Pendahuluan
Spark Streaming adalah tambahan untuk Spark API untuk streaming langsung dan pemrosesan data skala besar. Alih-alih menangani sejumlah besar data mentah yang tidak terstruktur dan pembersihan setelahnya, Spark Streaming melakukan pemrosesan dan pengumpulan data hampir secara real-time.
Artikel ini menjelaskan apa itu Spark Streaming, cara kerjanya, dan memberikan contoh kasus penggunaan data streaming.

Prasyarat
- Apache Spark diinstal dan dikonfigurasi (Ikuti panduan kami:Cara menginstal Spark di Ubuntu, Cara menginstal Spark di Windows 10)
- Pengaturan lingkungan untuk Spark (kami akan menggunakan Pyspark di notebook Jupyter).
- Aliran data (kami akan menggunakan API Twitter).
- Perpustakaan python tweepy , json , dan soket untuk streaming data dari Twitter (gunakan pip untuk menginstalnya).
Apa itu Spark Streaming?
Spark Streaming adalah perpustakaan Spark untuk memproses aliran data yang hampir terus-menerus. Abstraksi inti adalah Aliran Terpisah dibuat oleh Spark DStream API untuk membagi data menjadi beberapa kelompok. DStream API didukung oleh Spark RDD (Resilient Distributed Datasets), yang memungkinkan integrasi tanpa hambatan dengan modul Apache Spark lainnya seperti Spark SQL dan MLlib.
Bisnis memanfaatkan kekuatan Spark Streaming dalam banyak kasus penggunaan yang berbeda:
- Streaming langsung ETL – Membersihkan dan menggabungkan data sebelum disimpan.
- Pembelajaran berkelanjutan – Terus memperbarui model pembelajaran mesin dengan informasi baru.
- Memicu peristiwa – Mendeteksi anomali secara real-time.
- Memperkaya data – Menambahkan informasi statistik ke data sebelum disimpan.
- Sesi kompleks langsung – Mengelompokkan aktivitas pengguna untuk dianalisis.
Pendekatan streaming memungkinkan analisis perilaku pelanggan yang lebih cepat, sistem rekomendasi yang lebih cepat, dan deteksi penipuan waktu nyata. Untuk insinyur, segala jenis anomali sensor dari perangkat IoT terlihat saat data dikumpulkan.
Aspek Spark Streaming
Spark Streaming mendukung beban kerja batch dan streaming secara native, yang memberikan peningkatan menarik pada umpan data. Aspek unik ini memenuhi persyaratan sistem streaming data modern berikut:
- Keseimbangan beban dinamis. Karena data terbagi menjadi batch mikro, kemacetan tidak lagi menjadi masalah. Arsitektur tradisional memproses satu catatan pada satu waktu, dan begitu partisi yang intens secara komputasi muncul, itu memblokir semua data lain pada simpul itu. Dengan Spark Streaming, tugas dibagi di antara pekerja, beberapa memproses lebih lama dan beberapa memproses tugas lebih pendek tergantung pada sumber daya yang tersedia.
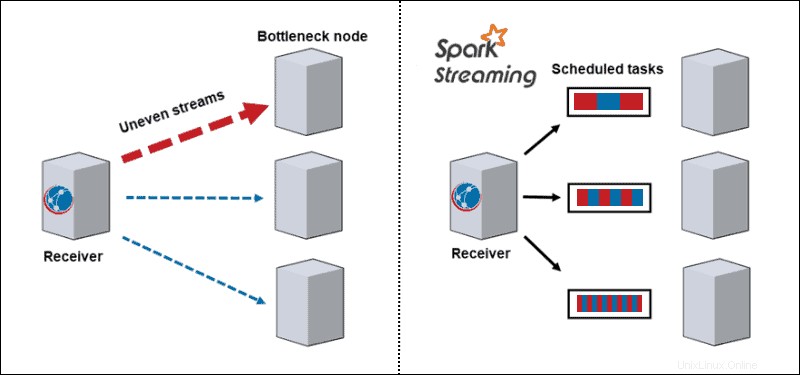
- Pemulihan kegagalan. Tugas yang gagal pada satu node mendiskritisasi dan mendistribusikan di antara pekerja lain. Saat node pekerja melakukan komputasi, straggler memiliki waktu untuk pulih.
