Pendahuluan
MapReduce adalah modul pemrosesan dalam proyek Apache Hadoop. Hadoop adalah platform yang dibangun untuk menangani data besar menggunakan jaringan komputer untuk menyimpan dan memproses data.
Yang menarik dari Hadoop adalah dedicated server yang terjangkau sudah cukup untuk menjalankan sebuah cluster. Anda dapat menggunakan perangkat keras konsumen yang murah untuk menangani data Anda.
Hadoop sangat skalabel. Anda dapat memulai dengan serendah satu mesin, dan kemudian memperluas klaster Anda ke server dalam jumlah tak terbatas. Dua komponen default utama dari pustaka perangkat lunak ini adalah:
- MapReduce
- HDFS – Sistem file terdistribusi Hadoop
Pada artikel ini, kita akan berbicara tentang yang pertama dari dua modul. Anda akan belajar apa itu MapReduce, cara kerjanya, dan terminologi dasar Hadoop MapReduce .

Apa itu Hadoop MapReduce?
Model pemrograman Hadoop MapReduce memfasilitasi pemrosesan data besar yang disimpan di HDFS.
Dengan menggunakan sumber daya dari beberapa mesin yang saling berhubungan, MapReduce secara efektif menangani sejumlah besar data terstruktur dan tidak terstruktur .
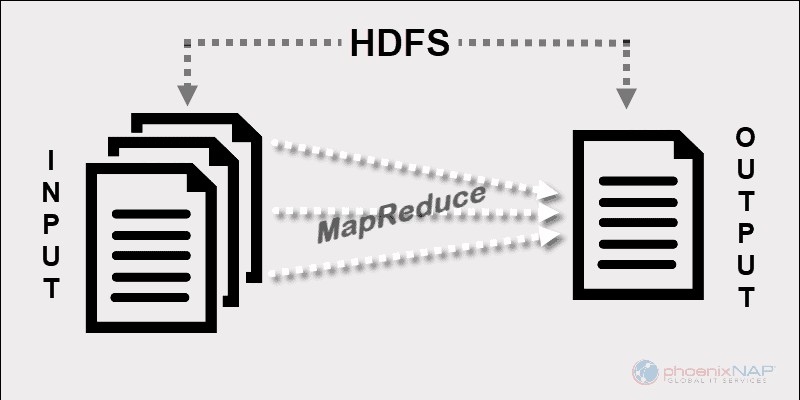
Sebelum Spark dan kerangka kerja modern lainnya, platform ini adalah satu-satunya pemain di bidang pemrosesan data besar terdistribusi.
MapReduce memberikan fragmen data di seluruh node dalam cluster Hadoop. Tujuannya adalah untuk membagi kumpulan data menjadi potongan-potongan dan menggunakan algoritma untuk memproses potongan-potongan itu pada waktu yang sama. Pemrosesan paralel pada beberapa mesin sangat meningkatkan kecepatan penanganan bahkan petabyte data.
Aplikasi Pemrosesan Data Terdistribusi
Kerangka kerja ini memungkinkan penulisan aplikasi untuk pemrosesan data terdistribusi. Biasanya, Java adalah yang digunakan sebagian besar programmer karena Hadoop didasarkan pada Java .
Namun, Anda dapat menulis aplikasi MapReduce dalam bahasa lain, seperti Ruby atau Python. Apa pun bahasa yang digunakan pengembang, tidak perlu khawatir tentang perangkat keras yang digunakan oleh cluster Hadoop.
Skalabilitas
Infrastruktur Hadoop dapat menggunakan server kelas perusahaan, serta perangkat keras komoditas. Pencipta MapReduce memiliki skalabilitas dalam pikiran. Tidak perlu menulis ulang aplikasi jika Anda menambahkan lebih banyak mesin. Cukup ubah penyiapan cluster, dan MapReduce terus bekerja tanpa gangguan.
Apa yang membuat MapReduce sangat efisien adalah ia berjalan pada node yang sama dengan HDFS. Penjadwal memberikan tugas ke node di mana data sudah berada. Beroperasi dengan cara ini meningkatkan throughput yang tersedia dalam sebuah cluster.
