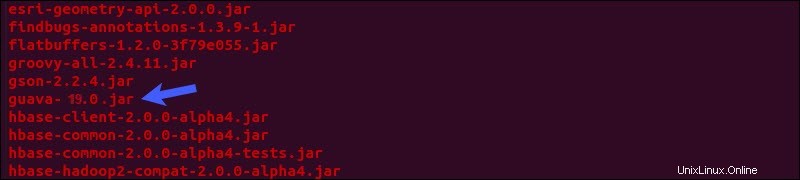
Temukan toples jambu biji file di Hadoop lib direktori juga:
ls $HADOOP_HOME/share/hadoop/hdfs/lib
Dua versi yang terdaftar tidak kompatibel dan menyebabkan kesalahan. Buang jambu biji . yang ada file dari Hive lib direktori:
rm $HIVE_HOME/lib/guava-19.0.jarSalin jambu biji file dari Hadoop lib direktori ke Hive lib direktori:
cp $HADOOP_HOME/share/hadoop/hdfs/lib/guava-27.0-jre.jar $HIVE_HOME/lib/
Gunakan schematool perintah sekali lagi untuk memulai database Derby:
$HIVE_HOME/bin/schematool -dbType derby -initSchemaLuncurkan Hive Client Shell di Ubuntu
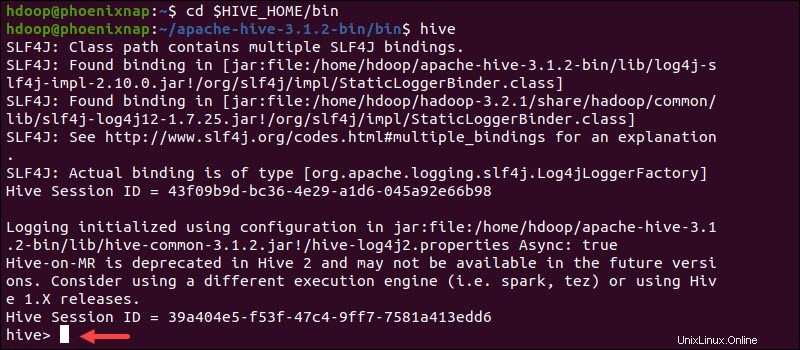
Mulai antarmuka baris perintah Hive menggunakan perintah berikut:
cd $HIVE_HOME/binhiveAnda sekarang dapat mengeluarkan perintah seperti SQL dan berinteraksi langsung dengan HDFS.