- Analisis interaktif. DStreams adalah serangkaian RDD. Kumpulan data streaming yang disimpan dalam kueri memori pekerja secara interaktif.
- Analisis lanjutan. RDD yang dihasilkan oleh DStreams dikonversi menjadi DataFrames yang melakukan kueri dengan SQL dan diperluas ke pustaka, seperti MLlib, untuk membuat model pembelajaran mesin dan menerapkannya ke data streaming.
- Peningkatan kinerja streaming. Streaming dalam batch meningkatkan kinerja throughput, memanfaatkan latensi serendah beberapa ratus milidetik.
Kelebihan dan Kekurangan Spark Streaming
Setiap teknologi, termasuk Spark Streaming, memiliki kelebihan dan kekurangan:
| Pro | Kontra |
| Kinerja kecepatan luar biasa untuk tugas-tugas kompleks | Konsumsi memori besar |
| Toleransi kesalahan | Sulit digunakan, di-debug, dan dipelajari |
| Mudah diterapkan di kluster awan | Tidak didokumentasikan dengan baik, dan sumber belajar langka |
| Dukungan multibahasa | Visualisasi data buruk |
| Integrasi untuk kerangka kerja data besar seperti Cassandra dan MongoDB | Lambat dengan sedikit data |
| Kemampuan untuk menggabungkan beberapa jenis database | Beberapa algoritme pembelajaran mesin |
Bagaimana Spark Streaming Bekerja?
Spark Streaming berurusan dengan analitik berskala besar dan kompleks yang mendekati real-time. Pipa pemrosesan aliran terdistribusi melewati tiga langkah:
1. Terima streaming data dari sumber streaming langsung.
2. Proses data pada cluster secara paralel.
3. Keluaran data yang diproses ke dalam sistem.
Arsitektur Spark Streaming
Arsitektur inti dari Spark Streaming adalah dalam streaming kumpulan yang didiskritkan. Alih-alih melalui pipa pemrosesan aliran satu catatan pada satu waktu, batch mikro ditugaskan dan diproses secara dinamis. Oleh karena itu, transfer data ke pekerja berdasarkan sumber daya yang tersedia dan lokalitas.
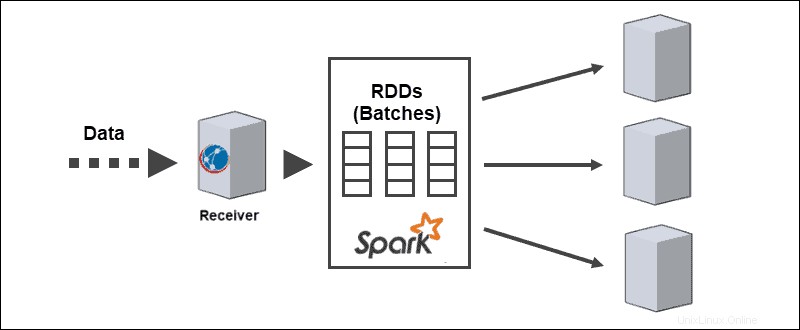
Ketika data tiba, penerima membaginya menjadi beberapa partisi RDD. Konversi ke RDD memungkinkan pemrosesan kumpulan menggunakan kode dan pustaka Spark karena RDD adalah abstraksi mendasar dari kumpulan data Spark.
Sumber Aliran Percikan
Aliran data memerlukan data yang diterima dari sumber. Spark streaming membagi sumber ini menjadi dua kategori:
- Sumber dasar. Sumber tersedia langsung di API inti Streaming, seperti koneksi soket dan sistem file yang kompatibel dengan HDFS
- Sumber lanjutan. Sumber memerlukan dependensi penautan dan tidak tersedia di API inti Streaming, seperti Kafka atau Kinesis.