Cara Kerja MapReduce
Pada tingkat tinggi, MapReduce memecah data masukan menjadi beberapa bagian dan mendistribusikannya ke berbagai mesin.
Fragmen input terdiri dari pasangan nilai kunci. Tugas peta paralel memproses data yang dipotong pada mesin dalam sebuah cluster. Keluaran pemetaan kemudian berfungsi sebagai masukan untuk tahap reduksi. Tugas pengurangan menggabungkan hasilnya menjadi keluaran pasangan nilai kunci tertentu dan menulis data ke HDFS.
Sistem File Terdistribusi Hadoop biasanya berjalan pada set mesin yang sama dengan perangkat lunak MapReduce. Saat framework menjalankan tugas pada node yang juga menyimpan data, waktu untuk menyelesaikan tugas berkurang secara signifikan.
Terminologi Dasar Hadoop MapReduce
Seperti yang kami sebutkan di atas, MapReduce adalah lapisan pemrosesan di lingkungan Hadoop. MapReduce bekerja pada tugas-tugas yang berhubungan dengan pekerjaan. Idenya adalah untuk menangani satu permintaan besar dengan membaginya menjadi unit yang lebih kecil.
JobTracker dan TaskTracker
Pada hari-hari awal Hadoop (versi 1), JobTracker dan Pelacak Tugas daemon menjalankan operasi di MapReduce. Pada saat itu, cluster Hadoop hanya dapat mendukung aplikasi MapReduce.
Seorang Pelacak Pekerjaan mengontrol distribusi permintaan aplikasi ke sumber daya komputasi dalam sebuah cluster. Karena memonitor eksekusi dan status MapReduce, ia berada di master node.
Pelacak Tugas memproses permintaan yang datang dari JobTracker. Semua pelacak tugas didistribusikan di seluruh node slave dalam cluster Hadoop.
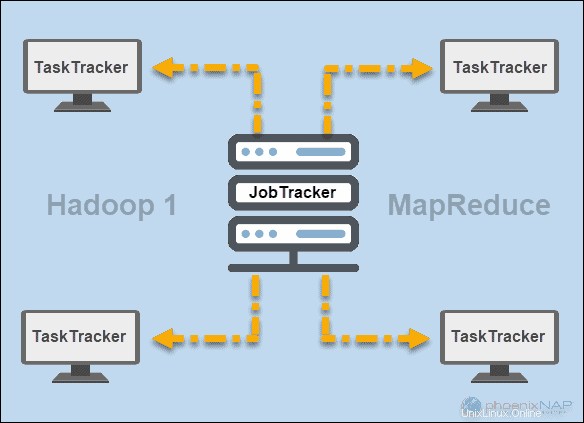
BENANG
Kemudian di Hadoop versi 2 dan di atasnya, YARN menjadi pengelola sumber daya dan penjadwalan utama. Oleh karena itu namanya Yet Another Resource Manager . Benang juga bekerja dengan kerangka kerja lain untuk pemrosesan terdistribusi dalam kluster Hadoop.
Pekerjaan MapReduce
Pekerjaan MapReduce adalah unit kerja teratas dalam proses MapReduce. Ini adalah tugas yang harus diselesaikan oleh proses Map and Reduce. Sebuah pekerjaan dibagi menjadi tugas-tugas yang lebih kecil di atas sekelompok mesin untuk eksekusi yang lebih cepat.
Tugas harus cukup besar untuk membenarkan waktu penanganan tugas. Jika Anda membagi pekerjaan menjadi segmen-segmen kecil yang tidak biasa, total waktu untuk mempersiapkan pembagian dan membuat tugas mungkin lebih besar daripada waktu yang dibutuhkan untuk menghasilkan keluaran pekerjaan yang sebenarnya.
Tugas MapReduce
Pekerjaan MapReduce memiliki dua jenis tugas.
