Pendahuluan
MySQL adalah aplikasi database yang menyimpan data dalam baris dan kolom dari tabel yang berbeda untuk menghindari duplikasi. Nilai duplikat dapat terjadi, yang dapat memengaruhi kinerja MySQL.
Panduan ini akan menunjukkan cara menemukan nilai duplikat dalam database MySQL .

Prasyarat
- Instalasi MySQL yang sudah ada
- Kredensial akun pengguna root untuk MySQL
- Jendela baris perintah / terminal
Menyiapkan Tabel Contoh (Opsional)
Langkah ini akan membantu Anda membuat tabel sampel untuk dikerjakan. Jika Anda sudah memiliki database untuk dikerjakan, lewati ke bagian berikutnya.
Buka jendela terminal, dan alihkan ke shell MySQL:
mysql –u root –pBuat daftar database yang ada:
SHOW databases;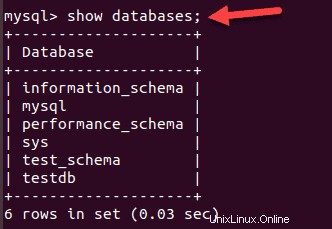
Buat database baru yang belum ada:
CREATE database sampledb;Pilih tabel yang baru saja Anda buat:
USE sampledb;Buat tabel baru dengan kolom berikut:
CREATE TABLE dbtable (
id INT PRIMARY KEY AUTO_INCREMENT,
date_x VARCHAR(10) NOT NULL,
system_x VARCHAR(50) NOT NULL,
test VARCHAR(50) NOT NULL
);Sisipkan baris ke dalam tabel:
INSERT INTO dbtable (date_x,system_x,test)
VALUES ('01/03/2020','system1','hard_drive'),
('01/04/2020','system2','memory'),
('01/10/2020','system2','processor'),
('01/14/2020','system3','hard drive'),
('01/10/2020','system2','processor'),
('01/20/2020','system4','hard drive'),
('01/24/2020','system5','memory'),
('01/29/2020','system6','hard drive'),
('02/02/2020','system7','motherboard'),
('02/04/2020','system8','graphics card'),
('02/02/2020','system7','motherboard'),
('02/08/2020','system9','hard drive');Jalankan kueri SQL berikut:
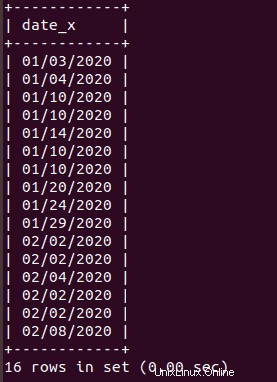
SELECT * FROM dbtable
ORDER BY date_x;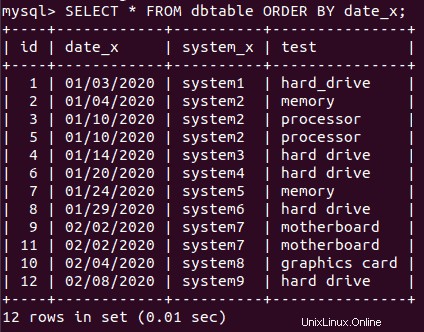
Menemukan Duplikat di MySQL
Temukan Nilai Duplikat dalam Satu Kolom
Gunakan GROUP BY berfungsi untuk mengidentifikasi semua entri identik dalam satu kolom. Tindak lanjuti dengan COUNT() HAVING berfungsi untuk membuat daftar semua grup dengan lebih dari satu entri.
SELECT
test,
COUNT(test)
FROM
dbtable
GROUP BY test
HAVING COUNT(test) > 1;
Temukan Nilai Duplikat di Beberapa Kolom
Anda mungkin ingin membuat daftar duplikat yang sama persis, dengan informasi yang sama di ketiga kolom.
SELECT
date_x, COUNT(date_x),
system_x, COUNT(system_x),
test, COUNT(test)
FROM
dbtable
GROUP BY
date_x,
system_x,
test
HAVING COUNT(date_x)>1
AND COUNT(system_x)>1
AND COUNT(test)>1;

Kueri ini bekerja dengan memilih dan menguji >1 kondisi pada ketiga kolom. Hasilnya adalah hanya baris dengan nilai duplikat yang dikembalikan dalam output.
Periksa Duplikat di Beberapa Tabel Dengan INNER JOIN
Gunakan fungsi INNER JOIN untuk menemukan duplikat yang ada di beberapa tabel.
Contoh sintaks untuk INNER JOIN fungsinya terlihat seperti ini:
SELECT column_name
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column name;
Untuk menguji contoh ini, Anda memerlukan tabel kedua yang berisi beberapa informasi yang diduplikasi dari sampledb tabel yang kita buat di atas.
SELECT dbtable.date_x
FROM dbtable
INNER JOIN new_table
ON dbtable.date_x = new_table.date_x;
Ini akan menampilkan tanggal duplikat yang ada antara data yang ada dan tabel_baru .