Setiap input DStream terhubung ke penerima. Untuk aliran data paralel, membuat beberapa DStream akan menghasilkan banyak penerima juga.
Operasi Spark Streaming
Spark Streaming mencakup eksekusi berbagai jenis operasi:
1. Operasi transformasi memodifikasi data yang diterima dari input DStream, mirip dengan yang diterapkan pada RDD. Operasi transformasi mengevaluasi dengan malas dan tidak mengeksekusi sampai data mencapai output.
2. Operasi keluaran dorong DStreams ke sistem eksternal, seperti database atau sistem file. Pindah ke sistem eksternal memicu operasi transformasi.
3. DataFrame dan operasi SQL terjadi saat mengonversi RDD menjadi DataFrames dan mendaftarkannya sebagai tabel sementara untuk melakukan kueri.
4. Operasi MLlib digunakan untuk melakukan algoritme pembelajaran mesin, termasuk:
- Algoritme streaming berlaku untuk data langsung, seperti regresi linier streaming atau streaming k-means.
- Algoritme luring untuk mempelajari model offline dengan data historis dan menerapkan algoritme ke streaming data online.
Contoh Streaming Spark
Contoh streaming memiliki struktur berikut:
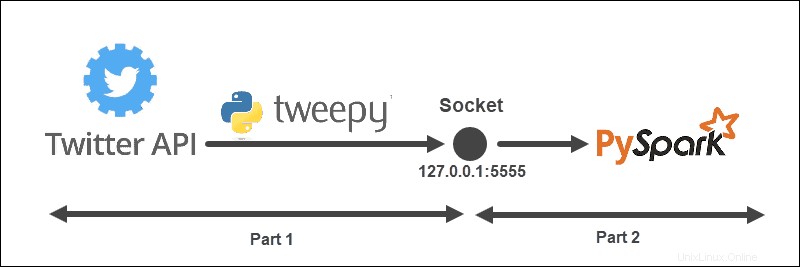
Arsitektur dibagi menjadi dua bagian dan dijalankan dari dua file:
- Jalankan file pertama untuk membuat koneksi dengan API Twitter dan membuat soket antara API Twitter dan Spark. Tetap jalankan file.
- Jalankan file kedua untuk meminta dan mulai mengalirkan data, mencetak Tweet yang diproses ke konsol. Data terkirim yang belum diproses tercetak di file pertama.
Buat Objek Pendengar Twitter
TweetListener objek mendengarkan Tweet dari aliran Twitter dengan StreamListener dari tweepy . Saat permintaan dibuat pada soket ke server (lokal), TweetListener mendengarkan data dan mengekstrak informasi Tweet (teks Tweet). Jika objek Tweet yang diperluas tersedia, TweetListener mengambil extended bidang, jika tidak teks lapangan diambil. Terakhir, pendengar menambahkan __end di akhir setiap Tweet. Langkah ini nantinya membantu kami memfilter aliran data di Spark.
import tweepy
import json
from tweepy.streaming import StreamListener
class TweetListener(StreamListener):
# tweet object listens for the tweets
def __init__(self, csocket):
self.client_socket = csocket
def on_data(self, data):
try:
# Load data
msg = json.loads(data)
# Read extended Tweet if available
if "extended_tweet" in msg:
# Add "__end" at the end of each Tweet
self.client_socket\
.send(str(msg['extended_tweet']['full_text']+" __end")\
.encode('utf-8'))
print(msg['extended_tweet']['full_text'])
# Else read Tweet text
else:
# Add "__end" at the end of each Tweet
self.client_socket\
.send(str(msg['text']+"__end")\
.encode('utf-8'))
print(msg['text'])
return True
except BaseException as e:
print("error on_data: %s" % str(e))
return True
def on_error(self, status):
print(status)
return TrueJika terjadi kesalahan dalam koneksi, konsol akan mencetak informasinya.