Tugas Peta adalah satu contoh aplikasi MapReduce. Tugas ini menentukan record mana yang akan diproses dari blok data. Data input dibagi dan dianalisis, secara paralel, pada sumber daya komputasi yang ditetapkan dalam cluster Hadoop. Langkah tugas MapReduce ini mempersiapkan output pasangan
Kurangi Tugas memproses output dari tugas peta. Mirip dengan tahap peta, semua tugas pengurangan terjadi pada saat yang sama, dan mereka bekerja secara independen. Data dikumpulkan dan digabungkan untuk menghasilkan keluaran yang diinginkan. Hasil akhirnya adalah kumpulan pasangan
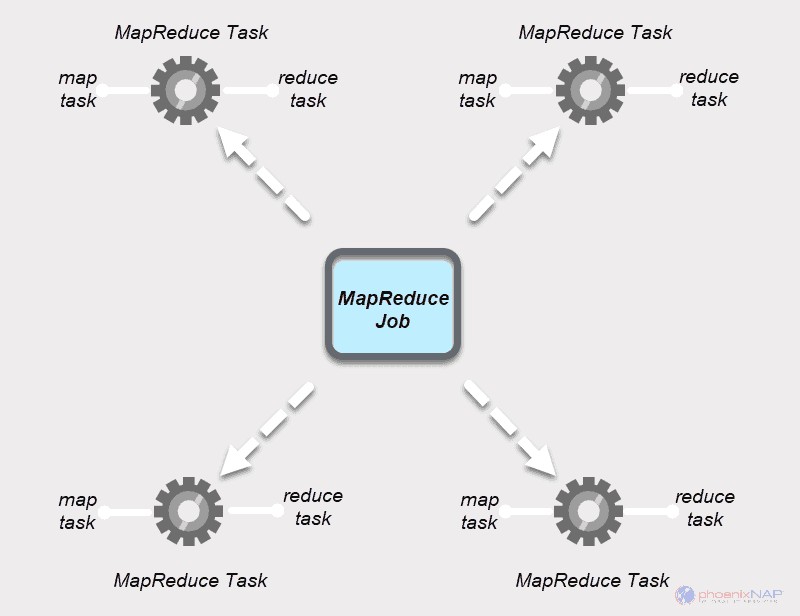
Tahap Peta dan Perkecil masing-masing memiliki dua bagian.
Peta bagian pertama berurusan dengan pemisahan dari data input yang ditugaskan untuk tugas peta individu. Kemudian, pemetaan fungsi membuat output dalam bentuk pasangan nilai kunci perantara.
Kurangi stage memiliki langkah shuffle dan reduce. Mengacak mengambil output peta dan membuat daftar pasangan kunci-nilai-daftar terkait. Kemudian, mengurangi menggabungkan hasil pengacakan untuk menghasilkan keluaran akhir yang diminta oleh aplikasi MapReduce.
Bagaimana Hadoop Memetakan dan Mengurangi Bekerja Bersama
Seperti namanya, MapReduce bekerja dengan memproses data input dalam dua tahap – Peta dan Kurangi . Untuk mendemonstrasikan hal ini, kita akan menggunakan contoh sederhana dengan menghitung jumlah kemunculan kata dalam setiap dokumen.
Hasil akhir yang kita cari adalah:Berapa kali total kata Apache, Hadoop, Class, dan Track muncul di semua dokumen .
Untuk tujuan ilustrasi, lingkungan contoh terdiri dari tiga node. Input berisi enam dokumen yang didistribusikan di seluruh cluster. Kami akan membuatnya tetap sederhana di sini, tetapi dalam keadaan nyata, tidak ada batasan. Anda dapat memiliki ribuan server dan miliaran dokumen.