Kumpulkan Kredensial Pengembang Twitter
Portal Pengembang Twitter berisi kredensial OAuth untuk membuat koneksi API dengan Twitter. Informasinya ada di aplikasi Kunci dan token tab.
Untuk mengumpulkan data:
1. Buat Kunci &Rahasia API terletak di Kunci Konsumen bagian proyek dan simpan informasinya:
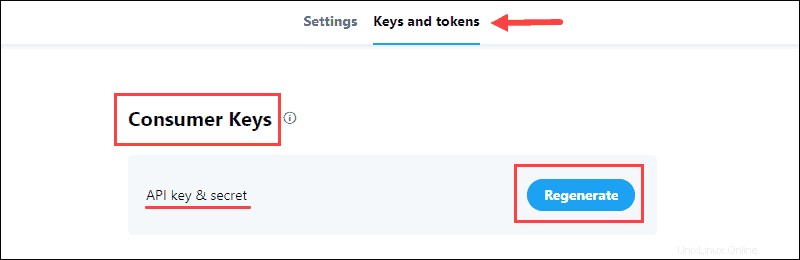
Kunci Konsumen verifikasi ke Twitter identitas Anda, seperti nama pengguna.
2. Buat Token &Rahasia Akses dari Token Otentikasi bagian dan simpan informasinya:
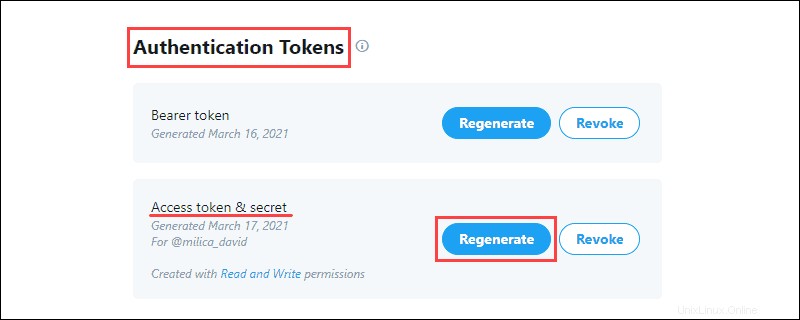
Token Otentikasi izinkan pengambilan data tertentu dari Twitter.
Kirim Data Dari API Twitter ke Soket
Dengan menggunakan kredensial Pengembang, isi API_KEY , API_SECRET , ACCESS_TOKEN , dan ACCESS_SECRET untuk mengakses API Twitter.
Fungsi sendData menjalankan aliran Twitter ketika klien membuat permintaan. Permintaan streaming pertama-tama diverifikasi, kemudian objek pendengar dibuat dan data streaming memfilter berdasarkan kata kunci dan bahasa.
Misalnya:
from tweepy import Stream
from tweepy import OAuthHandler
API_KEY = "api_key"
API_SECRET = "api_secret"
ACCESS_TOKEN = "access_token"
ACCESS_SECRET = "access_secret"
def sendData(c_socket, keyword):
print("Start sending data from Twitter to socket")
# Authentication based on the developer credentials from twitter
auth = OAuthHandler(API_KEY, API_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_SECRET)
# Send data from the Stream API
twitter_stream = Stream(auth, TweetListener(c_socket))
# Filter by keyword and language
twitter_stream.filter(track = keyword, languages=["en"])Buat Listening TCP Socket di Server
Bagian terakhir dari file pertama termasuk membuat soket pendengar di server lokal. Alamat dan port terikat dan mendengarkan koneksi dari klien Spark.
Misalnya:
import socket
if __name__ == "__main__":
# Create listening socket on server (local)
s = socket.socket()
# Host address and port
host = "127.0.0.1"
port = 5555
s.bind((host, port))
print("Socket is established")
# Server listens for connections
s.listen(4)
print("Socket is listening")
# Return the socket and the address of the client
c_socket, addr = s.accept()
print("Received request from: " + str(addr))
# Send data to client via socket for selected keyword
sendData(c_socket, keyword = ['covid'])
Setelah klien Spark membuat permintaan, soket dan alamat klien dicetak ke konsol. Kemudian, aliran data dikirim ke klien berdasarkan filter kata kunci yang dipilih.
Langkah ini menyimpulkan kode dalam file pertama. Menjalankannya mencetak informasi berikut:

Biarkan file tetap berjalan dan lanjutkan untuk membuat klien Spark.
Buat Penerima Spark DStream
Di file lain, buat konteks Spark dan konteks streaming lokal dengan interval batch satu detik. Klien membaca dari nama host dan soket port.
import findspark
findspark.init()
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
sc = SparkContext(appName="tweetStream")
# Create a local StreamingContext with batch interval of 1 second
ssc = StreamingContext(sc, 1)
# Create a DStream that conencts to hostname:port
lines = ssc.socketTextStream("127.0.0.1", 5555)Data Praproses
Pemrosesan awal RDD mencakup pemisahan jalur data yang diterima di mana __end muncul dan mengubah teks menjadi huruf kecil. Sepuluh elemen pertama dicetak ke konsol.
# Split Tweets
words = lines.flatMap(lambda s: s.lower().split("__end"))
# Print the first ten elements of each DStream RDD to the console
words.pprint()Setelah menjalankan kode, tidak ada yang terjadi karena evaluasinya malas. Perhitungan dimulai saat konteks streaming dimulai.
Mulai Konteks dan Komputasi Streaming
Memulai konteks streaming mengirimkan permintaan ke host. Tuan rumah mengirimkan data yang dikumpulkan dari Twitter kembali ke klien Spark, dan klien memproses data sebelumnya. Konsol kemudian mencetak hasilnya.
# Start computing
ssc.start()
# Wait for termination
ssc.awaitTermination()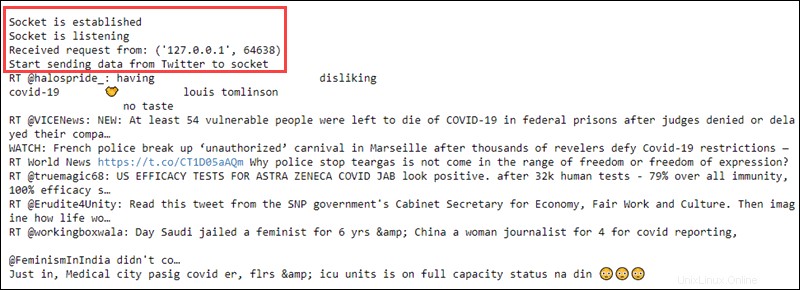
Memulai konteks streaming mencetak ke file pertama permintaan yang diterima dan mengalirkan teks data mentah:
File kedua membaca data setiap detik dari soket, dan pra-pemrosesan berlaku untuk data. Beberapa baris pertama kosong hingga koneksi dibuat:
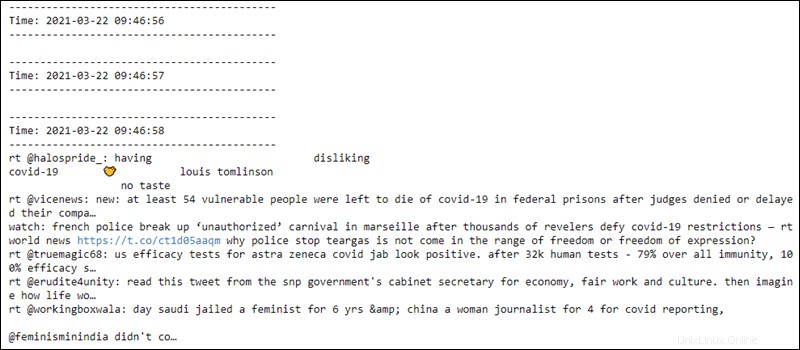
Konteks streaming siap dihentikan kapan saja.