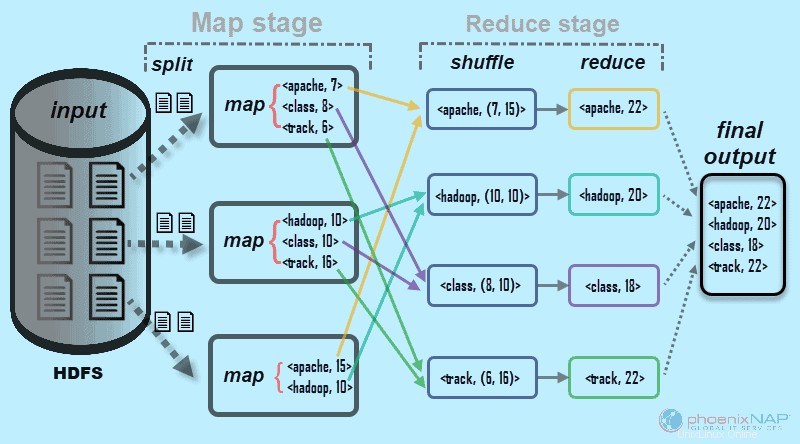
1. Pertama, di tahap peta , data input (keenam dokumen) dibagi dan didistribusikan di seluruh cluster (tiga server). Dalam hal ini, setiap tugas peta bekerja pada pemisahan yang berisi dua dokumen. Selama pemetaan, tidak ada komunikasi antara node. Mereka tampil secara independen.
2. Kemudian, tugas peta membuat
Proses ini dilakukan dalam tugas paralel pada semua node untuk semua dokumen dan memberikan output yang unik.
3. Setelah pemisahan input dan pemetaan selesai, output dari setiap tugas peta diacak . Ini adalah langkah pertama dari Reduce stage . Karena kami mencari frekuensi kemunculan untuk empat kata, ada empat tugas Reduce paralel. Tugas pengurangan dapat berjalan pada node yang sama dengan tugas peta, atau mereka dapat berjalan pada node lain.
Langkah mengacak memastikan kunci Apache, Hadoop, Kelas, dan Lacak diurutkan untuk langkah reduksi. Proses ini mengelompokkan nilai berdasarkan kunci dalam bentuk
4. Di langkah kurangi dari tahap Reduce, masing-masing dari empat tugas memproses
Dalam contoh kami dari diagram, tugas pengurangan mendapatkan hasil individual berikut:
5. Terakhir, data di Tahap Kurangi dikelompokkan menjadi satu keluaran. MapReduce sekarang menunjukkan kepada kita berapa kali kata-kata Apache, Hadoop, Class, dan lacak muncul di semua dokumen. Data agregat, secara default, disimpan dalam HDFS.
Contoh yang kami gunakan di sini adalah yang dasar. MapReduce melakukan tugas yang jauh lebih rumit.
Beberapa kasus penggunaan meliputi:
- Mengubah log Apache menjadi nilai yang dipisahkan tab (TSV).
- Menentukan jumlah alamat IP unik dalam data weblog.
- Melakukan pemodelan dan analisis statistik yang kompleks.
- Menjalankan algoritme pembelajaran mesin menggunakan kerangka kerja yang berbeda, seperti Mahout.
Bagaimana Partisi Hadoop Memetakan Data Input
Partisi bertanggung jawab untuk memproses output peta. Setelah MapReduce membagi data menjadi beberapa bagian dan menugaskannya untuk memetakan tugas, kerangka kerja mempartisi data nilai kunci. Proses ini berlangsung sebelum keluaran tugas mapper akhir dihasilkan.
MapReduce partisi dan urutkan output berdasarkan kuncinya. Di sini, semua nilai untuk masing-masing kunci dikelompokkan, dan pembuat partisi membuat daftar yang berisi nilai yang terkait dengan setiap kunci. Dengan mengirimkan semua nilai dari satu kunci ke peredam yang sama, partisi memastikan distribusi yang sama dari output peta ke peredam.
Partisi default dikonfigurasi dengan baik untuk banyak kasus penggunaan, tetapi Anda dapat mengkonfigurasi ulang bagaimana data partisi MapReduce.
Jika Anda menggunakan partisi khusus, pastikan ukuran data yang disiapkan untuk setiap peredam kira-kira sama. Saat Anda mempartisi data secara tidak merata, satu tugas pengurangan bisa memakan waktu lebih lama untuk diselesaikan. Ini akan memperlambat seluruh pekerjaan MapReduce.